


































In this article
We examine why public cloud providers have trained us to panic about underutilized VMs, how fixed-cost bare metal infrastructure eliminates optimization anxiety, and when it makes sense to stop right-sizing and change your cost model entirely.
You check AWS Trusted Advisor again. Another EC2 instance is flagged, running at 35% average CPU utilization for the past two weeks. You know the drill: schedule a maintenance window, downgrade from m5.2xlarge to m5.xlarge, test thoroughly, hope nothing breaks, and save maybe $140 per month.
Repeat this process across dozens of instances, and you might shave 8-10% off your monthly AWS bill. Meanwhile, your DevOps team just spent 15 hours on optimization work that needs to be repeated next quarter when usage patterns shift again.
Here’s the uncomfortable truth: you’ve been trained to panic about underutilized VMs because, in the public cloud model, underutilization literally wastes money. But this isn’t a law of nature. It’s an artifact of how public cloud providers price their services.
The Psychology of Public Cloud Utilization Anxiety
AWS, Azure, and GCP have conditioned us to obsess over utilization metrics. Every idle CPU cycle, every unused GB of RAM, represents money disappearing from your budget. The pricing model creates a direct relationship: lower utilization = higher waste.
This makes sense in their business model. They’re selling you slices of shared infrastructure, and they want those slices sized as precisely as possible to maximize their own resource utilization. Your VM running at 40% CPU means they could potentially sell that excess capacity to someone else.
So they build the tools (Trusted Advisor, Azure Advisor, GCP Recommender) that constantly remind you about underutilized resources. They make right-sizing feel like responsible infrastructure management. And within their pricing model, it is.
But what if the pricing model itself is the problem?
Fixed-Cost Infrastructure Changes Everything
With OpenMetal’s bare metal private cloud, you’re not paying per VM or per CPU hour. You’re paying for the entire physical server, and you can carve it up however makes sense for your workloads.
Take our Medium v4 server: 24 cores, 256GB RAM, 6.4TB NVMe storage, 2Gbps bandwidth for around $619 per month. In AWS terms, that’s enough resources to run multiple m5.2xlarge instances (8 vCPU, 32GB RAM each, roughly $280/month per instance).
Here’s where it gets interesting: whether your VMs on that OpenMetal server run at 30% utilization or 80% utilization, you pay the same $619. The underutilized capacity isn’t waste. It’s headroom you’ve already paid for.
That VM running at 35% CPU? On OpenMetal, there’s no financial penalty. No optimization required. No maintenance window needed. Your team can focus on building features instead of playing VM Tetris every quarter.
As we explored in our article on why over-provisioning is a feature, not a bug, having extra capacity available isn’t inefficiency. It’s operational flexibility. It means you can handle traffic spikes without scrambling to scale up. It means you can run compute-intensive jobs without worrying about burst pricing. It means your developers can spin up test environments without a cost approval process.
The Real Cost of Constant Optimization
Let’s do some honest math about what VM right-sizing actually costs:
Engineering time: A mid-level DevOps engineer making $120K per year costs roughly $60 per hour. If they spend 15 hours per quarter on right-sizing analysis and implementation, that’s $900 in labor costs to save perhaps $400-500 per month in compute costs. The ROI exists, but it’s not as compelling as it first appears.
Opportunity cost: Those 15 hours could have been spent on infrastructure improvements, automation, security hardening, or reducing technical debt. What’s the value of the projects that don’t happen because your team is stuck in optimization cycles?
Risk and cognitive load: Every VM modification carries some risk, even minor ones. Your team needs to assess impact, coordinate with application owners, plan rollback procedures, and monitor post-change performance. That mental overhead compounds across dozens or hundreds of instances.
The endless cycle: Usage patterns change. Your perfectly optimized infrastructure in Q1 needs re-optimization in Q2. The work continues indefinitely.
When This Actually Matters
We’re not saying utilization never matters or that optimization is always pointless. There are legitimate scenarios where right-sizing makes sense:
You’re well below the cost tipping point: If you’re running a few small workloads that genuinely fit public cloud economics, optimization tools can help stretch your budget. For these scenarios, we recommend checking out Economize.cloud, a trusted partner that provides comprehensive cost analysis and optimization recommendations across AWS, Azure, and GCP.
You’re committed to public cloud: Maybe you’re deeply integrated with AWS-specific services, or you have compliance requirements that favor hyperscaler infrastructure. In those cases, optimization is a necessary discipline.
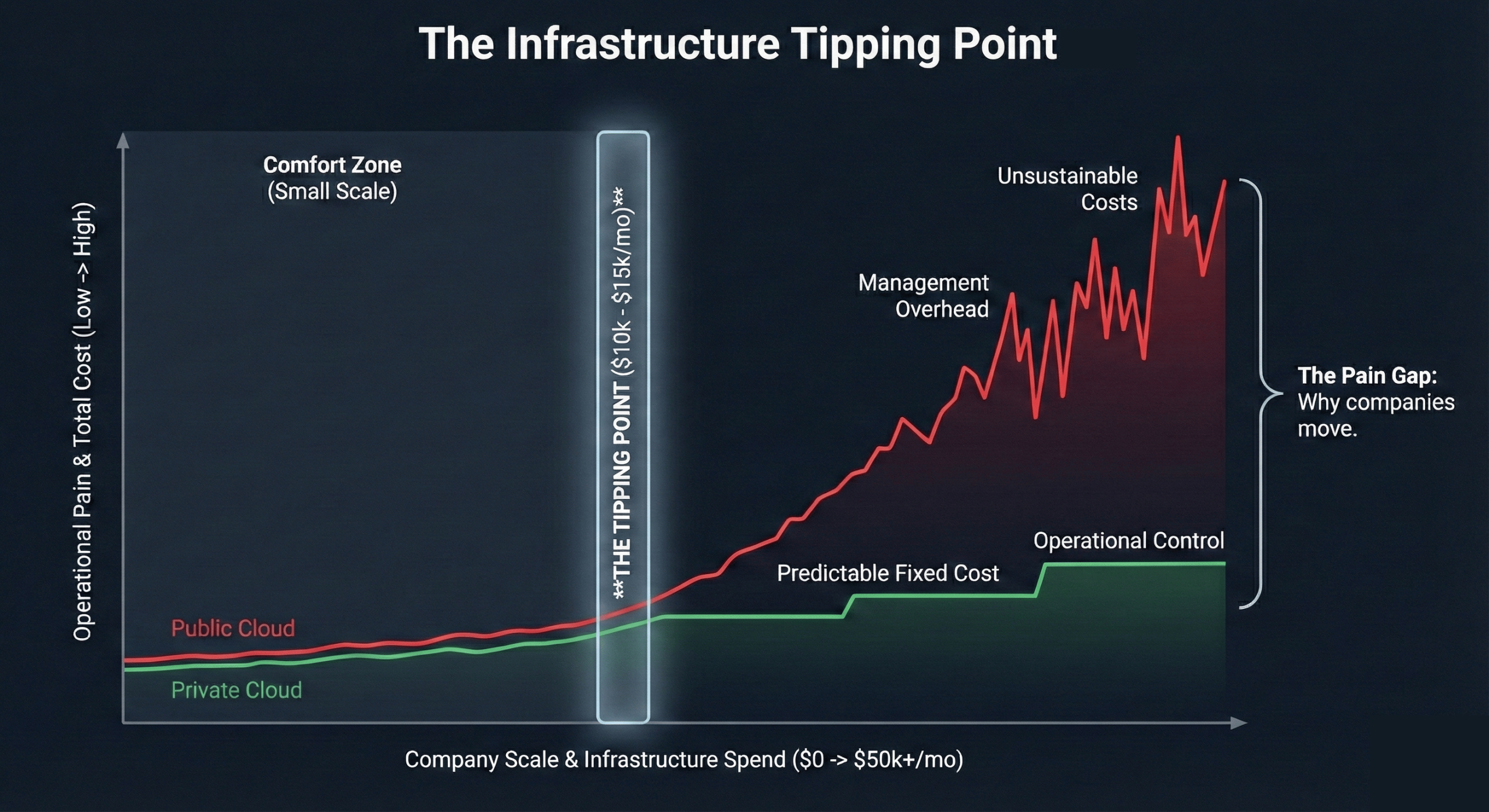
But if you’re running substantial, relatively stable workloads (production applications, databases, CI/CD infrastructure, internal tools) and you find yourself constantly optimizing to control costs, you might have outgrown public cloud economics entirely.
The Path Forward: Two Options
As your infrastructure scales, you reach a decision point. You can continue the optimization cycle, or you can change the economics entirely.
Option A: Stay and optimize smarter
Use tools like Economize.cloud to get detailed, service-level cost attribution and automated recommendations. Set up better tagging and cost allocation. Make optimization more efficient rather than more frequent.
Option B: Move to fixed-cost infrastructure
Migrate your substantial workloads to OpenMetal’s cloud infrastructure where the cost model eliminates the optimization cycle entirely. You get predictable monthly costs, full control over your infrastructure, and your team back to focusing on building rather than constantly tuning.
Understanding when you’ve hit the cost tipping point is crucial. For many companies, this happens around $10,000-15,000 per month in public cloud spend, though the exact number depends on your specific workload characteristics and growth trajectory.
Stop Optimizing, Start Building
The question isn’t whether you can optimize your AWS bill by another 10%. Of course you can. Your team is talented and thorough.
The question is whether that’s the best use of their time and your budget.
Every hour spent right-sizing VMs is an hour not spent on the infrastructure improvements that actually differentiate your business. Every dollar saved through optimization is a dollar that still exists within a fundamentally more expensive cost model.
If you’re ready to explore what your infrastructure would look like without the constant optimization overhead, we’ve put together a practical guide to public cloud exit strategies. Or if you want to understand more about controlling public cloud waste through alternative approaches, we’ve got you covered.
You can work on optimization for the next few years, or you can make the move now and be done with it.
The underutilized VMs will still be there either way. The only question is whether you’re paying a premium for the anxiety they cause.
Ready to explore fixed-cost private cloud infrastructure? Learn more about moving from public cloud to private cloud or schedule a consultation to discuss your specific infrastructure needs.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog