



































Please note, this post is documenting a deployment in process of becoming a standard. It does not form our final opinion or system we will deploy at this time.
In this article
Delta Lake – Private/On-Prem Deployment Architecture
In order to support customer requests, we are creating a standard open source only install of Delta Lake, Spark, and optionally, supporting systems like MLflow. This means we will only be installing and depending on bare metal servers, VMs on OpenStack, or open source cloud storage systems. This is done on our bare metal dedicated servers, our hosted private cloud powered by OpenStack, and our Ceph storage clusters in our data centers. This should translate easily though to colocation or an on-prem Delta Lake deployment.
Note: Apache Spark, Delta Lake, and MLflow are trademarks of their respective open source umbrella Foundations.
This information is highly condensed as there is great documentation on Delta.io on what it is and why you would use it. Also, based on what part of big data you come from you can stay within the ecosystem you like with Delta Lake.
Ceph Storage Cluster – Major Component 1 of a Production Delta Lake
First key area is a resilient and scalable storage layer. In a data lake, storage is the underlying champion of all things that are going to happen. In Delta you will hear reference to 3 layers that help you visualize how data is stored in the lake:
- Bronze Layer – raw data in various formats including time based logs and typically tagged in a way that ties back to the original source
- Silver Layer – processed into a semi-structured format via ETL (Extract, Transform, Load) or ELT (Extract, Load and Transform simultaneously) methods
- Gold Layer – data is now stored in systems that allow for rapid and easy querying. Generally there is not a lot of writing or transforming data. Data is being used for customer views, automated pipeline decisions, visualizations, and other business intelligence.
And guess what? All these layers require storage and lots of it. Delta Lake has been built and refined over years to leverage object storage. OpenMetal provides private Ceph storage clusters that have key attributes needed by Delta Lake.
- Highly efficient erasure coding keeps costs down
- Compression on the fly of up to 15:1 on text and similar file types dramatically reduces used storage capacity
- Highly stable, industry standard open source protects from cost creep
- Meets Delta Lake API Requirements out of the Box
Example 2.7PiB Cluster
(before Compression)
Bare Metal Spark Cluster – Component 2 of a Production Delta Lake
Second core component is a Spark cluster running on servers, bare metal or VMs, specifically selected to fit the RAM and CPU needs of your Spark jobs. OpenMetal can support either approach. Either a Yarn or Kubernetes approach is supported. Mesos is now deprecated.
![]()
RAM and Drive Count
| Base RAM | Max RAM | Drives | |
|---|---|---|---|
| Large | 512GB | 1TB | Up to 6 |
| XL | 1TB | 1TB | Up to 10 |
| XXL | 1TB | 2TB | Up to 24 |
- 20gpbs network is standard
- 6.4TB NVMe Micron 7450 Max are standard for big data
Clock Speeds and Cores
| Version | Large | XL/XXL |
|---|---|---|
| V2.1 | Intel Xeon Silver 4314 – 32C/64T – 2.4/3.4Ghz | Intel Xeon Gold 6338 – 64C/128T – 2.0/3.2Ghz |
| V3.0 | Intel Xeon Gold 5416S – 32C/64T – 2.0/4.0Ghz | Intel Xeon Gold 6430 – 64C/128T – 2.1/3.4Ghz |
| V4.0 | Intel Xeon Gold 6526Y– 32C/64T – 2.8/3.9Ghz | Intel Xeon Gold 6530 – 64C/128T – 2.1/4.0Ghz |
| V4.0 HF | Intel Xeon Gold 6544Y – 32C/64T – 3.6/4.1Ghz |
For costs check the current dedicated server pricing.
A reminder that the Spark Cluster will also be pulling from Delta on the Object Storage cluster when it ingests the raw data. Spark will also likely be using various Delta Tables for cleaned data. Your object cluster will be located within the same VLANs as your Spark cluster and physically a few switch hops away only.
Our first goal will be to run on any unused resources on your private cloud with OpenMetal. There are some limitations with mixing Spark workloads with your current Cloud workloads but it is a great way to be efficient.
Ratio wise, in the public clouds, it is common to have a 2:8 vCPU to RAM ratio VMs. For example:
- 4vCPUs with 16GB RAM
- 8vCPUs with 32GB RAM
- 16vCPUs with 64GB RAM
Your OpenStack powered private cloud can support these VMs, of course, but this may not be ideal for your workload. Once Spark jobs are loaded into memory, the CPU or the Network becomes the bottleneck during processing.
On a private cloud you can choose your ratio as needed. During your PoC, our team will work with you to determine the right CPU ratio and underlying cloud clock speed. Check out our dedicated servers for Spark.
NOTE: It is not recommend to exceed 200GB of RAM as the Java Virtual Machine that actually contains Spark in your VM or on your bare metal is not currently stable at that size. More JVMs at a smaller size is the right approach.
Cloud Resources – Component 3 of a Production Delta Lake
The last core component for running a Delta Lake, Spark, and MLflow pipeline is a mixture of servers for the following various systems.
- Business Intelligence tools and databases
- Spark’s various Cluster Management systems
- Kafka or other streaming/ingestion tools (see Kafka dedicated servers)
- MLFlow servers or other data pipeline management systems
- Other servers you will want/need
For ease, we commend using VMs versus bare metal as many of these systems are relatively small. You may also have resources in your hosted private cloud and so it makes sense to use them.
OpenMetal can setup bare metal and cloud resources within the same VLANs and in the same data centers for maximum throughput.
OpenMetal Cloud
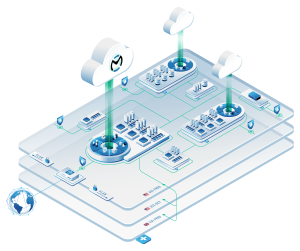
Roadmap from Planning to V1 and V2
We are excited to take on the challenge outlined above. Our mission is to deploy large scale and complex open source systems in a way that empowers “non-enterprises”. This combination of Delta Lake and Spark is just such a challenge.
Note about Databricks
We are also hopeful that Databricks, the company behind this stack, may decide to engage with us to run their integrated service on OpenMetal private clouds.
We have all the components needed, as outlined above, to match what can be done on a mega public cloud.
Our roadmap, roughly, is as follows:
- Select 2-4 use cases from our own workloads. Start with one focused on data engineering/data science for business intelligence and one big data streaming for on-the-fly operational decision making.
- Use Ansible (or other) playbooks to load Kafka, Delta Lake, MLFlow, Spark, etc. onto a default private cloud. All the needed resources for a rapid PoC, including the object storage, VMs, and Kubernetes as a service come with the default on-demand Private Cloud powered by OpenStack.
- Split the data streams and run our in house use cases on the new platform. Let the engineers break and fix it in the PoC state with real data then get feedback from the users. Update the playbooks according.
- System is now V0.9. Next we move the actual production data to this new system. Bugs are ironed out, apologies to our internal teams are made. This is an accepted practice inside OpenMetal. Use your own systems and if you don’t like it, fix it.
- System is now V1.0. An agreement is made with a small set of customers to be our V1.0 users. It is not a beta because the systems we are implementing are mature and robust and we are connecting them with mature and robust underlying systems.
- We now go into rapid release of V1.1, V1.2, etc. until we have various different deployments based on different use cases and scale.
As we progress on this roadmap we will be adding orchestration and systems needed to support the pure open source install and thus will either have all or most of what Databricks needs from a cloud.