
































With more focus on big data and the need to translate many data sources to other data consumers, Apache Kafka has emerged as the leading tool for efficiently and reliably handling this. In addition to configurations, maximizing Kafka’s capabilities is tied directly to the infrastructure you select. Additional reference architectures can be provided if need, contact your account manager.
Two good options in the OpenMetal catalog are our “Large” and “XL” bare metal dedicated servers from our V2.1, V3, and V4 versions.
The Large and XL Servers for Kafka – Recommended Hardware
Kafka CPU Needs
Kafka brokers handle tasks such as message routing, replication, and data compression. These operations can be CPU intensive, particularly when dealing with large volumes of messages or when applying complex transformations.
Kafka’s replication mechanism involves tasks like data synchronization and consistency checks across broker replicas. These tasks can benefit from parallel execution on multiple CPU cores.
Kafka’s coordination tasks, such as managing consumer group offsets and rebalancing partitions among consumers, can become CPU bound, especially in environments with numerous consumers and frequent group membership changes.
In general, Kafka’s CPU requirements are more focused on number of cores/threads rather than on high frequency. Kafka’s workload is typically many smaller actions rather than executing a single task quickly. CPUs with high core count and reasonable frequency are likely effective and cost less than high core count and high frequency.
For example, the Gold 6526Y runs at a base clock speed of 2.8Ghz – the speed that you can count on under load when a CPU is running at or nearly at its temp limit. This is a pretty high clock speed in a server. You might want to get an older XL, with twice as many cores, but slower cores, as this could mean an economical choice for you.
| Version | Large | XL |
|---|---|---|
| V2.1 | Intel Xeon Silver 4314 – 32C/64T – 2.4/3.4Ghz | Intel Xeon Gold 6338 – 64C/128T – 2.0/3.2Ghz |
| V3.0 | Intel Xeon Gold 5416S – 32C/64T – 2.0/4.0Ghz | Intel Xeon Gold 6430 – 64C/128T – 2.1/3.4Ghz |
| V4.0 | Intel Xeon Gold 6526Y– 32C/64T – 2.8/3.9Ghz | Intel Xeon Gold 6530 – 64C/128T – 2.1/4.0Ghz |
Check the current dedicated server pricing.
Kafka and RAM Requirements
The Large comes with 512GB of RAM and the XL comes with 1TB of RAM regardless of Version. Some customization is possible, check with your Account Manager.
Kafka uses in-memory data structures to manage and track the state of partitions, offsets, and other metadata. These structures allow for quick access and manipulation of data, which is important for Kafka’s low-latency message delivery. The amount of RAM available can significantly affect the performance of these operations.
Kafka heavily relies on the underlying file system’s page cache to pass data to consumers. The page cache is managed by the operating system and is backed by unused portions of RAM. Having a large RAM allocation for your Kafka dedicated server allows more data to be cached, which in turn, can significantly improve Kafka’s performance by reducing disk reads for frequently accessed data.
Kafka stores messages in log segments on disk, and each segment is indexed to enable fast lookups. These indices are kept in memory to speed up reads and writes. The size and number of indices that can be held in RAM directly affect Kafka’s ability to quickly locate and retrieve messages.
Kafka’s replication feature ensures high availability and fault tolerance by duplicating data across multiple brokers. This process involves buffering messages in memory before they are replicated to other brokers. Adequate RAM is necessary to buffer these messages effectively, especially in high-throughput environments.
Kafka tracks consumer group offsets in memory to manage message consumption. This tracking requires significant memory resources, especially in scenarios with numerous consumers and high message volumes.
