


































In this article
- What Are DePIN Compute Networks?
- The Verification Problem: Why DePIN Needs Hardware Attestation
- Why Virtualization Breaks DePIN Attestation
- Bare Metal: Direct Hardware Access For Complete Attestation
- OpenMetal’s GPU Infrastructure For DePIN Workloads
- DePIN Protocol Hardware Requirements
- Setting Up A DePIN Node On Bare Metal
- Economics: When Does Bare Metal Make Sense For DePIN?
- Real-World DePIN Node Operations: Three Scenarios
- Common Pitfalls And How To Avoid Them
- Alternative Approaches And Their Limitations
- The Future Of DePIN And Infrastructure Requirements
- Getting Started With DePIN On OpenMetal
- Troubleshooting Common DePIN Node Issues
- Advanced Optimization Techniques
- Wrapping Up: Bare Metal As DePIN’s Essential Foundation
Your GPU cluster is earning $847 this month on io.net. At least, that’s what the dashboard says. But when verification runs, the node fails attestation. The protocol can’t confirm your hardware specs through AWS’s virtualization layer. Your H100 GPUs report as generic compute units. No attestation means no rewards. That’s $847 in lost earnings because you tried to run decentralized compute on virtualized infrastructure.
This happens by design. Decentralized Physical Infrastructure Networks (DePIN) require cryptographic proof that specific physical hardware exists and is performing real work. Virtualization layers break this verification chain by obscuring hardware identities. For DePIN compute providers looking to maximize node earnings and uptime, bare metal is the only reliable substrate that works.
What Are DePIN Compute Networks?
Decentralized Physical Infrastructure Networks aggregate computing resources from independent providers into permissionless marketplaces. Instead of renting GPUs from AWS or Azure, AI developers can access compute from thousands of distributed nodes, each contributing their hardware to the network.
Major DePIN compute protocols include:
Render Network originally focused on 3D rendering but now expanding into AI inference and model training. The network connects GPU providers with artists, developers, and data scientists through the RENDER token economy.
Akash Network operates as an open cloud marketplace for CPU, GPU, and storage resources. Tenants specify their requirements and providers bid on deployments, with the lowest bidder winning the work.
io.net provides distributed GPU clusters specifically for AI and machine learning workloads. The platform aggregates compute from data centers, crypto miners, and other decentralized networks, supporting cluster deployment in under two minutes.
Gensyn specializes in machine learning and deep learning computations, using Proof-of-Compute mechanisms to verify contributions to AI training tasks. The protocol aims to democratize access to high-performance AI infrastructure.
The value proposition is compelling. Traditional cloud GPU costs run $3 to $8 per hour for high-end cards. DePIN networks claim to offer equivalent compute at 50-80% discounts through radical decentralization. But this model only works when protocols can verify what hardware is actually performing the work.
The Verification Problem: Why DePIN Needs Hardware Attestation
Every DePIN protocol faces the same fundamental challenge. Work happens off-chain, in the physical world. How do you verify that a node operator claiming to have eight H100 GPUs actually has them? How do you prevent someone from renting cheap A100s but reporting them as more expensive H100s to earn higher rewards?
This is what DePIN researchers call the “oracle problem”. Blockchains are excellent at verifying computational state changes, but they can’t directly observe physical hardware. The solution is hardware attestation, a process where nodes submit cryptographic proofs about their physical configuration.
Hardware attestation typically involves:
Device identification through PCI device IDs, GPU serial numbers, or cryptographic hardware modules. The node must prove it controls specific physical hardware.
Capability verification confirming GPU model, VRAM capacity, CUDA core count, and compute capability version. This prevents operators from misrepresenting lower-tier hardware.
Performance benchmarking running standardized workloads to verify the hardware can actually deliver the claimed performance. A node claiming H100 specs must demonstrate H100-level throughput.
Continuous monitoring ongoing verification that the hardware remains online and capable. Protocols need proof that nodes aren’t going offline or degrading after initial verification.
Some protocols use trusted execution environments (TEEs) like Intel SGX or TDX for additional security. Others implement probabilistic verification through random sampling, similar to how mining pools verify hashrate. The specific mechanism varies by protocol, but all require direct hardware access.
This is where virtualized cloud infrastructure fails catastrophically.
Why Virtualization Breaks DePIN Attestation
Public cloud providers virtualize everything. When you rent a g5.12xlarge instance on AWS, you’re not getting direct access to physical GPUs. You’re receiving GPU compute capacity mediated through a hypervisor layer. This abstraction enables AWS to maximize utilization and provide flexibility, but it destroys the attestation properties DePIN protocols require.
PCI device masking is the first problem. Hypervisors intercept PCI bus communications between the guest operating system and physical hardware. When your DePIN node queries GPU properties, it receives abstracted responses from the hypervisor rather than direct hardware information. GPU-Z or similar tools report generic device IDs instead of specific GPU serial numbers or authentic firmware signatures.
Incomplete GPU passthrough compounds the issue. Even when cloud providers offer GPU passthrough modes, the implementation is often partial. VRAM reporting becomes unreliable. Clock speeds get abstracted. The node can’t access low-level hardware counters that attestation protocols use to verify authentic hardware.
Noisy neighbor interference creates unpredictable performance. Your virtualized GPU shares the physical PCI bus, system memory, and power delivery with other virtual machines. When attestation runs performance benchmarks, results vary wildly based on what else is running on the same physical server. The protocol sees inconsistent performance that doesn’t match claimed hardware specs.
Hypervisor overhead adds 10-15% performance penalty even in ideal conditions. This matters because DePIN benchmarks expect bare metal performance characteristics. When your “H100” performs 15% slower than it should, the protocol may flag it as fraudulent hardware or downgrade your node’s reward tier.
The economic impact is severe. A node operator who invested in an expensive cloud GPU instance discovers that half their compute jobs fail verification. Jobs that do complete earn reduced rewards because the protocol suspects hardware misrepresentation. In the worst cases, nodes get banned from the network entirely for repeated verification failures.
DePIN protocols can’t simply “work around” virtualization. The entire security model depends on verifying physical hardware properties that virtualization explicitly hides. This isn’t a bug that will get fixed. It’s the fundamental purpose of hypervisors.

Bare Metal: Direct Hardware Access For Complete Attestation
Bare metal servers provide unmediated access to physical hardware. There’s no hypervisor layer between your DePIN node software and the GPUs. When the attestation protocol queries hardware properties, it receives authentic responses directly from the GPU firmware.
This transparency enables several critical capabilities:
Authentic device identification allows protocols to read actual GPU serial numbers, BIOS signatures, and cryptographic hardware identities. These unique identifiers prove you control specific physical hardware rather than virtual resources that could be duplicated or misrepresented.
Complete performance visibility gives attestation software access to every hardware counter, telemetry endpoint, and performance metric. The protocol can verify you have an H100 and confirm it’s functioning at full capability with proper cooling, power delivery, and interconnect bandwidth.
Deterministic benchmark results remove the variability introduced by virtualization. When your bare metal node runs attestation benchmarks, performance is consistent and reproducible. The protocol can confidently verify your hardware matches claimed specifications.
Full NVMe and network transparency extends beyond GPUs. Many DePIN workloads require fast storage for model weights and training data. Bare metal provides direct NVMe access with predictable IOPS and latency. Network interfaces operate at full bandwidth without virtualization overhead.
For multi-GPU configurations, bare metal enables proper interconnects. Eight H100 GPUs on bare metal can use NVLink for 900 GB/s GPU-to-GPU communication. This same configuration virtualized on public cloud might be limited to PCIe bandwidth, destroying performance for distributed training workloads.
The attestation process on bare metal is straightforward. Your node boots, the DePIN protocol queries hardware properties, the GPU responds with authentic firmware signatures and capabilities, and verification completes successfully. You start earning rewards immediately.
OpenMetal’s GPU Infrastructure For DePIN Workloads
OpenMetal’s bare metal GPU clusters are purpose-built for compute-intensive workloads that require hardware verification. The infrastructure provides unmediated access to enterprise-grade NVIDIA GPUs with the transparency DePIN protocols need for attestation.
X-Large Configuration: Maximum Compute Density
The X-Large tier delivers eight NVIDIA H100 GPUs with 640GB total HBM3 memory in a single server. This configuration is ideal for high-end DePIN applications:
Specifications:
- 8x NVIDIA SXM5 H100 GPUs
- 640GB HBM3 (80GB per GPU)
- 135,168 CUDA cores total
- 4,224 Tensor cores per GPU
- 2x Intel Xeon Gold 6530 processors (64C/128T each)
- Up to 16 NVMe drives for model storage
- 2x 960GB boot drives
- Up to 8TB DDR5 memory
- Pricing: Contact OpenMetal for current rates
Best suited for: Gensyn training workloads, Bittensor subnet validators, high-throughput io.net clusters requiring maximum GPU density. The eight-GPU configuration with NVLink provides 900 GB/s GPU interconnect bandwidth essential for distributed training tasks.
Large Configurations: Balanced Performance
The Large tier offers either dual H100 or single H100 configurations, providing flexibility for mid-tier DePIN workloads:
2x NVIDIA H100 PCIe:
- 160GB HBM3 total
- 33,792 CUDA cores
- 1,056 Tensor cores per GPU
- 2x Intel Xeon Gold 6530 (64C/128T each)
- 1x 6.4TB NVMe
- 2x 960GB boot drives
- 1024GB DDR5 memory
- Monthly: $4,608 (3-year agreement, paid monthly)
- Hourly equivalent: $6.31
1x NVIDIA H100 PCIe:
- 80GB HBM3
- 16,896 CUDA cores
- 528 Tensor cores
- Same CPU/storage configuration
- Monthly: $2,995 (3-year agreement, paid monthly)
- Hourly equivalent: $4.10
Best suited for: Render Network AI workloads, Akash Network mid-tier deployments, io.net clusters serving inference workloads. The dual-GPU configuration provides redundancy and load balancing for nodes serving multiple protocols simultaneously.
