


































In this article
- Understanding Over-Provisioning in Cloud Infrastructure
- How OpenMetal’s Pricing Model Changes the Equation
- Practical Over-Provisioning Strategies for CI/CD
- Network and Storage Infrastructure Advantages
- Real-World Implementation Patterns
- When Over-Provisioning Makes Financial Sense
- Monitoring and Optimization
- Wrapping Up: Rethinking Infrastructure Economics
When your CI/CD pipeline fails because you ran out of compute capacity (again) your first instinct might be to question whether you’ve over-provisioned your infrastructure. In public cloud environments, that instinct makes financial sense. But on OpenMetal’s dedicated hardware model, that conventional wisdom gets turned on its head. Over-provisioning isn’t a wasteful mistake, it’s a deliberate cost optimization strategy that can reduce your infrastructure spend while improving performance.
Understanding Over-Provisioning in Cloud Infrastructure
Before exploring why over-provisioning works differently on OpenMetal, let’s talk about what the term traditionally means and why it carries such negative connotations in public cloud contexts.
What Over-Provisioning Actually Means
Over-provisioning refers to allocating more computing resources—CPU, memory, and storage—than a system currently needs for its workload. This practice aims to ensure sufficient resources are available to handle unexpected demand spikes without compromising performance. The strategy involves creating a deliberate gap between total physical capacity and what you actively use at any given moment.
In traditional IT infrastructure, over-provisioning means allocating more resources than necessary to ensure systems can handle peak loads and unexpected spikes in demand. Companies do this to maintain performance assurance during high-demand periods and provide headroom for growth without immediate infrastructure changes.
Why Public Cloud Penalizes Over-Provisioning
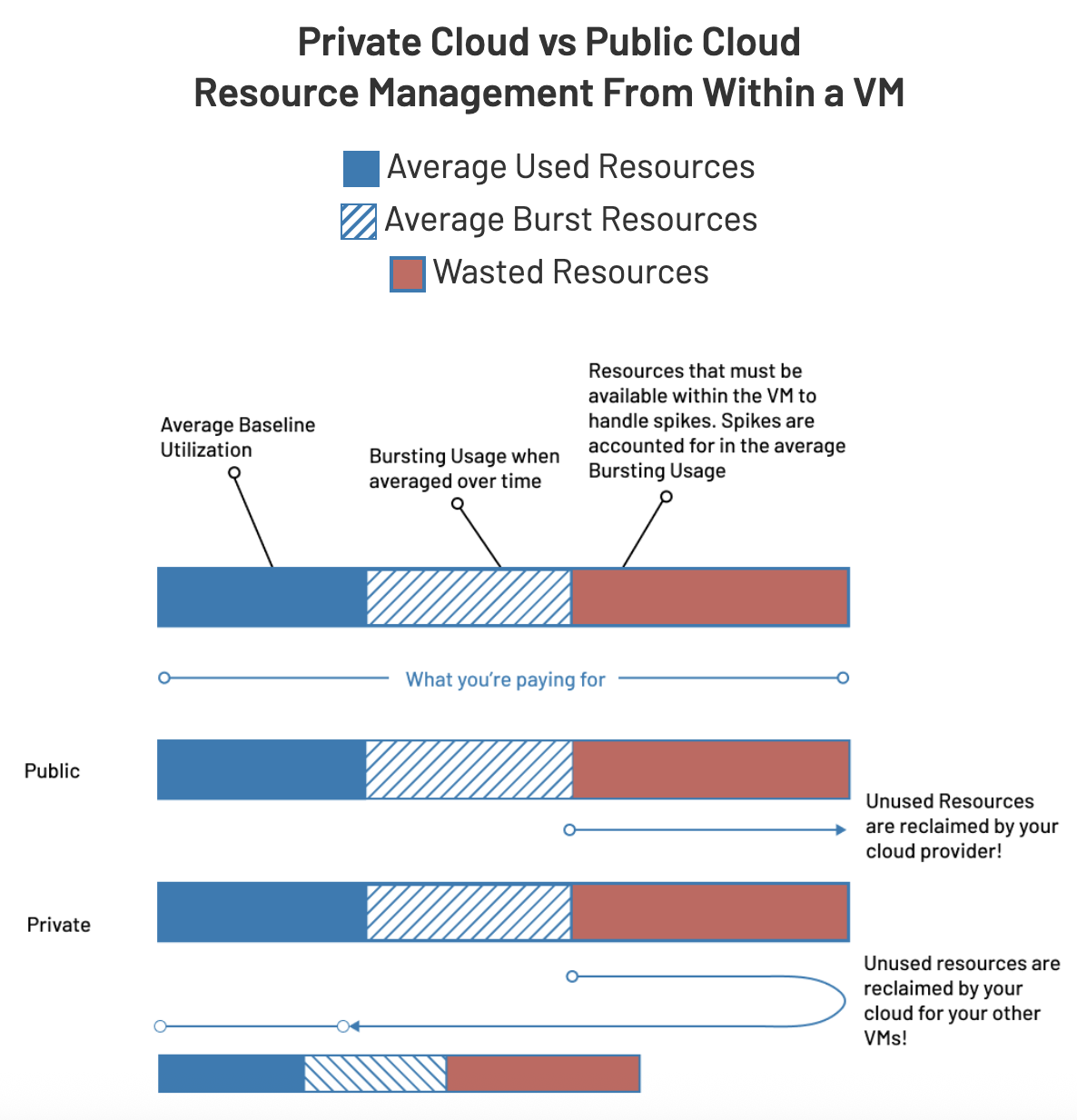
Public cloud providers like AWS, Azure, and Google Cloud operate on a pay-per-resource consumption model. When you allocate a 32-vCPU instance, you pay for all 32 vCPUs whether your build jobs use them or not. The biggest downside is higher costs associated with maintaining excess capacity, especially in pay-as-you-go cloud environments where unused resources represent wasted spending.
This creates a fundamental tension in public cloud infrastructure planning. Your CI/CD workloads are bursty by nature: mostly idle, then briefly spiking to 100% CPU when builds kick off. To handle those peaks without performance degradation, you need significant capacity. But public cloud pricing assumes continuous full utilization, so you end up paying premium rates for resources that sit idle 80% of the time.
The financial pressure pushes teams toward conservative provisioning, which introduces its own problems. Queue times increase. Builds slow down. Developers wait. And paradoxically, you may end up spending more on premium instance types or “burstable” performance tiers that charge extra for temporary performance boosts.
The Over-Provisioning Paradox for Bursty Workloads
Companies often overprovision to absorb the highest end-user demands, particularly when facing unpredictable demand patterns. For CI/CD infrastructure, this creates a paradox: you need substantial resources to handle peak build loads, but those peaks are brief and intermittent. Public cloud economics force you to choose between expensive over-provisioning or performance-degrading under-provisioning.
Development teams running hundreds of builds daily face this challenge constantly. A typical pattern might see 50 simultaneous builds running for 15 minutes during morning code commits, followed by hours of near-complete idleness. Under public cloud pricing, you’re essentially paying for peak capacity 24/7 to support workloads that peak for perhaps 2-3 hours daily.
How OpenMetal’s Pricing Model Changes the Equation
OpenMetal’s fixed monthly per-server pricing fundamentally inverts traditional cloud economics. Instead of paying per vCPU or per GB of RAM, you lease entire physical servers. This single change transforms over-provisioning from a cost liability into a cost optimization technique.
Fixed Monthly Costs vs. Metered Resource Pricing
When you provision an OpenMetal hosted private cloud server, you pay a flat monthly rate regardless of how you configure the virtual machines running on it. Creating a VM with 4 vCPUs costs the same as creating one with 32 vCPUs because you already own the entire underlying physical server and all its cores.
This means unused capacity has zero marginal cost. Those idle vCPUs sitting dormant between build runs? They’re already purchased. You might as well allocate them to your VM fleet and put them to work when needed, rather than artificially restricting yourself out of habit formed by public cloud pricing models.
The Zero Marginal Cost of Idle Resources
Here’s where the math gets interesting for CI/CD workloads. OpenMetal customers routinely configure 4:1 CPU over-subscription ratios, like 128 vCPUs allocated across VMs running on 32-core physical servers. This sounds excessive until you understand how build jobs actually behave.
Most CI/CD tasks spend the majority of their lifecycle waiting: cloning repositories, fetching dependencies, waiting for database test fixtures to initialize. During these idle periods, your VMs consume minimal CPU resources. OpenStack’s Nova scheduler intelligently distributes VMs across physical cores, so when builds aren’t actively running, those “over-allocated” vCPUs simply don’t consume resources.
But when multiple builds kick off simultaneously, like that morning rush of 50 concurrent builds, each VM can burst to use its full allocated vCPU count. They access the underlying physical hardware directly, without the “noisy neighbor” problems common in public cloud environments where hundreds of customers share the same physical infrastructure.
The result? You achieve 3-4x compute density compared to conservative public cloud provisioning ratios, while maintaining full performance during peak loads. And because you’re paying a fixed monthly rate, that 4x density improvement translates directly to 4x better ROI on your infrastructure investment.
Why Dedicated Hardware Eliminates the “Virtualization Tax”
Public cloud providers maintain conservative over-subscription ratios to guarantee performance across millions of customers sharing physical infrastructure. They price their services assuming continuous full utilization because they must accommodate worst-case scenarios across their entire customer base.
OpenMetal customers, by contrast, own entire physical hosts. You make informed over-provisioning decisions based on your actual workload patterns, not theoretical worst-case scenarios averaged across millions of users. For development infrastructure that genuinely sits idle much of the time, 4:1 CPU over-subscription is not just safe, it’s financially optimal.
Practical Over-Provisioning Strategies for CI/CD
Understanding the economics is one thing. Implementing these strategies effectively requires specific technical approaches tailored to CI/CD workload patterns.
Aggressive CPU Over-Subscription for Build Workloads
CPU over-subscription works particularly well for CI/CD because build jobs are inherently parallel and bursty. When you kick off 20 simultaneous builds, each build typically has multiple parallel steps: compiling different modules, running test suites concurrently, processing asset pipelines in parallel.
OpenMetal customers create custom VM flavors specifically for build workloads—configurations like “ci-builder-4×32” that allocate 32 vCPUs to VMs. When you have ten such VMs on a 32-core physical server, you’ve created 320 vCPUs of theoretical capacity. In practice, build jobs rarely consume all allocated CPU simultaneously, and OpenStack’s scheduler handles the actual physical core allocation dynamically.
This approach achieves compute density impossible on public cloud without triggering performance throttling or premium pricing tiers. Your build times remain consistent because you have direct access to underlying hardware rather than competing with other tenants for shared resources.
Memory Over-Commitment with Careful Planning
Memory over-commitment requires more careful consideration than CPU over-subscription because RAM is a non-compressible resource. However, with full root access to your OpenMetal private cloud, you can implement sophisticated strategies.
One approach involves analyzing actual memory usage patterns across your build jobs. Many CI/CD tasks have surprisingly modest memory footprints—cloning repositories, running linters, executing unit tests typically peak at 2-4GB RAM despite being allocated 8GB “just in case.” By monitoring real utilization data, you can confidently over-commit memory while maintaining headroom for legitimate peaks.
OpenMetal’s XL V4 and XXL V4 servers provide 1TB+ of physical RAM, supporting very large VMs for monorepo builds that would trigger premium pricing on public cloud. When you need a 32 vCPU/64GB VM for compiling massive codebases, the fixed monthly pricing means that large instance costs the same as a smaller one—another way over-provisioning becomes cost-neutral.
Storage Optimization Through Lower Redundancy Pools
Ceph storage enables flexible redundancy configuration, and OpenMetal’s full root access lets you tune this for specific workload needs. For ephemeral CI/CD data—build artifacts, temporary test databases, cached dependencies—you can configure lower redundancy storage pools.
Standard production data might use replica 3 (three copies of every data block across the cluster). But for data that only needs to survive the duration of a build job, replica 2 reduces storage overhead by 33%. If a node fails during a build, the job simply reruns. This pragmatic approach optimizes for the actual risk tolerance of temporary data rather than applying production-grade redundancy everywhere.
Build artifacts that need retention get stored on higher-redundancy pools, while truly ephemeral data uses minimal redundancy. This storage tiering happens transparently within your cluster and costs nothing extra, another example of over-provisioning the right resources in the right places.
CPU Pinning for Mixed Workload Performance
For teams running both latency-sensitive workloads and high-throughput build jobs on the same hardware pool, CPU pinning provides a solution. This technique reserves specific physical CPU cores for particular VMs, ensuring predictable performance for latency-sensitive applications.
You might pin cores 0-7 to your database servers or real-time processing VMs, guaranteeing they always have dedicated physical resources. Then allow your build worker VMs to over-subscribe across cores 8-31. This mixed strategy maximizes density while maintaining SLAs for critical services, something nearly impossible to achieve with public cloud’s opaque resource allocation.
Network and Storage Infrastructure Advantages
Over-provisioning benefits extend beyond compute resources. OpenMetal’s network architecture and storage capabilities provide additional opportunities for cost-free capacity expansion.
CephFS NFS Exports for Concurrent Container Writes
CephFS NFS exports enable 10-20 containers to write concurrently to shared storage locations, particularly valuable for distributed testing scenarios. Instead of each container maintaining its own storage volume (which requires replication overhead), multiple containers share a single CephFS export.
This approach eliminates storage replication overhead for concurrent write workloads. Public cloud equivalents like Amazon EFS charge per-GB monthly plus data transfer fees. On OpenMetal, shared storage is included in your fixed monthly rate, and your unmetered private networking makes artifact movement between services completely free.
Unlimited VLANs and Network Isolation
Development workflows typically require multiple isolated environments like development, staging, and production deployments. On public cloud, each environment incurs costs for VPCs, NAT gateways, and transit gateways to enable network isolation and inter-environment connectivity.
OpenMetal customers can create unlimited VLANs with security group isolation on the same hardware pool at zero marginal cost. Spin up a complete development environment that mirrors production? No additional networking fees. Create temporary staging environments for feature branch testing? No extra charges. Destroy and recreate test environments daily? Still the same monthly cost.
This freedom to over-provision network infrastructure enables best practices that become cost-prohibitive on public cloud. Your CI/CD pipeline can spin up completely isolated test environments for every pull request without concern for multiplying network infrastructure costs.
Unmetered Data Transfer Between Services
Public cloud data transfer fees represent one of the most significant hidden costs for CI/CD infrastructure. Moving container images from registries to build nodes, shuffling test artifacts between services, syncing data between development and staging environments; these operations generate substantial monthly bills on AWS or Azure.
OpenMetal’s unmetered private networking eliminates these costs entirely. Build artifacts can move freely between services. Container registries can serve images to any number of build nodes. Test databases can replicate data to staging environments. All of this happens on your private network at no additional cost, enabling architectural patterns that would be prohibitively expensive elsewhere.
Real-World Implementation Patterns
Theory is helpful, but practical implementation determines whether these strategies actually deliver value. Here’s how teams structure their OpenMetal infrastructure for maximum efficiency.
Sizing Servers for Workload Density
The key question when designing your OpenMetal deployment is whether to provision fewer large servers or more smaller servers. For over-provisioned CI/CD workloads, larger servers generally provide better value.
A single large server with 64 cores and 512GB RAM can support dozens of build worker VMs, each configured with 4-8x CPU over-subscription. This consolidation simplifies management, reduces licensing overhead (for any per-node software), and maximizes the efficiency of shared resources like network bandwidth and storage access.
The trade-off comes in failure domains. Multiple smaller servers provide better redundancy. If one server fails, you lose less total capacity. Teams typically balance these concerns based on their specific risk tolerance and workload patterns.
Creating Custom VM Flavors for Specific Build Types
OpenStack’s flavor system lets you define custom VM configurations optimized for different job types. Rather than using generic small/medium/large instances, create purpose-built flavors:
ci-builder-standard: 8 vCPUs, 16GB RAM for typical application builds
ci-builder-large: 16 vCPUs, 32GB RAM for parallel test execution
ci-builder-monorepo: 32 vCPUs, 64GB RAM for massive monorepo compilation
ci-runner-lightweight: 2 vCPUs, 4GB RAM for linting and simple scripts
These custom flavors encode your organization’s specific workload patterns into the infrastructure. Developers select the appropriate flavor for their job requirements, and you optimize density based on real usage data rather than vendor-defined instance categories.
Dynamic Scaling with Fixed Capacity
One counterintuitive aspect of over-provisioned infrastructure is that you can implement dynamic scaling without dynamic costs. Your physical capacity remains fixed, but you can programmatically create and destroy VMs based on build queue depth.
When your CI/CD system sees 50 jobs waiting in queue, it can automatically provision 20 additional build worker VMs. When the queue drains, those VMs get destroyed. This provides the user experience of auto-scaling without the public cloud’s corresponding cost multiplication, because those VMs are carved from your fixed capacity pool rather than metered external resources.
This pattern works particularly well with automation tools that integrate with your CI/CD orchestration platform. Build queue depth becomes a signal for VM scaling decisions, letting you maintain responsiveness during peak periods while recovering resources during idle times.
When Over-Provisioning Makes Financial Sense
While over-provisioning on dedicated hardware offers compelling advantages, it’s not universally optimal. Understanding when this approach delivers maximum value helps you make informed infrastructure decisions.
Workload Characteristics That Benefit Most
Over-provisioning strategies deliver maximum value for workloads with several key characteristics:
High burstiness: Jobs that idle most of the time but occasionally spike to 100% resource utilization see the biggest benefits. CI/CD perfectly fits this pattern.
Predictable resource patterns: When you understand your workload’s actual resource consumption—even if it’s highly variable—you can confidently over-provision because you know the statistical distribution of resource needs.
Low sustained utilization: If your infrastructure averages 20-30% CPU utilization but peaks at 80-100% during builds, over-provisioning captures value from that idle capacity that you’re paying for anyway.
Parallel workload distribution: Tasks that can run concurrently across many VMs benefit from having abundant virtual capacity available, even when physical resources are shared.
Break-Even Analysis Against Public Cloud
The financial case for over-provisioned dedicated hardware strengthens as your baseline infrastructure spend increases. Public cloud costs for CI/CD infrastructure typically fall into several categories:
Compute instances: On-demand or reserved instances running build workers
Data transfer: Moving artifacts, images, and test data between services
Storage: Persistent volumes for caching, artifact storage, and temporary build data
Network infrastructure: VPCs, NAT gateways, load balancers, and transit gateways
Teams spending $20,000+ monthly on CI/CD infrastructure often find that OpenMetal’s private cloud delivers 2-4x more effective capacity at similar or lower total costs. The break-even point varies based on specific usage patterns, but the gap widens as over-provisioning ratios increase.
Development Infrastructure as the Ideal Use Case
Development infrastructure represents perhaps the ideal use case for over-provisioned dedicated hardware. Development environments typically exhibit:
Extremely low sustained utilization: Development, staging, and testing environments might see active use for only 8-10 hours daily during business hours, with weekends mostly idle.
High peak-to-average ratios: When developers are actively working, they need responsive infrastructure. During off-hours, resources sit unused.
Multiple environment copies: Teams need dev, staging, QA, and production-mirror environments, multiplying costs on public cloud but costing nothing extra with over-provisioned dedicated hardware.
Frequent environment churn: Creating and destroying test environments for feature development becomes cost-prohibitive on public cloud but essentially free when over-provisioned.
This combination of factors makes development infrastructure the workload category most likely to see dramatic cost savings from OpenMetal’s over-provisioning approach.
Monitoring and Optimization
Over-provisioning doesn’t mean ignoring resource utilization. Careful monitoring ensures you’re actually capturing the expected benefits and helps you refine your configuration over time.
Tracking Actual Resource Utilization
OpenStack provides detailed metrics on actual vs. allocated resources. Monitor these key indicators:
vCPU allocation vs. physical CPU utilization: Track how many vCPUs you’ve allocated compared to actual physical core usage. This reveals your effective over-subscription ratio and whether you have room to increase density further.
Memory allocation vs. actual usage: While you must be more conservative with memory over-commitment, monitoring actual usage patterns helps identify opportunities for optimization.
Storage consumption patterns: Track which storage pools see heaviest usage and whether lower-redundancy pools are providing sufficient performance for ephemeral data.
Network bandwidth utilization: Ensure your over-provisioned VMs aren’t creating network bottlenecks that could degrade performance.
These metrics inform decisions about whether you can increase over-provisioning ratios, need to adjust VM flavor configurations, or should redistribute workloads across physical hosts.
Identifying Optimization Opportunities
Regular analysis of resource usage patterns reveals optimization opportunities. You might discover that certain build types consistently under-utilize their allocated resources, suggesting you can reduce those VM flavors and create more instances of that type instead.
Conversely, jobs that consistently max out their allocated resources might benefit from larger flavors. Not because they need more capacity on public cloud, but because giving them more vCPUs from your over-provisioned pool will improve their performance without additional cost.
The key insight is that optimization decisions on over-provisioned infrastructure differ fundamentally from public cloud optimization. Instead of asking “how can we use fewer resources?”, you’re asking “how can we better utilize the fixed capacity we’ve already purchased?”
Adjusting Over-Subscription Ratios Over Time
As your workload patterns evolve, you’ll want to adjust over-subscription ratios accordingly. If you’ve been running 3:1 CPU over-subscription comfortably, with physical CPU utilization rarely exceeding 60%, you probably have room to move to 4:1 or even 5:1 ratios.
These adjustments happen through VM flavor reconfiguration rather than infrastructure changes. You’re not adding physical capacity; you’re more efficiently utilizing what you already have. This continuous optimization process helps you maximize ROI on your dedicated hardware investment.
Wrapping Up: Rethinking Infrastructure Economics
The conventional wisdom around over-provisioning emerged from public cloud’s metered pricing model, where unused capacity represents wasted spending. But that wisdom doesn’t apply to OpenMetal’s dedicated hardware model, where unused capacity represents opportunity.
For CI/CD workloads, development infrastructure, and other bursty workload patterns, over-provisioning on OpenMetal turns a cost liability into a deliberate optimization strategy. By allocating 4x the vCPUs, creating unlimited isolated networks, and using lower-redundancy storage for ephemeral data, you maximize the value of fixed-cost infrastructure that you’re already paying for regardless of how you configure it.
The strategies we’ve discussed—aggressive CPU over-subscription, custom VM flavors, dynamic scaling within fixed capacity, and storage tiering—are the same approaches we use at OpenMetal to optimize our own infrastructure and power the OpenInfra Foundation’s CI/CD cloud. When you deploy an OpenMetal private cloud, you’re getting a platform where over-provisioning isn’t a bug to fix, it’s a feature to embrace.
FAQs
How does CPU over-subscription actually work without causing performance problems?
CPU over-subscription works because most workloads—especially CI/CD jobs—spend significant time idle or waiting on I/O operations rather than actively computing. OpenStack’s Nova scheduler assigns virtual CPUs to physical cores dynamically based on actual demand. When multiple VMs need CPU simultaneously, they each get their share of the physical cores. When VMs are idle, other VMs can use those physical resources. This differs from public cloud, where conservative over-subscription ratios must accommodate worst-case scenarios across millions of shared-infrastructure customers.
What’s the difference between over-provisioning and over-allocation?
Over-provisioning deliberately allocates additional resources for specific purposes like performance optimization, whereas over-allocation assigns more resources than a system can actually handle, leading to resource exhaustion. Over-provisioning on OpenMetal is a calculated strategy based on workload patterns; you’re giving VMs more vCPUs than they typically need but less than the physical system can support. Over-allocation would be creating so many VMs that physical resources become genuinely exhausted, causing performance degradation.
Can I mix over-provisioned CI/CD workloads with production services on the same hardware?
Yes, with proper planning. CPU pinning lets you reserve specific physical cores for latency-sensitive production services while allowing build workers to over-subscribe remaining cores. You can also use separate storage pools with different redundancy levels: higher redundancy for production data, lower redundancy for ephemeral build artifacts. Network isolation through VLANs and security groups keeps workloads separated. The key is monitoring resource utilization to ensure your over-provisioning ratios leave adequate headroom for production SLAs.
How do I determine the right over-subscription ratio for my workloads?
Start conservatively—perhaps 2:1 CPU over-subscription—and monitor actual physical CPU utilization for several weeks. If you consistently see less than 50% physical core usage even during peak periods, you can safely increase to 3:1 or 4:1. For memory, be more conservative since RAM is non-compressible. Analyze your actual memory consumption patterns across typical workloads before implementing any memory over-commitment. The goal is finding the ratio that maximizes density while maintaining performance during legitimate peak loads.
What happens if I over-provision too aggressively and exhaust physical resources?
OpenStack’s scheduler will queue VM operations until resources become available. You’ll see increased latency for VM launches and potentially slower performance for running VMs if they must compete heavily for physical resources. However, this is easily detectable through monitoring. If you hit this threshold, you can reduce over-subscription ratios by reconfiguring VM flavors or add additional physical servers to your pool. The key advantage is that experimentation costs nothing. Adjusting over-subscription ratios is a configuration change, not a billing change.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog