



































Runway Intelligence is OpenMetal’s executive insight series for late-stage startups and their investors, exploring how cloud economics, infrastructure design, and operational strategy shape valuation, margins, and time to exit.
DDR5 memory prices have risen 307% since September 2025. NAND flash storage jumped 33–38% quarter-over-quarter. Dell announced 15–20% server price increases in December 2025, with Lenovo following in January 2026. And these numbers are about to hit your cloud bill, if they haven’t yet..
Cloud providers typically lag three to six months between procurement cost changes and retail pricing adjustments. That puts the repricing window squarely in Q2–Q3 2026. If your runway model continues to assume stable infrastructure costs, you’re forecasting with outdated inputs.
This article introduces a framework we call Infrastructure Duration Risk — a way to think about how exposed your company’s runway is to infrastructure cost volatility. We’ll walk through the structural forces driving repricing, show you the math on runway erosion, and give you a practical approach to reducing exposure without abandoning cloud flexibility.
Key Takeaways
- Infrastructure is repricing. DDR5 memory up 307%, server prices up 15–20%, energy costs surging — and hyperscalers haven’t passed through the full increase yet. The repricing window is Q2–Q3 2026.
- Most runway models were not accounting for this variable. A 20% infrastructure cost increase can erase two to three months of runway for a company spending $180K/month on cloud.
- Infrastructure Duration Risk is measurable. Assess your variable-rate exposure, cost concentration, contract terms, and workload elasticity. If you’re above 60% variable with a single provider on month-to-month terms, your exposure is high.
- The hedge is a fixed-cost baseline. Move steady-state workloads to fixed-cost infrastructure. Keep elastic cloud for what genuinely needs variable capacity. Model +15% and +25% cost scenarios in your burn forecast.
- This is a board-level conversation. Infrastructure cost volatility is a financial exposure, not just an engineering concern. And for PE/VC portfolios, it’s a position that compounds across every company.
The Infrastructure Repricing Cycle Is Already Underway
Four structural forces are converging to push infrastructure costs upward. None of them are temporary.
Silicon demand is outpacing supply.
AI training and inference workloads have consumed the capacity that general compute previously relied on. TSMC’s CoWoS advanced packaging — the bottleneck for AI accelerators — is oversubscribed through at least 2026, with NVIDIA reportedly securing over 70% of capacity for its Blackwell GPUs. High Bandwidth Memory (HBM) is fully allocated through 2026, with lead times of six to twelve months and pricing increases in the high-teens to low-twenties percent range for 2026 contracts, according to Deloitte’s 2026 Semiconductor Industry Outlook.
Energy costs are climbing in key data center markets.
The PJM Interconnection’s 2025–2026 capacity auction clearing price increased 833% from the previous year. Wholesale electricity near data center clusters costs as much as 267% more than it did five years ago. In Northern Virginia — home to the world’s densest concentration of data centers — Dominion Energy proposed its first base-rate increase since 1992, adding $8.51 per month per customer in 2026. PJM projects 32 GW of peak load growth between 2024 and 2030, with data centers responsible for 94% of that increase.
Supply chain shifts are adding cost pressure.
Geopolitical tensions and tariff implications on semiconductor procurement are raising the floor on hardware costs. Dell’s 15–20% server price increase, reported in SoftwareSeni’s infrastructure cost analysis, reflects these upstream pressures. OVH’s CEO has forecast 5–10% increases for the broader industry between April and September 2026, with identical servers projected to cost 15–35% more by December.
AI workload pressure is squeezing general-purpose capacity.
Hyperscaler capex is forecast to exceed $600 billion in 2026 — a 36% increase over 2025. That capital is directed at AI infrastructure. General-purpose compute isn’t getting the same investment priority, which means capacity constraints and pricing pressure for non-AI workloads.
What happens to your burn rate when these forces reach your monthly invoice?
Most Runway Models Are Built on a Dangerous Assumption
Most financial models treat infrastructure costs as a known quantity — either stable or declining over time (in per unit costs). This assumption made sense in an era of consistent Moore’s Law gains and aggressive hyperscaler price competition. It no longer holds.
According to Flexera’s 2025 State of the Cloud Report, cloud spend is expected to increase 28% year-over-year, while 84% of organizations cite managing cloud spend as their top challenge. Cloud budgets are already exceeding limits by 17%. These are averages. For startups with infrastructure-heavy products — AI features, real-time data processing, media workloads — the exposure is higher.
Here’s what a repricing scenario looks like for a late-stage startup:
Consider a Series B SaaS company spending $180,000 per month on hyperscaler infrastructure, with $3.6 million in the bank and a projected 18 months of runway at current burn. Now model a 20% infrastructure cost increase — conservative, given the data above. Monthly cloud spend jumps to $216,000. That’s an additional $36,000 per month, or $432,000 per year of unplanned burn. Runway drops from 18 months to roughly 15.5 months. Two and a half months of runway evaporated — without a single new hire, product change, or strategic decision.
At a 25% increase, that same company loses over three months of runway. If the fundraising window was tight to begin with, this is the difference between closing a round on your terms and closing it under duress.
We are calling this the Infrastructure Duration Risk.

Defining Infrastructure Duration Risk
In fixed-income finance, duration risk measures how sensitive a bond portfolio is to interest rate changes. A portfolio with longer duration swings more in value when rates move. The concept translates directly to infrastructure economics.
Infrastructure Duration Risk is the degree to which a company’s cash runway is sensitive to changes in infrastructure pricing. The higher the proportion of variable-rate cloud spend relative to total burn, the greater the duration risk. A company spending 40% of its monthly burn on usage-based cloud pricing has substantially more exposure than one spending 15% on fixed-cost dedicated infrastructure.
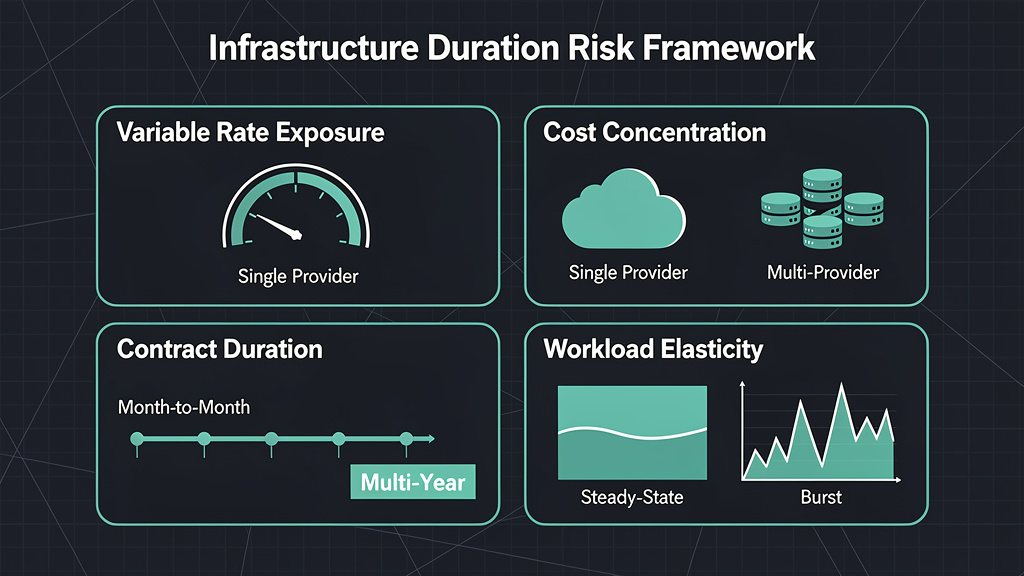
You can assess your own duration risk in ten minutes by evaluating four components:
- Variable Rate Exposure (%): What share of your infrastructure spend is on usage-based, variable-rate pricing? Higher percentages mean higher exposure to repricing
- Cost Concentration: How concentrated is your spend with a single provider or region? Single-provider dependency amplifies repricing impact
- Contract Duration: Are you on month-to-month billing, or do you have committed spend agreements that lock in rates? Month-to-month means full repricing exposure
- Workload Elasticity: Which workloads genuinely need elastic scaling versus steady-state compute? Most companies overestimate how much of their workload actually requires variable capacity
This isn’t a spreadsheet exercise. It’s a mental model. If your variable-rate exposure is above 60%, your cost concentration is with one hyperscaler, and you’re on month-to-month terms, your infrastructure duration risk is high.
Reducing Duration Risk Without Losing Flexibility
The fix isn’t moving everything off the cloud. One long-term solution is designing a predictable, fixed-cost infrastructure baseline for workloads that run at steady state — and keeping elastic cloud for what genuinely needs it.
Here are five steps:
- Audit your workload profile. Separate steady-state workloads (databases, core application servers, persistent storage) from genuinely elastic ones (CI/CD pipelines, batch processing, seasonal traffic spikes). Most companies find that 60–80% of their compute runs at steady state
- Establish a fixed-cost baseline. Move steady-state workloads to fixed-cost infrastructure — hosted private cloud, bare metal, or reserved instances with committed spend. This is your “fixed-rate” position against infrastructure repricing
- Keep elastic capacity for what needs it. Variable cloud remains the right tool for burst, experimentation, and geographic expansion. The goal is right-sizing your variable exposure, not eliminating it
- Model infrastructure scenarios in your runway forecast. Add a +15% and +25% infrastructure cost column to your burn model. If either scenario materially changes your fundraising timeline, you have duration risk that needs addressing now
- Negotiate or lock pricing where possible. Reserved instances, enterprise agreements, or fixed-cost providers all reduce your exposure. As Andreessen Horowitz argued in The Cost of Cloud, a Trillion Dollar Paradox, infrastructure spend should be a “first-class metric” — not an afterthought on the P&L
There’s a reason 86% of CIOs now plan to move some workloads from public cloud back to private or on-premises infrastructure, according to recent cloud repatriation data. The economics have shifted. The question is whether you’re adjusting your model before or after the repricing hits your invoice.
The Board Conversation Founders Should Be Having
Infrastructure cost volatility isn’t an engineering problem. It’s a financial exposure that belongs in board materials next to headcount planning and sales forecasts.
CFOs and board members should be asking two questions: What is our infrastructure duration risk? And what happens to our runway if cloud costs increase 20% before our next raise?
For PE/VC operating partners managing portfolios, this exposure compounds. Infrastructure Duration Risk isn’t a single-company issue — it’s a portfolio-level position. Every portfolio company running primarily on variable-rate hyperscaler infrastructure carries the same directional exposure. When repricing arrives, it arrives for all of them simultaneously.
The companies that will hold an operational advantage in a repricing environment are the ones that treat infrastructure like a financial instrument. They hedge exposure by diversifying providers. They lock in predictable baselines for steady-state workloads. They model cost volatility in their forecasts instead of assuming it away.
Infrastructure is repricing. The data is clear, and the forces are structural. The only variable is whether you account for it now or explain it to your board later.