For a Kafka dedicated server, sufficient RAM is key or you may see an “OutOfMemoryError” during Log Compaction that can shutdown a broker and lose data.
Zookeeper Servers – Dedicated Servers or Dedicated VMs from one of your Clouds
It is required for HA to keep your Zookeeper instances separated from your Kafka broker nodes. Running Zookeeper in VMs on your hosted private cloud may be a good option for you and we can help you get your VLANs right for this. You can also run Zookeeper on their own bare metal dedicated servers, one instance per server, but that will be overkill for smaller Kafka clusters.
Kafka Cluster – High Private Network Connectivity Requirements
20gbps of connectivity per server is included with all Large and XLs and should exceed most Kafka hardware requirements. This is between nodes in your Kafka broker cluster and between your Zookeeper monitors. This high bandwidth network infrastructure supports the demanding data throughput required for good performance. Deploying 2, 4, or 8 Kafka broker servers simultaneously is common to get started for your cluster. 3 Zookeeper nodes are common as well, but again, consider VMs for that. If you are following a Kafka Reference Architecture we may have some adjustments based on our network including options for 40gbps for your Kafka clusters with very high requirements.
Kafka and Server Grade NVMe SSD Drives
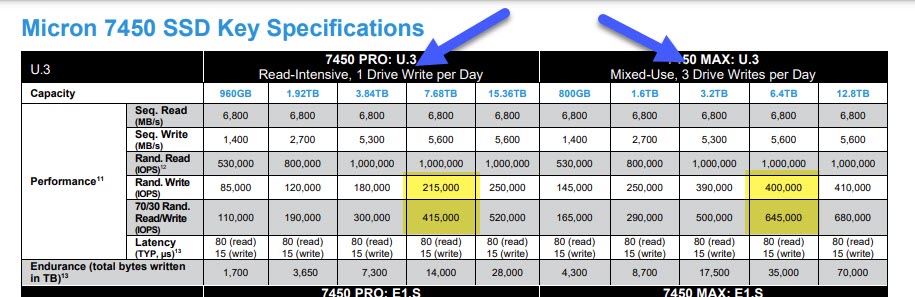
Now onto server grade NVMe SSD. Kafka can require substantial storage based on your data retention, duplication and other settings. Unfortunately, it also needs rapid access to this storage. We typically recommend our 6.4TB Micron 7450 MAX NVMe drives be used in your dedicated server for Kafka. Kafka’s performance can become I/O bound and though much work has been done to allow for sequential writes, “fast random write” drives will improve Kafka’s throughput. That being said, both the Micron MAX and the Micron PRO have pretty amazing I/O performance and it will be up to you on cost vs storage vs I/O benefits.
The Large and XL can be expanded as well and we have a special order available called the XL Storage Max that can handle 24 drives:
| Version | Large | XL | XL Max Storage |
|---|---|---|---|
| V2.1 | Up to 6 Drives | Up to 10 Drives | Up to 24 Drives |
| V3.0 | Up to 6 Drives | Up to 10 Drives | Up to 24 Drives |
| V4.0 | Up to 6 Drives | Up to 10 Drives | Up to 24 Drives |
Adding a Kafka Cluster to Your Deployment
Generally, running Kafka directly on bare metal physically close to your largest data sources or consumers has the best performance. You will want to talk to your Account Manager or Account Engineer about adding them to common VLANs between any bare metal servers and hosted private clouds. Kafka also is very typically not located physically close to its data sources and consumers, but close has advantages.
Not a current customer? Come meet us!
More on the OpenMetal Blog…

Leveraging On-Demand Private Clouds: A Guide for CTOs
Explore this comprehensive guide on how Chief Technology Officers (CTOs) and technical executives can harness the power of on-demand private clouds for their organizations. In ….Read More

Alternative Clouds Blurring The Lines Between Public and Private Clouds
This blog discusses the rising costs and lack of control in public cloud services and explores the alternative solution of OpenMetal’s On-Demand …Read More

AWS vs GCP: Choosing the Right Cloud Platform
AWS and GCP are leading players in cloud computing, offering a wide range of services and attractive pricing. However, choosing the right platform requires understanding their strengths … Read More
Test Drive
For eligible organizations, individuals, and Open Source Partners, Private Cloud Cores are free to trial. Apply today to qualify.
Subscribe
Join our community! Subscribe to our newsletter to get the latest company news, product releases, updates from partners, and more.