Medium Configurations: Cost-Effective Entry
The Medium tier with NVIDIA A100 GPUs provides enterprise-grade compute at more accessible pricing:
2x NVIDIA A100 80G:
- 160GB HBM2e total
- 13,824 CUDA cores
- 864 Tensor cores per GPU
- 2x Intel Xeon Gold 6530 (64C/128T each)
- 1x 6.4TB NVMe
- 2x 960GB boot drives
- 1024GB DDR5 memory
- Monthly: $3,087 (3-year agreement, paid monthly)
- Hourly equivalent: $4.23
1x NVIDIA A100 80G:
- 80GB HBM2e
- 6,912 CUDA cores
- 432 Tensor cores
- Same CPU/storage configuration
- Monthly: $2,234 (3-year agreement, paid monthly)
- Hourly equivalent: $3.06
Best suited for: Akash Network general-purpose compute, Render Network rendering tasks, entry-level io.net provider nodes. A100s remain highly capable for inference and fine-tuning workloads even as H100s dominate training benchmarks.
1x NVIDIA A100 40G:
- 40GB HBM2e
- 6,912 CUDA cores
- 432 Tensor cores
- AMD EPYC 7272 (12C/24T)
- 1TB NVMe storage
- 256GB DDR4 memory
- Monthly: $714 (3-year agreement, paid monthly)
- Hourly equivalent: $0.98
Best suited for: Smaller-scale DePIN experiments, development nodes for testing protocol integration, or lightweight inference workloads on networks that accept A100 40G specifications.
All configurations require a minimum 1-year commitment with 3-year pricing shown. Monthly payment structure provides predictable operating costs essential for ROI calculations in token-incentivized networks.
DePIN Protocol Hardware Requirements
Different DePIN networks have varying hardware requirements based on their workload characteristics. Understanding these requirements helps node operators select the appropriate OpenMetal configuration.

Render Network
Render Network originally focused on GPU rendering but expanded into AI compute with recent governance proposals. The network serves diverse workloads from 3D rendering to ML inference.
Minimum GPU requirements: RTX 3090 or RTX 4090 series for rendering tasks. A6000 or H100 preferred for AI inference workloads.
Memory requirements: 24GB+ VRAM for most rendering jobs. 48GB+ for complex scenes or AI models.
Storage: 500GB+ SSD for scene files, textures, and intermediate render outputs. NVMe strongly recommended for large projects.
Network: 1Gbps minimum. 10Gbps preferred for transferring large scene files and finished renders.
OpenMetal recommendation: Medium tier (1x A100 40G) for experimenting with the network. Large tier (1x or 2x H100) for reliable earning potential on AI workloads.
Akash Network
Akash operates as a general-purpose cloud marketplace supporting diverse workloads beyond specialized GPU compute. The network has around 150 high-end GPUs (H100/A100) but serves broader computing needs.
Minimum GPU requirements: GTX 1660 or newer. RTX 3000/4000 series for competitive bidding on GPU deployments.
Memory requirements: Varies by deployment. 8GB minimum for entry-level jobs. 48GB+ for serious ML workloads.
Storage: 100GB+ for system and basic deployments. 1TB+ NVMe for data-intensive workloads.
Network: 100Mbps minimum. Faster connectivity increases competitiveness for bandwidth-intensive deployments.
OpenMetal recommendation: Medium tier (1x A100 configurations) provides strong value. Akash’s bidding model rewards cost-competitive providers, and A100s offer excellent performance per dollar.
io.net
io.net specializes in distributed GPU clusters for AI and machine learning. The platform integrated resources from Render, Filecoin, and native providers to create one of the largest DePIN GPU networks. The protocol supports cluster deployment in under two minutes for rapid scaling.
Minimum GPU requirements: A6000 for basic participation. H100 strongly preferred for training workloads and premium pricing tiers.
Memory requirements: 48GB+ VRAM minimum. 80GB+ for competitive advantage on large model training.
Storage: 1TB+ NVMe for model weights, training data, and checkpoints. Multi-TB configurations handle larger datasets.
Network: 10Gbps minimum for cluster participation. Higher bandwidth increases job assignment priority.
OpenMetal recommendation: Large tier (2x H100) or X-Large tier (8x H100) depending on target workload scale. The multi-GPU configurations excel at io.net’s distributed training clusters.
Gensyn
Gensyn focuses specifically on machine learning and deep learning computation using Proof-of-Compute verification. The protocol targets large-scale ML workloads previously accessible only to enterprises with massive compute budgets.
Minimum GPU requirements: H100 strongly preferred for competitive reward rates. A100 acceptable but earns lower per-hour compensation.
Memory requirements: 80GB+ per GPU for training large language models and vision transformers.
Storage: 2TB+ NVMe for datasets, model checkpoints, and training artifacts. Fast storage is critical as training jobs frequently save/load checkpoints.
Network: 10Gbps minimum. Training jobs involve substantial data movement between nodes.
OpenMetal recommendation: X-Large tier (8x H100) provides the compute density Gensyn workloads demand. The high upfront cost amortizes across superior earnings from premium training jobs.
Bittensor
Bittensor operates a decentralized machine learning network where miners contribute compute to train AI models collaboratively. The protocol has over 7,000 miners but competition for subnet validation slots is intense.
Minimum GPU requirements: RTX 4090 for basic subnet participation. A100 or H100 for validator nodes with higher earning potential.
Memory requirements: 32GB+ for most subnets. 80GB+ for validators running larger models.
Storage: Variable by subnet. 1TB+ NVMe recommended for flexibility across different subnet requirements.
Network: Varies significantly by subnet. Some require minimal bandwidth while others need multi-gigabit connections.
OpenMetal recommendation: Large tier (2x H100) for running multiple subnet miners simultaneously. Diversification across subnets reduces variance in daily earnings.
Setting Up A DePIN Node On Bare Metal
Deploying a DePIN compute node on OpenMetal infrastructure follows a standard workflow. The exact steps vary by protocol, but the general pattern remains consistent.
Initial Server Configuration
Start with Ubuntu 22.04 LTS or 24.04 LTS. Most DePIN protocols provide Docker containers or native Linux binaries. Ubuntu ensures maximum compatibility.
Install NVIDIA drivers matching your GPU generation. For H100 and A100 GPUs, driver version 535 or newer is required. Use the NVIDIA driver PPA:
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-driver-550
sudo rebootVerify GPU recognition and driver installation:
nvidia-smiYou should see all GPUs listed with their correct model numbers, memory capacity, and driver version. If GPUs don’t appear or show incorrect specifications, hardware attestation will fail.
Docker Environment
Most DePIN protocols distribute node software as Docker containers. Install Docker and nvidia-container-toolkit:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt update
sudo apt install nvidia-container-toolkit
sudo systemctl restart dockerTest GPU access from Docker:
docker run --rm --gpus all nvidia/cuda:12.3.0-base-ubuntu22.04 nvidia-smiThis should display the same GPU information as running nvidia-smi on the host system.
Protocol-Specific Setup Examples
Each DePIN protocol has unique registration and configuration requirements. Here are detailed setup patterns for major networks:
Render Network Setup Pattern
Render Network requires running benchmark and verification tools before your node becomes active:
# Install Render Network node software (example pattern)
docker pull rendernetwork/node:latest
# Create configuration directory
mkdir -p ~/render-config
cd ~/render-config
# Generate node wallet (follows Render's specific process)
render-cli wallet create
# Run benchmark tool for GPU verification
render-benchmark --gpu all --output benchmark_results.json
# Submit benchmark results to Render Network
render-cli register --benchmark benchmark_results.json \
--wallet-address YOUR_RENDER_WALLET
# Start the node service
docker run -d --name render-node \
--gpus all \
-v ~/render-config:/config \
-p 9090:9090 \
rendernetwork/node:latest \
--wallet /config/wallet.json \
--mode computeRender Network’s verification process measures GPU performance across rendering and compute workloads. The benchmark typically takes 20-45 minutes for multi-GPU configurations. Your node won’t receive jobs until benchmark results are approved by the network.
Akash Network Provider Setup
Akash operates as a bidding marketplace requiring provider configuration and pricing strategies:
# Install Akash provider software
curl -sSfL https://raw.githubusercontent.com/akash-network/provider/main/install.sh | sh
# Configure provider attributes
cat > provider.yaml <<EOF
host: https://provider.yourdomain.com
attributes:
- key: host
value: akash
- key: tier
value: community
- key: region
value: us-west
- key: gpu
value: nvidia-h100
- key: gpu-memory
value: 80gb
pricing:
gpu:
nvidia-h100: 4.50 # USD per hour
memory: 0.0008 # USD per MB per hour
storage: 0.00016 # USD per MB per hour
endpoint: 0.05 # USD per endpoint per hour
EOF
# Start provider service
provider-services run \
--from YOUR_AKASH_WALLET \
--provider provider.yaml \
--chain-id akashnet-2Akash pricing requires strategic thinking. Set rates too high and you won’t win bids. Set them too low and you’re leaving money on the table. Monitor the marketplace to understand competitive pricing for similar hardware.
io.net Cluster Configuration
io.net focuses on rapid cluster deployment for distributed workloads:
# Install io.net worker software
curl -L https://io.net/install.sh | bash
# Register node with verification
io-worker register \
--wallet YOUR_SOLANA_WALLET \
--gpu-type h100 \
--gpu-count 2 \
--region us-west-2
# Run hardware verification
io-worker verify --all-gpus
# Configure cluster participation
cat > io-config.yaml <<EOF
worker:
id: YOUR_WORKER_ID
max_concurrent_jobs: 4
gpu_allocation:
- gpu: 0
reserved: false
- gpu: 1
reserved: false
network:
bandwidth_limit: 10000 # Mbps
public_endpoint: true
EOF
# Start worker service
io-worker start --config io-config.yamlio.net assigns work based on cluster requirements. Nodes with higher availability and faster verification times receive priority for time-sensitive training jobs.
Gensyn Training Node Setup
Gensyn specializes in verifiable machine learning compute:
# Install Gensyn node software (example pattern)
wget https://gensyn.ai/downloads/gensyn-node-latest.tar.gz
tar -xzf gensyn-node-latest.tar.gz
cd gensyn-node
# Configure node identity and resources
./gensyn-node init \
--wallet YOUR_GENSYN_WALLET \
--gpu-ids 0,1,2,3,4,5,6,7 \
--storage-path /mnt/nvme/gensyn \
--max-memory 600 # GB
# Run Proof-of-Compute verification
./gensyn-node verify-compute \
--test-training \
--model resnet50 \
--epochs 10
# Start node in training mode
./gensyn-node start \
--mode training \
--accept-large-models \
--min-job-duration 4hGensyn’s Proof-of-Compute mechanism requires nodes to complete sample training tasks during verification. The protocol checks that you have GPUs and verifies they can actually train models at expected performance levels.
Common Configuration Patterns
Across all protocols, several patterns repeat:
Wallet security is critical. Each protocol requires a wallet for receiving token payments. Store seed phrases offline. Use hardware wallets when possible. Never commit wallet private keys to version control or configuration files.
Resource limits should be configured thoughtfully. Don’t allocate 100% of GPU memory or storage to DePIN workloads. Leave 10-15% headroom for system operations, monitoring, and unexpected spikes.
Network configuration must expose required ports but restrict everything else. Most protocols need one or two TCP ports for job coordination plus ephemeral ports for data transfer. Use UFW to create explicit allow rules rather than opening wide port ranges.
Logging and monitoring should be configured from day one. All protocols provide debug logging modes. Enable them initially, then reduce to info level once stable. Forward logs to centralized logging (Loki, Elasticsearch, or similar) for analysis.
Restart policies ensure nodes recover from crashes. Use systemd services with Restart=always or Docker restart policies. Most protocols tolerate brief interruptions but penalize extended downtime.
Monitoring and Maintenance
DePIN nodes require ongoing monitoring to maintain uptime and verify continuous operation. Set up Prometheus and Grafana for metrics collection:
GPU utilization and temperature to ensure cards remain within safe operating ranges. High temperatures can trigger thermal throttling that reduces performance and causes attestation failures.
Network bandwidth consumption to verify you’re receiving and completing jobs. Unexpectedly low bandwidth might indicate connectivity issues or job assignment problems.
Disk space monitoring is critical. Training jobs can generate large checkpoint files. Running out of disk space mid-job causes failures that damage node reputation.
Protocol-specific metrics vary by network. Render Network tracks completed render jobs and RNDR earnings. Akash shows active leases and AKT rewards. io.net displays cluster assignments and IOT token accumulation.
Error logs require regular review. Failed attestation attempts, rejected jobs, or connectivity errors indicate problems requiring intervention before they impact earnings.
Most protocols include built-in monitoring dashboards accessible through web interfaces. These show node status, earnings history, and any issues requiring attention.
Security Hardening
DePIN nodes hold cryptocurrency wallets and serve as public-facing compute resources. Security is essential:
Firewall configuration should restrict incoming connections to only the ports required by your specific protocol. Use UFW or iptables to create strict rules.
SSH hardening includes disabling password authentication, using key-based auth only, changing default ports, and implementing fail2ban to prevent brute force attempts.
Wallet security demands that private keys are backed up offline and encrypted. Never store wallet private keys in plaintext on the node itself.
Automated updates for security patches should be enabled, but configured to avoid rebooting during active compute jobs. Use unattended-upgrades with careful configuration.
Monitoring for unauthorized access through log analysis tools like fail2ban and regular review of auth.log for suspicious activity.
Economics: When Does Bare Metal Make Sense For DePIN?
The fundamental question for prospective DePIN node operators is whether the economics work. Bare metal servers have monthly costs. DePIN earnings are variable and denominated in crypto tokens. When does the math favor operating a node?
Cost Structure
OpenMetal’s pricing operates on monthly billing with 1-year minimum commitments (3-year pricing shown in this analysis). This predictability is essential for ROI calculations:
Hardware costs are the base monthly rate for your chosen configuration. Unlike public cloud usage-based billing, you pay the same amount regardless of utilization. This favors configurations that can serve multiple DePIN protocols simultaneously to maximize revenue per dollar of fixed cost.
Network bandwidth is included in base pricing. Most DePIN protocols generate significant data transfer, especially for training workloads. Usage-based bandwidth charges on public cloud would add hundreds to thousands per month.
Power and cooling are included. Operating eight H100 GPUs draws 3,500+ watts continuously. At typical retail electricity rates, this costs $250-400/month. OpenMetal’s data center rates and infrastructure are already optimized.
Setup time and labor represent one-time costs. Configuring a node, completing attestation, and debugging any issues typically requires 8-16 hours of engineering time for the first deployment. Subsequent nodes take 2-4 hours each. Value this based on internal hourly rates.
Ongoing maintenance averages 2-4 hours per month per node. Monitoring dashboards, investigating failed jobs, updating software, and optimizing configurations all require attention. Factor this into total operating cost.
Revenue Variables
DePIN earnings vary dramatically based on multiple factors:
Protocol token prices fluctuate with broader crypto markets. A node earning 1,000 RENDER tokens per month generates $6,000 revenue at $6/RENDER but only $3,000 at $3/RENDER. Token price volatility is the single largest earnings variable.
Network utilization determines how much work your node receives. Render Network and io.net currently show 40-70% utilization rates. Newer networks may have lower utilization while building demand. A node can only earn when it’s processing jobs.
Competition and pricing affects earnings in bidding-based protocols like Akash. As more providers join the network, competitive pressure can reduce per-job compensation. Premium hardware commands pricing advantages but doesn’t eliminate competition entirely.
Workload types have different reward rates. Render Network pays more for complex AI inference than simple rendering. io.net training clusters earn premium rates compared to inference workloads. Gensyn compensates based on verified compute contribution.
Node reputation and uptime influence job assignment in most protocols. Nodes with perfect uptime and attestation records receive priority assignment. Failed jobs or prolonged downtime damage reputation and reduce future earnings.
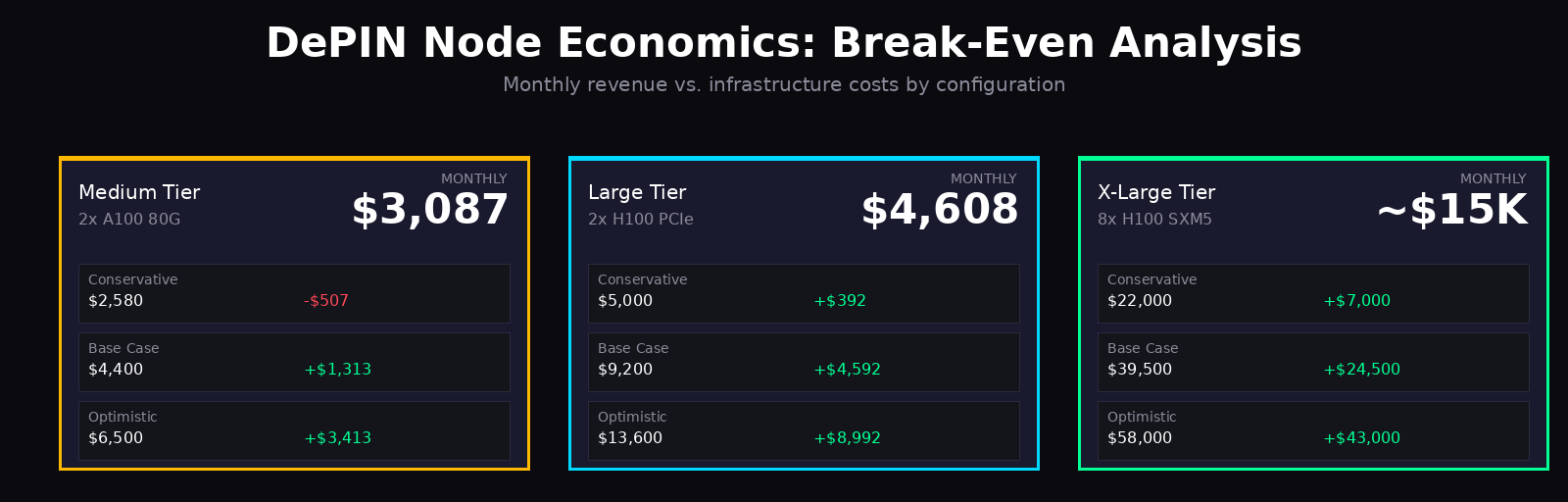
Break-Even Analysis By Configuration
Consider detailed scenarios for each OpenMetal tier:
Medium Tier: 2x A100 80G at $3,087/month
Conservative scenario (30% utilization, moderate token prices):
- Akash Network: 6 hours/day active, $1,680/month
- Render Network: 4 hours/day active, $900/month
- Total monthly revenue: $2,580
- Monthly profit/loss: -$507
- Break-even timeline: Month 8-10 as reputation improves utilization
Base case scenario (50% utilization, stable prices):
- Akash Network: 10 hours/day, $2,400/month
- Render Network: 7 hours/day, $1,600/month
- io.net: 3 hours/day opportunistic, $400/month
- Total monthly revenue: $4,400
- Monthly profit: $1,313
- Annual ROI: 51% on server costs
Optimistic scenario (70% utilization, appreciating tokens):
- Akash Network: 14 hours/day, $3,200/month
- Render Network: 10 hours/day, $2,500/month
- io.net: 5 hours/day, $800/month
- Total monthly revenue: $6,500
- Monthly profit: $3,413
- Annual ROI: 133%
Decision factors: The Medium tier works well for operators who:
- Want to learn DePIN economics with limited risk
- Have engineering time to optimize across protocols
- Can weather 6-12 months of negative or break-even cash flow
- Believe in long-term DePIN growth despite short-term volatility
Medium Tier: 1x A100 40G at $714/month
Conservative scenario (25% utilization):
- Monthly revenue: $600-900 depending on protocol mix
- Likely operates at loss initially
- Best used for learning and experimentation
Base case scenario (45% utilization):
- Monthly revenue: $1,100-1,400
- Monthly profit: $386-686
- Annual ROI: 65-115%
Optimistic scenario (65% utilization):
- Monthly revenue: $1,600-2,000
- Monthly profit: $886-1,286
- Annual ROI: 149-216%
Decision factors: The single A100 40G tier provides:
- Lowest-risk entry point into DePIN
- Good for validating specific protocol requirements
- Limited earning ceiling but also limited downside
- Upgradeable path to larger configurations after validation
Large Tier: 2x H100 PCIe at $4,608/month
Conservative scenario (35% utilization):
- io.net: 6 hours/day, $3,200/month
- Render Network: 4 hours/day, $1,800/month
- Total monthly revenue: $5,000
- Monthly profit: $392
- Break-even or slightly positive from month 1
Base case scenario (55% utilization):
- io.net: 10 hours/day, $5,200/month
- Render Network: 7 hours/day, $2,800/month
- Gensyn: 2 hours/day, $1,200/month
- Total monthly revenue: $9,200
- Monthly profit: $4,592
- Annual ROI: 120%
Optimistic scenario (75% utilization):
- io.net: 14 hours/day, $7,000/month
- Render Network: 10 hours/day, $4,200/month
- Gensyn: 4 hours/day, $2,400/month
- Total monthly revenue: $13,600
- Monthly profit: $8,992
- Annual ROI: 234%
Decision factors: The dual H100 configuration targets operators who:
- Have validated DePIN economics on smaller configurations
- Can commit $55K annually with 6-12 month payback horizon
- Want premium hardware for competitive advantages
- Have bandwidth and engineering resources for multi-protocol optimization
Large Tier: 1x H100 PCIe at $2,995/month
Conservative scenario (30% utilization):
- Monthly revenue: $2,400-3,200
- Monthly profit: -$595 to $205
- Marginal at lower utilization levels
Base case scenario (50% utilization):
- Monthly revenue: $4,000-5,200
- Monthly profit: $1,005-2,205
- Annual ROI: 40-88%
Optimistic scenario (70% utilization):
- Monthly revenue: $5,600-7,200
- Monthly profit: $2,605-4,205
- Annual ROI: 104-168%
Decision factors: The single H100 provides:
- Mid-range risk/reward profile
- H100 performance advantages without dual-GPU costs
- Good for protocols that don’t require multi-GPU
- Easier to achieve profitable utilization than 2x H100
X-Large Tier: 8x H100 SXM5 (Custom Pricing)
Estimating $15,000/month based on hardware value and 3-year commitment:
Conservative scenario (45% utilization):
- Gensyn training: $18,000/month (premium jobs)
- Bittensor validators: $4,000/month
- Total monthly revenue: $22,000
- Monthly profit: $7,000
- Annual ROI: 56%
Base case scenario (60% utilization):
- Gensyn training: $28,000/month
- Bittensor validators: $6,500/month
- io.net premium: $5,000/month
- Total monthly revenue: $39,500
- Monthly profit: $24,500
- Annual ROI: 196%
Optimistic scenario (75% utilization):
- Gensyn enterprise contracts: $40,000/month
- Bittensor top validators: $10,000/month
- io.net reserved capacity: $8,000/month
- Total monthly revenue: $58,000
- Monthly profit: $43,000
- Annual ROI: 344%
Decision factors: The eight-GPU configuration is only appropriate for:
- Operators with proven DePIN success on smaller nodes
- Those able to dedicate engineering resources to optimization
- Access to sufficient capital ($180K+ annual commitment)
- Direct relationships with protocol development teams
- Willingness to accept 12-24 month payback horizons
Sensitivity Analysis: Key Risk Factors
Understanding which variables most impact profitability helps with risk management:
Token price scenarios: A 50% token price decline affects all configurations equally in percentage terms but has different absolute impacts:
- Medium 2x A100: $4,400 revenue drops to $2,200, turning $1,313 monthly profit into $887 monthly loss
- Large 2x H100: $9,200 revenue drops to $4,600, turning $4,592 profit into $8 profit
- X-Large 8x H100: $39,500 revenue drops to $19,750, turning $24,500 profit into $4,750 profit
Premium hardware handles token price volatility better due to higher absolute earnings providing more cushion above fixed costs.
Utilization variance: A 20-percentage-point utilization drop affects profitability differently:
- 50% → 30% utilization: Revenue typically drops 35-45% (non-linear due to reputation effects)
- Higher-end configurations suffer more in absolute dollars but less in percentage terms
- Diversification across protocols reduces utilization variance
Competition pressure: Increasing provider supply reduces per-hour rates by 15-25% in most DePIN networks after 12-18 months:
- Medium 2x A100: Earnings drop from $4,400 to $3,300-3,700, profit from $1,313 to $213-613
- Large 2x H100: Earnings drop from $9,200 to $6,900-7,800, profit from $4,592 to $2,292-3,192
- Premium hardware maintains better margins due to workload specialization
Engineering time costs: If operator time is valued at $150/hour:
- 4 hours/month maintenance = $600 additional cost
- Medium 2x A100 profit drops from $1,313 to $713
- Large 2x H100 profit drops from $4,592 to $3,992
- Consider this carefully when calculating true profitability
Comparative Analysis: Bare Metal vs. Alternatives
How does OpenMetal bare metal compare to other approaches?
vs. Public Cloud GPU Instances
AWS g5.12xlarge (4x A10G GPUs, approximately equivalent to 1x A100):
- On-demand: $5.67/hour = $4,082/month if running 24/7
- Reserved 3-year: ~$2,500/month
- But: Virtualization breaks attestation, likely earns $0 from DePIN
- OpenMetal 1x A100 40G: $714/month + earns $1,100-2,000/month
- Winner: OpenMetal by massive margin due to attestation requirement
vs. Buying Dedicated Hardware
8x H100 server purchase: $300,000 capex
- Colocation: $1,200/month
- Power at wholesale rates: $800/month
- Maintenance and replacement: $400/month
- Total monthly opex: $2,400
- Total annual cost year 1: $300,000 + $28,800 = $328,800
OpenMetal X-Large 8x H100: Est. $15,000/month
- Total annual cost: $180,000
- No capex
Break-even analysis: Owned hardware becomes cheaper after 18 months if you assume zero depreciation and perfect utilization. But:
- H100s will depreciate 40-60% over 3 years as newer GPUs launch
- Hardware failures require capital for replacements
- Opportunity cost of $300K tied up in depreciating assets
- Exit flexibility: OpenMetal allows termination after minimum commitment
Winner: Depends on time horizon and risk tolerance. OpenMetal better for 1-2 year horizons or uncertain DePIN longevity. Owned hardware better for 3+ year horizons with high confidence in continued earnings.
vs. Consumer Hardware at Home
8x RTX 4090 gaming PCs: ~$40,000 purchase
- Residential electricity: $600/month (assuming $0.12/kWh)
- Internet upgrades: $100/month
- Total monthly: $700
Seems cheaper than OpenMetal Medium tier at $3,087/month. But:
- Consumer GPUs earn 30-50% less per hour than datacenter A100/H100
- Residential internet insufficient for serious workloads
- Power outages and uptime issues damage reputation
- Real earnings: $600-1,200/month vs. $2,400-4,400 for datacenter bare metal
Winner: OpenMetal for anyone serious about DePIN as a business. Consumer hardware works only for hobbyist experimentation.
Decision Framework
When should operators choose OpenMetal bare metal for DePIN?
Green light scenarios (bare metal is clearly optimal):
- You’ve validated DePIN economics on test deployment
- You can commit minimum 1 year to learning and optimization
- You have engineering resources for multi-protocol management
- Token price volatility is acceptable with hedging strategies
- You understand this is a crypto-native business with inherent risk
Yellow light scenarios (proceed with caution):
- You’re exploring DePIN for the first time
- Budget is constrained and can’t sustain 6+ months of losses
- Engineering resources are limited (< 4 hours/month available)
- You need guaranteed predictable returns
- Risk tolerance for crypto exposure is low
Red light scenarios (do not proceed):
- You expect guaranteed profits from day one
- You lack technical skills for Linux/Docker/networking troubleshooting
- You cannot commit minimum 1-year contract
- Token price volatility would create financial hardship
- You’re treating this as passive income (it’s not)
Risk Mitigation Strategies
Operators who succeed with DePIN employ several risk management approaches:
Start small: Begin with Medium tier 1x A100 40G at $714/month. Validate protocols, learn operations, and prove economics before scaling to larger configurations.
Diversify protocols: Never depend on a single DePIN network. Distribute resources across 3-4 protocols. When one underperforms, others compensate.
Hedge token exposure: Convert 50-60% of earnings to stablecoins monthly. This locks in dollar profits while maintaining upside through remaining token holdings.
Monitor closely: Check dashboards daily. Set up alerts for failures. Early problem detection prevents small issues from becoming reputation-damaging disasters.
Build reserves: Accumulate 3-6 months of server costs in stablecoins before expanding to larger configurations. This provides runway if utilization or token prices decline.
Plan exit scenarios: Know your commitment end date. Make decisions about renewal 60-90 days early based on trailing economics. Don’t let inertia keep you in unprofitable positions.
Real-World DePIN Node Operations: Three Scenarios
Understanding the practical day-to-day of running DePIN nodes helps set realistic expectations. Here are three composite scenarios based on actual node operator experiences:
Scenario 1: Conservative Entry With Medium Tier A100
Configuration: OpenMetal Medium tier, 2x A100 80G, $3,087/month, 3-year commitment
Protocol mix: 60% Akash Network, 30% Render Network, 10% experimentation with emerging protocols
Month 1-3: Learning Curve
Initial deployment took 24 hours including OS installation, driver setup, Docker configuration, and completing attestation for both protocols. First week revealed issues:
The Akash bidding strategy was too aggressive. Pricing GPUs at $5.50/hour won few deployments. Competitive analysis showed successful providers at $4.20-4.80 range. Adjusted pricing and deployment frequency improved.
Render Network jobs failed intermittently due to insufficient local storage. Render nodes cache scene assets and textures. The initial 1TB NVMe filled within two weeks. Implemented automated cleanup scripts to purge old render outputs after 48 hours.
Network bandwidth became constrained during simultaneous large transfers. Akash tenant downloading training data while Render uploaded completed renders saturated the 1Gbps connection. Staggered job scheduling improved throughput.
Month 4-6: Optimization
Akash utilization stabilized at 45% with optimized pricing. Average earnings: $1,680/month in AKT tokens. Token price volatility created 30% variance month-to-month despite consistent job volume.
Render Network reached 35% utilization averaging 8-10 jobs per day. Earnings: $1,350/month in RENDER tokens. GPU rendering jobs paid better per hour than AI inference initially, but balance shifted as Render’s AI workloads increased.
Total monthly earnings: $3,030 average across three months. Below the $3,087 cost but improving. Node reputation scores increased as uptime records accumulated.
Month 7-12: Steady State
Akash utilization improved to 55% as reputation enabled winning better deployments. Monthly earnings increased to $2,100.
Render Network hit 50% utilization with expanded AI inference work. Monthly earnings: $1,900.
Added experimental participation in io.net during off-peak hours when neither Akash nor Render had jobs queued. This captured an additional $300-500/month from otherwise idle GPU time.
Year 1 economics: Total revenue $51,200, server costs $37,044, net profit $14,156. ROI: 38.2% on server costs. Operator time: 4 hours/month average for monitoring and optimization.
Lessons learned: Diversification across protocols dramatically reduced idle time. Conservative pricing on Akash lost early opportunities but provided stability. Token price volatility meant month-to-month cash flow varied 40% despite consistent job volume. Converting 50% of earnings to USDC monthly provided stable operating cash while retaining upside exposure.
Scenario 2: Aggressive Scaling With Large Tier H100s
Configuration: OpenMetal Large tier, 2x H100 PCIe, $4,608/month, initially 1-year commitment
Protocol mix: 50% io.net training clusters, 30% Render Network AI, 20% Gensyn experimental
Month 1-3: Fast Growth
Premium H100 hardware enabled immediate participation in high-value workloads. io.net assigned training clusters within hours of verification completion. First week earnings: $1,800.
Initial strategy focused exclusively on io.net. The protocol’s 2-minute cluster deployment matched well with H100 performance capabilities. Week 2-4 averaged $1,600-2,000 weekly.
Month 2 revealed problems. IO token price dropped 35% due to broader crypto market weakness. Dollar-denominated earnings fell from $7,200 in month 1 to $4,700 in month 2 despite identical job volume.
Diversification became urgent. Added Render Network targeting their expanding AI inference workloads. H100s commanded premium rates ($8-12/hour) compared to A100 competition ($5-7/hour).
Month 4-6: Crisis and Recovery
IO token continued declining. Month 4 earnings from io.net: $3,200. Render Network provided stability with $2,400 in RENDER tokens that held value better.
Experimented with Gensyn training jobs. These paid well ($10-15/hour equivalent) but verification requirements were strict. 20% of submitted jobs failed verification due to checkpoint corruption during long training runs. Root cause: NVMe drive experiencing errors under sustained write loads.
Replaced failing NVMe drive under warranty. Gensyn verification success rate improved to 95%. Average Gensyn earnings: $1,800/month.
Month 7-12: Maturity
IO token stabilized and began recovery. Month 9-12 io.net earnings: $5,500/month average.
Render Network hit 60% utilization as their AI workloads expanded. H100 performance advantage meant premium job assignment. Monthly earnings: $3,200.
Gensyn reached 25% utilization as the protocol’s user base grew. Monthly earnings: $2,100.
Year 1 economics: Total revenue $92,400, server costs $55,296, net profit $37,104. ROI: 67.1%. Operator time: 8 hours/month including active protocol optimization and token management.
Lessons learned: Premium hardware commanded premium rates but created heavier dependence on specific protocol health. Token price volatility was the dominant risk factor exceeding protocol utilization variance. Gensyn’s strict verification caught actual hardware issues that would have caused problems on other protocols later. Multiple NVMe drives in RAID 10 eliminated single points of failure for checkpoint-heavy training workloads.
Scenario 3: Enterprise-Scale X-Large Deployment
Configuration: OpenMetal X-Large tier, 8x H100 SXM5, custom pricing (contact OpenMetal), 3-year commitment negotiated upfront
Protocol mix: 70% Gensyn large-scale training, 20% Bittensor subnet validators, 10% io.net premium clusters
Month 1-3: Dedicated Setup
Eight-GPU configuration with NVLink required careful engineering. Each GPU can exchange data with others at 900 GB/s, but this only works with proper topology configuration and driver setup.
Worked directly with Gensyn’s technical team to optimize for their largest training jobs. These require multi-day runs with terabytes of data movement between GPUs. Standard configurations caused bottlenecks.
Initial attestation took 8 hours. Gensyn’s verification process for 8-GPU clusters is substantially more rigorous than single or dual-GPU nodes. The protocol wants proof that all NVLink connections work correctly and that the full 640GB of HBM3 is accessible at full bandwidth.
First large training job: $4,200 for 36 hours of work training a 70B parameter model. This single job paid 25% of monthly server costs.
Month 4-6: Specialization Pays Off
Gensyn’s larger customers began specifically requesting 8-GPU nodes for multi-day training runs. These paid premium rates ($12-18/hour per GPU) due to the specialized hardware requirements and limited provider supply.
Average Gensyn utilization: 65% across all 8 GPUs. Jobs ran nearly continuously with brief gaps for attestation between assignments. Monthly earnings: $28,000-32,000 in GENSYN tokens (pre-launch testnet credits convertible to tokens at mainnet).
Added Bittensor subnet validators using 2 GPUs each, allowing 4 simultaneous subnet positions. Subnet earnings varied dramatically by subnet selection. Best performer earned $2,800/month. Worst earned $400/month. Total Bittensor: $6,400/month average.
io.net premium clusters (requiring 6+ GPUs with NVLink) provided sporadic high-value work. These weren’t available daily but paid extremely well when they appeared. Monthly average: $4,200.
Month 7-12: Stable Operations
Gensyn launched mainnet in month 8. Testnet credits converted to tokens at favorable rates. Continued utilization around 60-70% with premium job assignment due to proven track record.
Optimized Bittensor subnet selection after 6 months of data. Focused on 2-3 high-performing subnets, abandoned low performers. This increased Bittensor contribution to $8,500/month.
io.net premium clusters became more frequent as the protocol’s enterprise customers ramped up. These jobs often involved multi-week engagements training proprietary models. Monthly average increased to $7,200.
Year 1 economics: Total revenue $387,000, estimated server costs $180,000 (custom configuration), net profit $207,000. ROI: 115% on server costs. Operator time: 12 hours/month including detailed performance optimization and close coordination with protocol technical teams.
Lessons learned: Eight-GPU configurations address fundamentally different market segments than dual-GPU nodes. The work scales beyond simple multiples—multi-day training runs and enterprise customers with specialized requirements demand qualitatively different capabilities. Premium hardware justifies premium pricing but requires active engagement with protocol development teams. Having allocated $180K annually to server costs, the operation needed $200K+ revenue to justify the investment and risk. Achieving this required both premium hardware and operator expertise in optimization. Bittensor subnet selection was more important than raw GPU performance for that portion of revenue.
Common Pitfalls And How To Avoid Them
Node operators make predictable mistakes when entering DePIN. Learning from others’ experiences accelerates success:
Underestimating Token Price Volatility
The mistake: Operators calculate break-even based on current token prices. They assume that earning 1,000 RENDER tokens at $6/token ($6,000/month) will continue indefinitely.
Reality: RENDER dropped from $6 to $3.20 (-47%) during 2024’s crypto downturn. IO token experienced 60% drawdowns. Even “stable” protocols see 30-40% monthly volatility.
Impact: Nodes that appeared profitable at $6,000/month earnings barely broke even at $3,200. Operators who hadn’t hedged position faced cash flow crises.
Solution: Convert 40-60% of earned tokens to stablecoins monthly. This locks in dollar-denominated profits. Hold remaining tokens for upside exposure if comfortable with volatility. Calculate break-even scenarios at 50% of current token prices to build in safety margin.
Over-Committing To Single Protocols
The mistake: Operators configure nodes for maximum performance on one protocol, making migration to alternatives difficult or impossible.
Reality: DePIN protocols are experimental. Networks can lose users, experience technical problems, or face competition that reduces earnings. Render Network’s focus pivoted from pure rendering to AI compute. Akash’s utilization varies by 40% quarter-to-quarter. io.net faced scrutiny over verification accuracy.
Impact: Node operators optimized exclusively for Render’s rendering workloads found their specialized configurations less valuable when the protocol shifted toward AI. Those locked into 3-year contracts on expensive hardware faced limited recourse.
Solution: Configure infrastructure to serve multiple protocols simultaneously. Most GPU workloads have similar hardware requirements. Docker containers enable rapid protocol switching. Design monitoring to track each protocol’s earnings and utilization independently. Shift resources toward whichever networks prove most profitable.
Ignoring Attestation Maintenance
The mistake: Operators assume that once initial attestation passes, ongoing verification is automatic and trouble-free.
Reality: Attestation mechanisms check hardware health continuously or periodically. GPU thermal throttling, driver issues, NVMe failures, and network problems all cause verification failures. Some protocols reduce reward rates or disable nodes after repeated failures.
Impact: A node that passes initial verification but develops GPU overheating issues will fail subsequent attestation checks. Reward rates drop or stop entirely. Node reputation suffers, affecting job assignment even after fixing the issue.
Solution: Monitor attestation logs actively. Most protocols provide detailed logging showing verification results. Set up alerts for failures. Investigate immediately rather than assuming issues are temporary. Common problems: GPU thermal paste degradation (reapply every 12-18 months), driver version incompatibilities (stay on LTS releases), and NVMe wear-out (monitor SMART data).
Inadequate Storage Provisioning
The mistake: Operators provision minimal storage based on protocol documentation’s “minimum requirements”.
Reality: Training jobs generate massive checkpoint files. Render jobs cache large scene assets. Logs accumulate. What starts as 500GB available shrinks to zero within weeks of active operation.
Impact: Jobs fail mid-execution when storage fills. Protocols penalize incomplete work. Node operators scramble to expand storage, often involving downtime that damages reputation.
Solution: Provision 3-5x the documented storage minimums. For multi-GPU training workloads, expect 2TB+ actively utilized. Implement automated cleanup policies that purge completed job artifacts after 72 hours. Monitor disk usage hourly with alerts at 70% full.
Neglecting Network Performance
The mistake: Operators assume that having a 1Gbps connection is sufficient because protocol requirements list “1Gbps minimum”.
Reality: Training jobs transfer datasets measured in hundreds of gigabytes. Render outputs can be tens of gigabytes for complex scenes. Multiple simultaneous jobs quickly saturate bandwidth.
Impact: Slow uploads cause job timeouts. Protocols penalize nodes that can’t complete data transfers within expected timeframes. Effective utilization drops as nodes spend hours transferring data instead of computing.
Solution: Oversubscribe bandwidth by 2-3x for multi-GPU configurations. Use 10Gbps connections when running more than 2 high-end GPUs. Monitor actual bandwidth utilization along with connectivity speed. Implement QoS rules to prioritize job data transfers over monitoring traffic.
The fundamental question for prospective DePIN node operators is whether the economics work. Bare metal servers have monthly costs. DePIN earnings are variable and denominated in crypto tokens. When does the math favor operating a node?
Cost Structure
OpenMetal’s pricing operates on monthly billing with 1-year minimum commitments (3-year pricing shown in this analysis). This predictability is essential for ROI calculations:
Hardware costs are the base monthly rate for your chosen configuration. Unlike public cloud usage-based billing, you pay the same amount regardless of utilization. This favors configurations that can serve multiple DePIN protocols simultaneously to maximize revenue per dollar of fixed cost.
Network bandwidth is included in base pricing. Most DePIN protocols generate significant data transfer, especially for training workloads. Usage-based bandwidth charges on public cloud would add hundreds to thousands per month.
Power and cooling are included. Operating eight H100 GPUs draws 3,500+ watts continuously. At typical retail electricity rates, this costs $250-400/month. OpenMetal’s data center rates and infrastructure are already optimized.
Setup time and labor represent one-time costs. Configuring a node, completing attestation, and debugging any issues typically requires 8-16 hours of engineering time for the first deployment. Subsequent nodes take 2-4 hours each. Value this based on internal hourly rates.
Ongoing maintenance averages 2-4 hours per month per node. Monitoring dashboards, investigating failed jobs, updating software, and optimizing configurations all require attention. Factor this into total operating cost.
Revenue Variables
DePIN earnings vary dramatically based on multiple factors:
Protocol token prices fluctuate with broader crypto markets. A node earning 1,000 RENDER tokens per month generates $6,000 revenue at $6/RENDER but only $3,000 at $3/RENDER. Token price volatility is the single largest earnings variable.
Network utilization determines how much work your node receives. Render Network and io.net currently show 40-70% utilization rates. Newer networks may have lower utilization while building demand. A node can only earn when it’s processing jobs.
Competition and pricing affects earnings in bidding-based protocols like Akash. As more providers join the network, competitive pressure can reduce per-job compensation. Premium hardware commands pricing advantages but doesn’t eliminate competition entirely.
Workload types have different reward rates. Render Network pays more for complex AI inference than simple rendering. io.net training clusters earn premium rates compared to inference workloads. Gensyn compensates based on verified compute contribution.
Node reputation and uptime influence job assignment in most protocols. Nodes with perfect uptime and attestation records receive priority assignment. Failed jobs or prolonged downtime damage reputation and reduce future earnings.
Break-Even Analysis
Consider the Medium tier 2x A100 configuration at $3,087/month (3-year commitment):
Conservative scenario assumes 30% network utilization and moderate token prices. The node processes jobs 8-10 hours per day. Monthly earnings range from $2,000 to $3,500 depending on the specific protocol mix. This scenario loses money initially but breaks even as utilization increases or token prices appreciate.
Base case scenario assumes 50% network utilization with stable token prices. The node actively processes work 12 hours daily. Monthly earnings range from $3,500 to $5,000. This scenario generates $400 to $1,900 monthly profit after covering the $3,087 server cost.
Optimistic scenario assumes 70% utilization with favorable token price movements. The node works 16-18 hours daily serving high-value workloads. Monthly earnings range from $5,500 to $8,000. Monthly profit reaches $2,400 to $4,900.
The Large tier 2x H100 configuration at $4,608/month has similar dynamics but higher earning potential:
Conservative scenario generates $3,500 to $5,000 monthly. Initial operation runs at a loss but provides optionality if network demand increases or protocols launch major initiatives.
Base case scenario generates $5,500 to $8,000 monthly. Monthly profit ranges from $900 to $3,400. The premium hardware commands better per-hour rates across most protocols.
Optimistic scenario generates $8,500 to $13,000 monthly. Profit reaches $3,900 to $8,400. H100s receive priority assignment for the most lucrative training workloads.
The X-Large 8x H100 configuration represents the highest risk and highest reward:
Conservative scenario requires contacting OpenMetal for pricing, but the monthly cost will be substantial given the hardware value. This tier only makes economic sense for operators targeting Gensyn, Bittensor validators, or io.net premium clusters with proven demand.
Base case scenario assumes dedicated focus on high-value training workloads and premium protocol tiers. The compute density allows serving multiple large-scale jobs simultaneously.
Optimistic scenario positions the node as a preferred provider for enterprise-grade DePIN workloads. The eight-GPU configuration with NVLink is required for certain workload types, creating a natural competitive moat.
Risk Mitigation Strategies
The minimum 1-year commitment requirement creates both obligation and opportunity:
Start with monthly billing on 1-year commitment to test protocols and validate earnings assumptions. After 3-6 months of proven profitability, commit to 3-year pricing to reduce monthly cost and improve profit margins.
Diversify across multiple protocols to reduce dependence on any single network’s token price or utilization. A node serving Render, Akash, and io.net simultaneously spreads risk across three revenue streams.
Hedge token price exposure by converting a portion of earned tokens to stablecoins monthly. This locks in profits and reduces volatility. The remaining tokens provide upside exposure if prices appreciate.
Monitor protocol development actively through governance forums, technical updates, and utilization metrics. Early signals of problems (declining usage, developer departures, competitive threats) allow for strategic adjustments before they impact earnings.
Plan for re-deployment flexibility if a protocol becomes unprofitable. Most DePIN node software can be removed and replaced with alternatives within hours. The bare metal hardware remains valuable for any GPU-dependent workload.
Comparison To Self-Owned Hardware
The primary alternative to renting bare metal is purchasing servers outright:
Capital expenditure for an 8x H100 server runs $250,000 to $350,000 depending on configuration and supplier. This represents massive upfront risk if DePIN economics don’t materialize.
Hosting costs for self-owned hardware add $800-1,500 monthly for rack space, power, and bandwidth in a professional data center. Colocation isn’t free.
Depreciation affects hardware value as newer GPU generations launch. H100s maintain value today but will depreciate significantly when H200, B100, or next-generation cards arrive. This represents hidden cost.
Liquidity and exit is poor for specialized GPU servers. Resale markets are thin and prices are negotiable. Exiting a DePIN operation with owned hardware takes months and recovers only 40-60% of initial capital.
Opportunity cost of $250,000-350,000 in capital is substantial. At 5% annual return, that’s $12,500-17,500 yearly in foregone investment returns.
Operational complexity increases with owned hardware. You’re responsible for hardware failures, upgrades, data center relationships, and all technical logistics.
Renting bare metal from OpenMetal eliminates upfront capital requirements and provides exit flexibility. If DePIN earnings don’t meet expectations, you can terminate the commitment after the minimum period and redeploy capital elsewhere. This optionality has real value when entering emerging crypto-native markets with unproven economics.
Alternative Approaches and Their Limitations
Some prospective DePIN operators consider hybrid approaches or alternative configurations. These rarely work well in practice:
Spot Instances and Preemptible VMs
Public cloud spot instances offer significant discounts (60-90% off on-demand pricing) in exchange for interruptible availability. This seems appealing for DePIN workloads, but creates critical problems:
Attestation failures from instance termination mid-verification damage node reputation across all protocols. Most DePIN networks track historical reliability and penalize nodes with poor uptime records.
Lost work and wasted compute occurs when training jobs get interrupted. Many DePIN protocols have minimum job completion requirements. Failing to complete accepted work forfeits compensation entirely.
Inconsistent hardware across different spot instance launches breaks protocol expectations. Your node might pass attestation with one hardware configuration then fail after automatic relaunch with different underlying GPUs.
Desktop and Consumer Hardware
Some operators attempt to run DePIN nodes on gaming PCs or workstations:
Uptime requirements conflict with personal usage. Most DePIN protocols expect 95%+ availability. Using the computer for other tasks creates conflicts.
Residential internet has insufficient upload bandwidth for many workloads. Training jobs and render outputs require symmetric multi-gigabit connectivity.
Power reliability is poor in residential settings. Brief power outages that trigger desktop reboots cause reputation damage on DePIN networks expecting commercial-grade uptime.
Security concerns increase when DePIN wallets exist on daily-use computers. Personal browsing, email, and application usage create attack surfaces for wallet theft.
Consumer hardware can work for small-scale experimentation and learning protocol requirements. It’s not viable for commercial-scale DePIN operations with earnings goals.
Hybrid Cloud Plus On-Premises
Some larger operators run primary nodes on owned hardware while using bare metal rentals for capacity expansion:
Protocol diversity works well in this model. Owned hardware serves stable, proven protocols while bare metal rentals test emerging networks with uncertain economics.
Geographic distribution can be achieved by combining on-premises hardware in one location with bare metal in strategically different regions. Some DePIN protocols reward geographic diversity.
Risk management improves by avoiding 100% capital commitment to owned hardware while maintaining optionality through rentals.
This approach works best for operators already experienced with DePIN economics and ready to scale beyond initial experiments.
The Future Of DePIN And Infrastructure Requirements
DePIN represents a fundamental shift in how computing resources get allocated and compensated. The movement from centralized cloud giants toward decentralized resource networks has significant implications for infrastructure providers like OpenMetal.
Growing Protocol Diversity
The DePIN ecosystem currently focuses heavily on GPU compute because that’s where demand and token incentives are strongest. But broader infrastructure categories are emerging:
Storage DePINs like Filecoin and Arweave provide decentralized alternatives to S3 and cloud storage. These require fast disk I/O, large capacity, and reliable networking rather than GPUs.
CDN and bandwidth networks like Fleek and Sia monetize unused bandwidth through token incentives. These need strategic geographic positioning and multi-gigabit symmetrical connections.
Specialized compute for specific industries may emerge. Medical imaging analysis, financial modeling, scientific simulation, and other verticals could develop dedicated DePIN protocols with industry-specific hardware requirements.
Hybrid resource networks that combine compute, storage, and bandwidth into unified marketplaces will need infrastructure that can serve multiple resource types from single servers.
OpenMetal’s bare metal platform can support all these categories. The fundamental value proposition remains: hardware verification and attestation require direct physical access that virtualization cannot provide.
Attestation Technology Evolution
Current DePIN attestation mechanisms are relatively undeveloped compared to what’s technically possible:
Trusted execution environments like Intel TDX and AMD SEV provide hardware-level isolation and cryptographic attestation. Future protocols may require TEE-capable processors for node participation.
Zero-knowledge proofs could enable verification of compute work without revealing sensitive details about jobs or data. This would unlock DePIN usage for confidential workloads like healthcare AI and financial analysis.
Continuous monitoring through hardware telemetry and on-chain verification may replace periodic attestation. Nodes would constantly prove their capability and availability rather than passing occasional checkpoint verifications.
Specialized verification chips designed explicitly for DePIN attestation could emerge. These would combine cryptographic acceleration, secure key storage, and tamper-resistant hardware measurement.
All these advances build on bare metal’s foundation of direct hardware access. Virtualization’s abstraction layer remains fundamentally incompatible with cryptographic hardware attestation.
Economic Maturation
Early-stage DePIN networks currently show relatively low utilization (40-70%) as demand ramps up. This will change as protocols mature:
Enterprise adoption of DePIN for production workloads requires reliability, SLAs, and consistent capacity. Protocols that achieve this milestone will see utilization approach 90%+ as major customers commit to decentralized infrastructure.
Commoditization pressure will reduce per-hour compensation as supply increases. Early movers earn premium rates while later entrants face tighter margins. This favors efficient operators with low overhead costs.
Protocol consolidation seems likely as the ecosystem matures. Many current DePIN networks have similar value propositions. Market forces will favor protocols with best economics, strongest community, and most enterprise adoption.
Vertical specialization may create DePIN networks optimized for specific workload types. A protocol focused exclusively on LLM inference could outcompete general-purpose networks on those workloads through better optimization and pricing.
Operators who understand these dynamics and position infrastructure appropriately will capture disproportionate value.
Getting Started With DePIN On OpenMetal
The path from concept to earning DePIN node is straightforward but requires upfront planning:
Step 1: Research Protocol Requirements
Before committing to infrastructure, validate which protocols best match your goals:
Technical compatibility varies significantly. Some protocols need cutting-edge H100s while others work fine with older A100 or even RTX consumer cards.
Economic projections require analyzing current utilization rates, token prices, and competitive dynamics. Join protocol Discord servers and talk to active node operators about real earnings.
Commitment requirements differ across networks. Some protocols have minimum stake requirements or vesting periods before you can withdraw earnings. Understand these before starting.
Geographic considerations matter for some networks. Render Network and io.net distribute work globally but may have regional capacity imbalances affecting job assignment frequency.
Step 2: Select OpenMetal Configuration
Based on protocol requirements and budget, choose appropriate hardware:
Conservative entry with Medium tier (1x A100 40G) at $714/month provides hands-on experience with DePIN economics at minimal financial commitment. This validates the concept before scaling up.
Balanced approach using Large tier (2x H100) at $4,608/month targets serious operations with meaningful earnings potential. The dual-GPU configuration serves diverse workload types effectively.
Premium positioning with X-Large tier (8x H100) requires contacting OpenMetal for custom configurations. This tier targets operators pursuing maximum compute density for Gensyn, Bittensor validators, or io.net premium clusters.
All configurations require minimum 1-year commitments with monthly billing. The 3-year pricing shown reduces monthly cost but increases total obligation.
Step 3: Initial Deployment and Testing
After server provisioning, systematically validate the complete stack:
Hardware verification confirms all GPUs appear correctly in nvidia-smi with expected memory capacity and compute capability.
Driver installation and CUDA toolkit setup ensure protocols can access GPU compute functions.
Protocol installation following official documentation for your chosen networks. Most provide Docker images or installation scripts.
Attestation completion proving your hardware to each protocol. This initial verification often takes longer than future periodic checks.
First job completion validates the entire pipeline from job assignment through execution to reward distribution.
Budget 16-24 hours for initial deployment including learning curve and troubleshooting. Subsequent nodes deploy much faster once you understand the patterns.
Step 4: Production Operations
Once validated, shift to optimized operations:
Monitor daily for job assignment, earnings accumulation, and any attestation failures or errors.
Optimize protocol mix based on real utilization and compensation. If one protocol consistently assigns more profitable work, allocate more resources there.
Track token prices and convert strategic portions to stablecoins based on your risk tolerance and cash flow needs.
Engage with protocol communities through Discord, forums, and governance discussions. Early awareness of network changes, upgrades, or issues helps you adapt quickly.
Expand methodically by adding additional nodes or protocols after validating profitability on initial deployment. Resist the urge to scale prematurely before proving unit economics.
Step 5: Continuous Optimization
Mature operations focus on margin improvement:
Utilize multiple protocols per node to maximize hardware utilization. Many servers sit idle 30-40% of the time serving a single protocol. Running multiple DePIN networks simultaneously captures more revenue from the same fixed cost.
Automate monitoring and alerting so you know immediately when problems arise rather than discovering issues days later when reputation is already damaged.
Track detailed economics including server costs, token earnings at time of receipt, appreciation or depreciation of token holdings, and true all-in profitability.
Build protocol-specific expertise to optimize configurations, bid pricing (for Akash), and workload selection for maximum yield.
Consider 3-year commitment after 6-12 months of proven profitability to reduce monthly server costs and improve margins.
Troubleshooting Common DePIN Node Issues
Even well-configured nodes encounter problems. Rapid diagnosis and resolution minimize lost earnings and reputation damage:
Attestation Failures
Symptom: Node passes initial verification but fails periodic attestation checks. Dashboard shows “verification pending” or “hardware check failed” status.
Diagnosis process:
Check GPU visibility first. Run nvidia-smi and verify all GPUs appear with correct model numbers and memory capacity. If GPUs are missing or show incorrect specs, the problem is at the driver or hardware level.
Review attestation logs. Most protocols log detailed information about verification attempts. Look for specific failures like “benchmark timeout,” “memory allocation failed,” or “performance below threshold.”
Test GPU compute capability directly using CUDA samples:
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQueryThis reports comprehensive GPU properties. Compare against protocol requirements.
Common causes and fixes:
GPU thermal throttling occurs when cards exceed temperature thresholds (typically 83-89°C for most NVIDIA GPUs). Check temperatures under load:
nvidia-smi dmon -s pucvmet -c 100If temperatures consistently exceed 80°C during jobs, investigate cooling. Clean dust from server intakes. Verify all fans operate. For sustained high temperatures, GPU thermal paste may need replacement.
Driver version incompatibility happens when protocols update requirements but nodes run old drivers. Check your driver version:
nvidia-smi | grep "Driver Version"Compare against protocol documentation. Upgrade if necessary:
sudo apt install nvidia-driver-550 # Or required version
sudo rebootInsufficient VRAM causes failures when protocols attempt to allocate more memory than available. This typically shows as “out of memory” errors in logs. If other processes are using GPU memory, kill them. If the GPU genuinely lacks capacity for protocol requirements, you may need different hardware.
PCIe link width degradation reduces bandwidth between GPU and CPU. Check PCIe status:
nvidia-smi -q | grep -A 10 "PCIe"Look for “Current Link Width” and “Max Link Width.” They should match (typically x16). If current width is lower (x8, x4), the GPU may be poorly seated or the PCIe slot has issues. Power down, reseat the GPU, and restart.
Job Assignment Gaps
Symptom: Node shows as online and verified but receives few or no jobs despite other operators reporting high utilization.
Diagnosis process:
Check node reputation score in the protocol’s dashboard or explorer. Low reputation from previous failures reduces job assignment priority.
Verify pricing competitiveness for bidding-based protocols like Akash. If your rates are significantly above market, you won’t win deployments.
Confirm geographic and workload type settings. Some protocols route jobs based on node location or capabilities. Overly restrictive filters limit opportunities.
Common causes and fixes:
Damaged reputation from past failures or downtime takes time to repair. Continue operating reliably for 2-4 weeks. Most protocols weight recent uptime heavily, allowing recovery from historical issues.
Non-competitive pricing requires market research. Check what similar hardware configurations charge on your protocol’s marketplace. For Akash, query active providers:
akash query market lease list --state activeAnalyze lease prices for comparable GPU types. Adjust your pricing to within 10-15% of median rates.
Network connectivity issues may prevent job assignment even if the node shows online. Test connectivity from external networks:
nc -zv YOUR_PUBLIC_IP YOUR_PROTOCOL_PORTIf this fails, check firewall rules, port forwarding, and cloud/datacenter security groups.
Resource constraints during peak hours cause protocols to skip over nodes that appear busy. If you’re running multiple protocols, implement resource reservation to guarantee availability for each network.
Performance Degradation
Symptom: Node was earning consistently but performance metrics decline over weeks or months. Jobs take longer to complete or fail more frequently.
Diagnosis process:
Monitor GPU clock speeds during workloads:
watch -n 1 nvidia-smiCompare current clock speeds against the GPU’s base and boost specifications. Significant reductions indicate throttling.
Check NVMe performance for storage-intensive workloads:
sudo fio --name=random-write --ioengine=libaio --iodepth=32 \
--rw=randwrite --bs=4k --direct=1 --size=4G --numjobs=4 \
--runtime=60 --group_reporting --filename=/mnt/nvme/testCompare against baseline performance from initial deployment. IOPS reductions of 30%+ indicate drive wear or failure.
Review system logs for hardware errors:
sudo dmesg | grep -i error
sudo journalctl -p err -bGPU ECC errors, PCIe AER errors, or SATA/NVMe controller errors indicate hardware problems requiring attention.
Common causes and fixes:
Thermal paste degradation on GPUs reduces heat transfer efficiency. Temperatures gradually increase over 12-24 months, triggering thermal throttling. This is normal wear and tear. Replace thermal paste or have the server vendor perform maintenance.
NVMe wear-out affects SSDs after extensive writes. Check SMART data:
sudo smartctl -a /dev/nvme0n1 | grep -E "Percentage Used|Data Units Written"“Percentage Used” approaching 80-90% indicates the drive is nearing end-of-life. Plan replacement before it fails completely.
Insufficient cooling from dust accumulation is extremely common in datacenter environments. Even filtered air contains particles. After 6-12 months, heatsinks and intakes accumulate enough dust to impair cooling. Schedule preventive maintenance every 6 months to clean the system.
Driver memory leaks occasionally cause performance degradation. Some NVIDIA driver versions have bugs where GPU memory isn’t properly freed after jobs complete. Check memory usage:
nvidia-smi --query-gpu=memory.used --format=csvIf memory usage creeps up over time despite no active jobs, restart the node service or, as a last resort, reboot the server.
Network Connectivity Problems
Symptom: Jobs start but fail during data transfer phases. Logs show timeouts, connection resets, or incomplete transfers.
Diagnosis process:
Test bandwidth to protocol-specific endpoints:
iperf3 -c protocol.endpoint.example.com -P 10 -t 60Many protocols provide test endpoints for bandwidth verification. Results should match your connection’s rated capacity (within 10-15%).
Check for packet loss on your network path:
mtr -n -c 100 protocol.endpoint.example.comLook for packet loss percentage. Anything above 1% indicates problems. 5%+ is severe and will cause job failures.
Monitor real-time connections during job execution:
watch -n 1 'netstat -an | grep ESTABLISHED | grep YOUR_PROTOCOL_PORT'High numbers of TIME_WAIT or FIN_WAIT connections indicate problems cleanly closing connections.
Common causes and fixes:
ISP routing issues cause intermittent connectivity problems. If mtr shows packet loss at specific hops outside your control, contact OpenMetal support. They may be able to adjust routing or work with upstream providers.
Firewall connection tracking exhaustion happens when connection tracking tables fill. Check current connections:
sudo conntrack -CCompare against the maximum:
cat /proc/sys/net/nf_conntrack_maxIf usage approaches maximum, increase the limit:
echo 262144 | sudo tee /proc/sys/net/nf_conntrack_maxDDoS protection false positives from datacenter infrastructure sometimes throttle legitimate DePIN traffic when protocols generate high connection counts. Work with OpenMetal support to allowlist protocol IP ranges if this occurs.
TCP tuning for high-bandwidth transfers may be necessary. Default Linux TCP parameters work poorly for 10Gbps+ connections. Optimize:
cat >> /etc/sysctl.conf <<EOF
net.core.rmem_max = 536870912
net.core.wmem_max = 536870912
net.ipv4.tcp_rmem = 4096 87380 536870912
net.ipv4.tcp_wmem = 4096 65536 536870912
net.ipv4.tcp_congestion_control = bbr
EOF
sudo sysctl -pProtocol-Specific Issues
Different DePIN networks have unique failure modes:
Render Network: Scene cache corruption causes repeated job failures on the same render tasks. Clear the cache directory and re-download scene assets. Configure automated cache cleanup to prevent recurrence.
Akash Network: Deployment failures with “insufficient resources” errors despite available capacity usually indicate Docker resource limits are too restrictive. Review deployment manifests and adjust CPU/memory limits.
io.net: Cluster formation failures when your node can’t connect to other cluster members typically indicate firewall issues. io.net uses dynamic port ranges for inter-node communication. Ensure your firewall allows outbound connections on all ports.
Gensyn: Training job verification failures after multi-day runs often result from checkpoint corruption during power events or kernel panics. Implement battery backup (UPS) and configure aggressive checkpoint frequency reduction if verification failures are frequent.
Bittensor: Subnet sync failures indicate your node can’t keep up with blockchain state. This typically happens with insufficient CPU or slow disk I/O. Consider dedicated SSD for blockchain data separate from model storage.
Advanced Optimization Techniques
Experienced operators employ sophisticated strategies to maximize earnings per dollar of infrastructure cost:
Multi-Protocol Resource Scheduling
The challenge: Different protocols need different resources at different times. Running multiple DePIN networks on the same hardware risks resource conflicts but dramatically increases utilization.
Implementation strategy:
Create resource pools for each protocol:
# docker-compose.yml for multi-protocol node
version: '3.8'
services:
render-node:
image: rendernetwork/node:latest
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
limits:
memory: 32G
volumes:
- /mnt/nvme1/render:/data
akash-provider:
image: akash/provider:latest
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['1']
capabilities: [gpu]
limits:
memory: 32G
volumes:
- /mnt/nvme2/akash:/data
ionet-worker:
image: ionet/worker:latest
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0', '1']
capabilities: [gpu]
limits:
memory: 64G
profiles:
- off-peak
volumes:
- /mnt/nvme3/ionet:/dataThis configuration dedicates GPU 0 to Render, GPU 1 to Akash, but allows io.net to use both during off-peak hours when the others are idle.
Implement priority-based scheduling using custom orchestration:
#!/usr/bin/env python3
import docker
import time
client = docker.from_env()
GPU_UTILIZATION_THRESHOLD = 70 # percent
def get_gpu_utilization():
# Query nvidia-smi for current GPU usage
# Return dict of {gpu_id: utilization_percent}
pass
def adjust_protocol_allocation():
util = get_gpu_utilization()
# If GPUs are underutilized, activate io.net
if all(u < GPU_UTILIZATION_THRESHOLD for u in util.values()):
client.containers.get('ionet-worker').start()
else:
try:
client.containers.get('ionet-worker').stop()
except:
pass
while True:
adjust_protocol_allocation()
time.sleep(300) # Check every 5 minutesThis simple orchestrator activates io.net only when primary protocols aren’t fully utilizing GPUs.
Geographic Arbitrage
Some DePIN protocols pay different rates based on provider location. Others route jobs based on proximity to users.
Strategy:
Research protocol-specific geographic incentives. Render Network’s job distribution favors North American and European nodes because that’s where most customers are located. io.net offers bonuses for underserved regions.
Consider multiple deployments in strategic locations:
- Primary node in major tech hub (US-West, US-East, EU-West) for maximum job flow
- Secondary node in emerging region with protocol incentives
- Edge node for latency-sensitive protocols near underserved user populations
OpenMetal’s data center locations enable this strategy. Compare job assignment rates and pricing across regions before committing to multi-site deployments.
Token Management Strategies
Token earnings require active management to optimize returns:
Immediate conversion: Convert 100% of earnings to stablecoins daily. This eliminates price risk but foregoes potential appreciation. Appropriate for risk-averse operators treating DePIN as pure cash flow business.
Threshold rebalancing: Hold tokens until they reach 30-40% of monthly costs, then convert the excess. This maintains working capital cushion while allowing appreciation. Balances risk and opportunity.
Strategic holding: Convert only enough to cover monthly costs, hold the rest. This maximizes upside if tokens appreciate but creates cash flow risk if prices decline. Only appropriate for operators who can weather significant volatility.
Options strategies: Some DePIN tokens have liquid options markets. Selling covered calls against token holdings generates additional income while capping upside. This is advanced territory requiring options trading expertise.
Implement automated token management:
#!/usr/bin/env python3
import requests
from web3 import Web3
# Configuration
CONVERSION_THRESHOLD = 5000 # USD equivalent
WALLET_ADDRESS = "your_wallet"
STABLECOIN_TARGET = 0.4 # 40% of holdings in stablecoins
def check_token_balance():
# Query blockchain for current token balance
pass
def get_token_price():
# Fetch current price from DEX or exchange API
pass
def swap_to_stablecoin(amount):
# Execute swap via DEX (Uniswap, Jupiter, etc.)
pass
def rebalance_portfolio():
balance = check_token_balance()
price = get_token_price()
value = balance * price
if value > CONVERSION_THRESHOLD:
swap_amount = value * (1 - STABLECOIN_TARGET)
swap_to_stablecoin(swap_amount / price)
# Run daily
rebalance_portfolio()Performance Benchmarking and Optimization
Maximizing earnings per GPU requires understanding what makes your hardware attractive to protocols:
Run comprehensive benchmarks across workload types:
# MLPerf inference benchmark
git clone https://github.com/mlcommons/inference.git
cd inference
python3 run.py --task resnet50 --backend pytorch --scenario offline
# Training throughput test
python3 -m torch.distributed.launch \
--nproc_per_node=2 \
benchmark_training.py \
--model gpt2-xl \
--batch-size 8
# Render performance test (Blender)
blender -b scene.blend -o /tmp/render -f 1-100 -noaudioCompare your results against published benchmarks for your GPU model. If performance is 10%+ below expected:
- Check for thermal throttling
- Verify PCIe link width (should be x16)
- Update to latest NVIDIA drivers
- Ensure power limits aren’t constraining clock speeds
- Test different CUDA toolkit versions
Optimize specifically for your highest-earning protocol. Render Network jobs benefit from:
- Fast CPU single-thread performance for scene parsing
- High VRAM for complex textures
- Fast storage for asset streaming
io.net training clusters optimize for:
- Maximum GPU-to-GPU bandwidth (NVLink)
- Large system memory for dataset caching
- Low-latency networking between nodes
Gensyn training jobs require:
- Consistent performance (no throttling)
- Reliable storage for checkpoints
- Accurate performance reporting during verification
Profile actual workload performance during jobs to identify bottlenecks. Most protocols log detailed timing information. Look for phases that take disproportionate time relative to the compute involved.
Wrapping Up: Bare Metal As DePIN’s Essential Foundation
Decentralized Physical Infrastructure Networks represent a paradigm shift in computing resource allocation. By aggregating distributed hardware through token incentives and cryptographic verification, DePIN protocols create alternatives to centralized cloud monopolies. But this model only functions when protocols can cryptographically verify the physical hardware performing work.
Virtualization’s fundamental purpose is abstracting hardware details away from software. DePIN’s fundamental requirement is proving specific hardware exists and is performing correctly. These goals are directly opposed. Public cloud infrastructure that virtualizes GPUs behind hypervisor layers cannot meet DePIN attestation requirements. Nodes fail verification, jobs get rejected, earnings never materialize.
 Bare metal infrastructure provides the transparent hardware access DePIN protocols require. Authentic device identification, complete performance visibility, deterministic benchmarks, and reliable attestation all depend on unmediated access to physical GPUs. OpenMetal’s bare metal GPU clusters deliver exactly this architecture with enterprise-grade NVIDIA hardware, predictable monthly pricing, and flexible commitment terms.
Bare metal infrastructure provides the transparent hardware access DePIN protocols require. Authentic device identification, complete performance visibility, deterministic benchmarks, and reliable attestation all depend on unmediated access to physical GPUs. OpenMetal’s bare metal GPU clusters deliver exactly this architecture with enterprise-grade NVIDIA hardware, predictable monthly pricing, and flexible commitment terms.
For node operators evaluating DePIN opportunities, the economic question isn’t whether to use bare metal, it’s which configuration optimally matches their protocol targets, risk tolerance, and scaling timeline. The Medium tier validates concepts at minimal commitment. The Large tier targets serious operations with proven earnings. The X-Large tier positions operators for premium workloads requiring maximum compute density.
DePIN remains an emerging category with substantial opportunity and real risks. Token prices fluctuate. Network utilization varies. Competition increases as more providers join. But the underlying trend toward decentralized infrastructure has powerful economic and technical logic. Organizations and individuals seeking alternatives to cloud giants, censorship resistance, or token-incentivized economics will continue expanding DePIN adoption.
The infrastructure requirement won’t change. DePIN needs bare metal. Virtualization can’t fake hardware attestation. Node operators who understand this fundamental architecture and position themselves with appropriate infrastructure will capture the value as DePIN protocols mature from experiments into production infrastructure.
Ready to start earning from decentralized compute networks? OpenMetal’s bare metal GPU infrastructure provides the hardware transparency and performance DePIN protocols require for reliable attestation. Get started with our Medium tier configurations or contact us for enterprise-scale deployments with 8x H100 clusters.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog