


































In this article
- The Hidden Costs of Public Cloud for Big Data Operations
- Evaluating Your Big Data Workloads: Is a Private Cloud Right for You?
- The OpenMetal Advantage: Dedicated Performance and Full Control
- A Clearer Path to Cost-Effectiveness: Deconstructing the TCO
- Wrapping Up: Private Cloud as a Public Cloud Alternative for Big Data Workloads
- Ready to Build Your Big Data Pipelines on OpenMetal Cloud?
The initial appeal of the major public clouds is undeniable. Platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure have lowered the barrier to entry for even the most ambitious projects. With a credit card and a few clicks, a team can access immense computing resources, making it possible for anyone to spin up GPU instances and begin training AI models in minutes. This pay-as-you-go model offers a handy combination of flexibility and speed, aligning with both the lean growth strategies of new ventures and the exploratory phases of established companies.
However, for organizations with maturing big data operations, this initial convenience often evolves into a significant challenge. What begins as a flexible and manageable expense can transform into an unpredictable and spiraling cost center. The model that provided freedom at the start can become a cage.
This leaves IT directors and cloud managers wondering at what point do the public cloud’s escalating costs, unpredictable performance, and lack of deep control begin to outweigh the initial benefits for our big data operations?
This guide is designed to provide a clear and practical decision-making framework to answer that question. It’s not an argument that public cloud is inherently “bad”, but rather a tool to help you identify the characteristics of your workloads and your organization that signal it’s time to consider a more powerful, predictable, and cost-effective alternative: a private cloud from OpenMetal.
The Hidden Costs of Public Cloud for Big Data Operations
The primary pain point that drives IT leaders to seek alternatives is often the loss of financial and operational control. To understand why this happens, let’s deconstruct the public cloud model and look at the factors that disproportionately drive up costs for data-intensive workloads.
Unpredictable Billing and the “Silent Killer” of Budgets
The pay-as-you-go model is a double-edged sword. While it offers flexibility for sporadic usage, it creates unpredictability for at-scale, consistent workloads. A slight uptick in data processing, a new analytics query, or the adoption of resource-hungry technologies like generative AI can cause monthly bills to blow past forecasts. This can turn budgeting into a nightmare. And this isn’t a minor annoyance. A 2024 survey revealed that nearly three-quarters of IT and finance professionals report that the AI boom has made their cloud bills “unmanageable”.
This unpredictability forces highly paid engineers and FinOps teams to spend countless hours simply trying to understand their bills rather than focus on strategic, value-generating work. For big data workflows, this problem is magnified significantly.
The core nature of big data—high volume, high velocity, and high variety—means that resource consumption is consistently high. Every API call, every CPU cycle, every gigabyte of data transferred or stored has an associated cost. This can turn the public cloud into what feels like an “all you can eat buffet”. But one where the shocking bill only arrives at the end of the month, leaving you with no way to control costs proactively.
The Egress Fee Trap: Paying to Access Your Own Data
One of the most notorious hidden costs of the public cloud is data egress, which is the fee charged for moving your data out of the provider’s network. While providers make it easy and free to move data in (ingress), they charge significant fees to move it out, effectively creating a “data tax”. These fees apply not only to data transferred to the public internet but also to traffic between a provider’s own availability zones and between different geographic regions.
Major providers typically charge between $0.08 and $0.12 per gigabyte for outgoing traffic. For a company moving hundreds of terabytes for analytics, backups, or multi-cloud deployments, these fees can easily add tens of thousands of dollars to the monthly bill. One report highlighted a case where a company faced a potential egress bill of $50,000 per month, while another startup was hit with a surprise $450,000 bill from Google Cloud after compromised API keys led to massive, unauthorized data transfers.
These exorbitant fees certainly create a powerful form of vendor lock-in. The cost to migrate massive datasets to a competing provider or back to an on-premises data center can become so prohibitively expensive that companies feel trapped, forced to remain in an ecosystem that may no longer be the best technical or financial fit.
Recently, in response to growing regulatory pressure from initiatives like the EU Data Act, the major cloud giants have begun waiving egress fees for customers who are fully migrating all their data off the platform. While a welcome change, this is a one-time exit pass, not a solution to the high day-to-day operational costs of data movement that impact multi-cloud strategies, disaster recovery plans, and data sharing with partners.
Performance Throttling and the “Noisy Neighbor” Problem
Public clouds are, by definition, multi-tenant environments. This means your virtual machines (VMs) run on physical hardware that is shared with other customers. This shared model gives rise to the “noisy neighbor” problem, a situation where another tenant’s resource-intensive workload monopolizes shared resources like CPU, network bandwidth, or disk I/O, causing the performance of your applications to degrade.
For big data analytics, machine learning, and high-performance computing (HPC), which depend on consistent, high-speed processing, this is a major flaw. A sudden drop in performance isn’t just an inconvenience; it can delay critical business insights, cause complex processing jobs to fail, and undermine the reliability of your entire data platform. If data is delayed by even seconds, it can have a significantly negative impact on the decisions made with that data.
Public cloud hosting providers attempt to mitigate this issue through measures like resource throttling or automated load rebalancing, but these are reactive solutions. Throttling simply means your workload is being deliberately slowed down. Load rebalancing might move a workload, but it’s a complex process that can be disruptive in its own right. Ultimately, in a shared system with finite resources, if one tenant takes more, others get less. The only true solution to the noisy neighbor problem is to move away from a shared model to one that provides complete resource isolation.
The Compounding Costs of Licensing and Wasted Resources
Beyond usage fees, other costs are often baked into public cloud pricing. Many cloud environments are built on proprietary virtualization platforms like VMware. The substantial licensing fees for this software, which can be on the order of $1,000 to $3,500 per processor, are passed on to you, the customer, as a hidden tax on top of your infrastructure costs.
Furthermore, the very structure of the public cloud encourages financial waste. To avoid performance bottlenecks caused by noisy neighbors, teams often overprovision resources, paying for larger and more expensive instances than they actually need. This creates a buffer of idle capacity that you pay for but don’t use. One study found that, on average, only 13% of provisioned CPUs and 20% of allocated memory in cloud-based Kubernetes clusters are actually utilized. This “cloud waste” from idle and overprovisioned resources is estimated to cost businesses billions of dollars annually.
These issues are not isolated, they create a negative feedback loop. The unpredictable performance caused by noisy neighbors drives teams to overprovision resources. This overprovisioning directly leads to higher, yet still unpredictable, bills due to wasted capacity. The fear of massive egress fees then prevents these teams from migrating to a more efficient platform, locking them into an expensive and inefficient cycle. This loop transforms the cloud from a business accelerator into a bottleneck. Instead of focusing on innovation, your best engineers and FinOps teams become trapped in a battle against rising costs, hindering your company’s ability to extract maximum value from its data.
Evaluating Your Big Data Workloads: Is a Private Cloud Right for You?
Understanding the limitations of the public cloud is the first step. The next is to conduct an evaluation of your own operations to determine if you’ve reached the tipping point where an alternative makes more sense. This framework will guide you through analyzing your workloads, performance demands, and control requirements.
Analyze Your Data and Workload Profile
First, look at the fundamental characteristics of your data and the workloads that process it.
- Data Characteristics: Is your data volume growing exponentially? Are you dealing with massive datasets that are processed continuously? Big data platforms are specifically designed to handle high volumes of data and require significant disk and network I/O to function effectively. If your workloads are consistently large and predictable, running 24/7, you are likely paying a premium for the on-demand flexibility of the public cloud—a flexibility you no longer need. For workloads with predictable and steady resource demands, a private cloud can be more cost-effective in the long run.
- Workload Type: The nature of your processing is a key indicator. Are you running high-performance computing (HPC) tasks, such as complex financial modeling, scientific research, or large-scale data analytics? These workloads demand powerful and, crucially, consistent compute resources to perform the heavy lifting of parallel processing. Are you building out a sophisticated MLOps platform from scratch or modernizing a legacy data warehouse for better performance and lower costs? These strategic projects benefit immensely from the stable, scalable, and customizable infrastructure that a private cloud provides.
Assess Your Performance and Availability Demands
Next, evaluate the service level agreements (SLAs) and performance expectations your business relies on.
- The Need for Speed and Reliability: The value of big data is often tied directly to the speed at which insights can be generated and delivered. For many applications, delays of even a few seconds in data transfer or processing can have a significant negative impact on business decisions. Your infrastructure must be able to support this with powerful compute, scalable storage, and high-quality, low-latency network connectivity. It also needs to be architected for high availability, including rapid recovery capabilities, to ensure business continuity. If your SLAs are strict and performance cannot be compromised, the variability of a shared, multi-tenant environment represents a significant business risk.
- Supporting Core Big Data Platforms: The foundations of modern big data infrastructure are often built on powerful open source frameworks like Apache Hadoop for distributed storage, Apache Spark for analytics, Apache Cassandra for NoSQL databases, and ClickHouse for real-time analytical reports. These platforms are designed to run on clusters of machines and are highly sensitive to the performance and configuration of the underlying hardware and network. To get the most out of them, you need an environment that can be tuned to their specific needs.
Examine Your Need for Control, Security, and Compliance
Finally, consider how much control you need over your environment to meet your technical and business objectives. The need for “control” isn’t about a desire for micromanagement, it is a prerequisite for achieving the specific performance, security, and cost-efficiency that mature big data operations demand.
- The Power of Root Access: Do your teams need to fine-tune the cloud environment to squeeze out every last drop of performance? True user control over the infrastructure is what allows for this level of customization. This includes the ability to create custom VM “flavors” with specific CPU-to-RAM ratios (e.g., a high-CPU, low-RAM instance for a MariaDB database), select specific disk I/O performance by running databases on VMs with direct NVMe storage, and install specialized drivers or software that aren’t available in the standard public cloud marketplace. This level of deep, root-level control is simply not possible in the abstracted, managed environment of a public cloud.
- Security and Data Sovereignty: For organizations in highly regulated industries such as healthcare, finance, and government, security and compliance are non-negotiable. A private cloud offers greater security and control because you are the sole tenant of the hardware. This gives you full authority to harden the environment to meet strict compliance frameworks. It also allows you to guarantee that your data remains in a specific geographic location (data sovereignty), a requirement for satisfying many governance and privacy regulations.
The Public Cloud Tipping Point
The evaluation questions in this section are deeply interconnected. For instance, a business requirement for a highly performant Apache Spark cluster logically leads to a technical requirement for dedicated hardware to eliminate performance variability from noisy neighbors. This, in turn, leads to the need for root access to create custom VM images and storage configurations to optimize Spark’s shuffle operations. Each step in this chain of reasoning points toward a need for greater control over the infrastructure.
This brings us to the definition of the “tipping point“. The tipping point for moving off the public cloud is reached when the sum of compromises becomes greater than the value of convenience. This occurs when the financial compromises (unpredictable bills, high egress fees), the performance compromises (throttling, noisy neighbors), and the control compromises (no root access, security and compliance limitations) collectively prevent your big data platform from achieving its core business objectives effectively and economically.
The OpenMetal Advantage: Dedicated Performance and Full Control
Once you’ve identified that your organization has reached this tipping point, the next step is to explore an alternative that directly addresses these challenges. OpenMetal’s on-demand private cloud is engineered to provide the performance, control, and cost-effectiveness that large-scale data operations require, without sacrificing the agility that cloud-native teams expect.
Dedicated Hardware, Predictable Performance
The foundation of the OpenMetal platform is the on-demand Private Cloud Core (PCC), which is powered by OpenStack and built on enterprise-class hardware assigned exclusively to you.
- Eliminating the “Noisy Neighbor”: Because you are the sole tenant of your hardware cluster, the “noisy neighbor” problem is completely eliminated. All CPU, RAM, storage I/O, and network bandwidth are yours alone. This guarantees consistent, predictable throughput and latency for your most demanding workloads, allowing your applications to deliver every ounce of their capability without contention or hypervisor throttling beyond your own control.
- Bare Metal Power in a Cloud Model: This single-tenant architecture delivers the performance of bare metal, but without the immense overhead of architecting, procuring, and managing a traditional private cloud from scratch. You get the power of dedicated servers fused with the convenience and speed of a cloud-native environment. Entire private clouds can be deployed in as little as 45 seconds, used, destroyed, and spun up again as needed, all from a simple user portal.
Root Access for True Optimization
OpenMetal provides full root access to your hosted servers, empowering your team to customize and tune your cloud for optimal performance in ways that are impossible on a public cloud.
- Full Control, Granular Tuning: This deep control allows you to move beyond generic instance types. Your team can create its own specific VM flavors to perfectly match the needs of a particular database or application. For example, you can create a VM with 32 vCPUs and just 8GB of RAM for a compute-bound MariaDB instance. You can achieve massive performance gains by running replicated databases in VMs that use direct NVMe storage, bypassing the latency introduced by network-attached storage. You also control the vCPU oversubscription ratio, allowing you to safely increase density and maximize the use of your hardware resources.
- Object Storage Acceleration: This control extends to your storage layer. OpenMetal’s clouds are powered by Ceph, a high-performance open source storage system. With root access, you can enable features like on-the-fly compression during object placement, which can dramatically increase the efficiency of your storage pool, for instance, making 10TB of data take up only 7TB of physical space. You can also perform data transformations as objects are written to storage, offloading costly work from your applications.
An Architecture Built for Big Data and AI
The OpenMetal platform is built on a foundation of powerful, production-hardened open source technologies, primarily OpenStack and Ceph.
- Open Source Foundations: This open source core provides two key advantages. First, it completely removes the proprietary licensing costs associated with platforms like VMware, directly reducing your TCO. Second, it allows easy integration with the ecosystem of open source big data and AI tools that your teams already use, including Apache Hadoop, Spark, Kafka, and many others. Kubernetes integration is native to the platform and can be deployed on a self-service basis, simplifying and accelerating modern DevOps pipelines.
- Future-Ready Infrastructure: The architecture is designed to be flexible and extensible. The addition of servers for specialized hardware like GPUs and FPGAs is fully supported, ensuring that your cloud can evolve to handle the next generation of demanding AI and machine learning workloads.
A New Kind of Cloud
OpenMetal’s on-demand private cloud is not simply a traditional private cloud hosted in a data center. It represents a new category of infrastructure that deliberately fuses the most desirable attributes of the public cloud—such as rapid, on-demand deployment, scalability, and an operational expense model—with the core benefits of a true private cloud: dedicated performance, deep control, and enhanced security.
This unique fusion directly resolves the central conflict that IT leaders of mature, data-driven organizations face. They want the control and performance of private infrastructure but fear the slow deployment times, high upfront capital investment, and immense management complexity of building it themselves. They also value the agility of the public cloud but are being burned by its unpredictable costs and inconsistent performance. By delivering a fully private, single-tenant cloud in 45 seconds as a simple operational expense, OpenMetal removes the traditional barriers to private cloud adoption while solving the most painful problems of the public cloud.
Perhaps most importantly, this approach has a huge impact on your most valuable resource: your people. The greatest challenge in adopting a powerful platform like OpenStack has always been the immense difficulty of architecting the cloud from the ground up, including hardware selection, network design, and software configuration. OpenMetal does this heavy lifting for you, delivering a pre-architected, production-ready cloud on demand. This frees your high-value engineering and DevOps teams from getting bogged down in low-level infrastructure design and allows them to focus on what they do best: administering the cloud and building innovative, value-generating applications on top of it. This accelerates your time to market and dramatically improves the return on investment of your engineering talent.
A Clearer Path to Cost-Effectiveness: Deconstructing the TCO
The technical and performance advantages of a dedicated private cloud are clear, but the decision for any IT director is usually most heavily affected by the numbers. A detailed look at the Total Cost of Ownership (TCO) reveals the powerful and predictable financial advantages of the OpenMetal model for the right kind of workloads.
The Power of Predictable, Flat-Fee Pricing
A major financial shift when leaving public cloud is the move from variability to predictability.
- Ending Surprise Bills: In contrast to the complex, usage-based billing of public clouds, OpenMetal offers a simple, fixed-cost model. You pay a flat monthly fee for your dedicated hardware cluster. This eliminates surprise bills and makes your cloud costs stable and predictable, allowing you to forecast your budget accurately for months or even years in advance with up to a 5-year price lock. For organizations that find themselves spending more than $10,000 per month on public cloud, a move to an on-demand private cloud solution can deliver big savings alongside significant performance improvements.
- No Per-VM or Licensing Fees: This flat fee is for the underlying hardware, not for the virtual resources you choose to run on it. There are no additional license fees for VMs, vCPUs, or other cloud resources. This model completely removes the proprietary software “tax” that is often hidden within the pricing of other cloud environments.
Slashing Egress and Data Transfer Costs
Data transfer fees, a major source of pain in the public cloud, are addressed with a model designed for fairness and transparency.
- Fair and Transparent Egress: OpenMetal offers fixed bandwidth costs, with billing based on the 95th percentile method. This industry-standard practice measures your bandwidth usage over the course of the month and then ignores the top 5% of usage spikes. This approach flattens out the cost impact of short, intense traffic bursts, ensuring that a sudden surge in activity won’t blow up your bill. For many customers, this results in egress costs that are up to 80% lower than the rigid per-gigabyte billing model used by most public clouds.
- No Internal Transfer Fees: Because your compute and storage resources are co-located on the same high-speed network switches within your private cloud, there are no surprise fees for moving data between services. You can transfer data between your application VMs and your Ceph object storage cluster without the kind of inter-service or inter-zone charges that are common in public clouds.
Maximizing Resource Utilization for Lower TCO
The single-tenant nature of an OpenMetal cloud allows you to achieve a level of resource efficiency that is impossible in a multi-tenant environment.
Private Cloud vs Public Cloud Resource Management From Within a VM
![]()
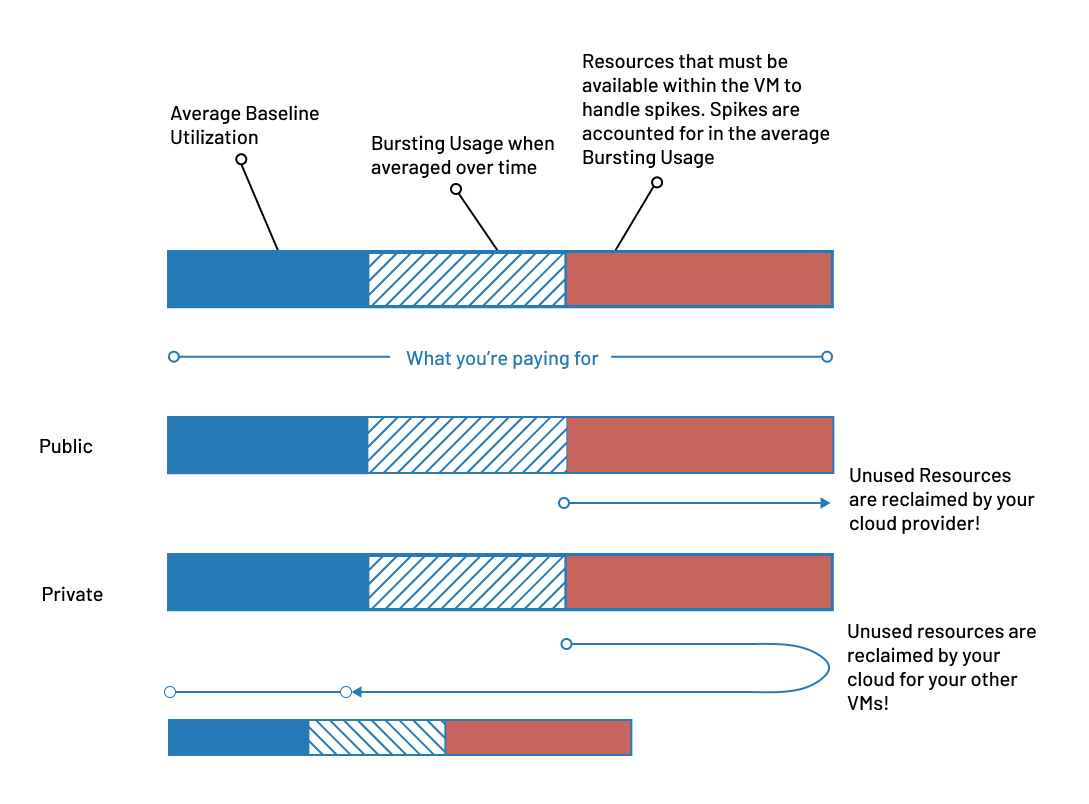
- Using 100% of What You Pay For: In a public cloud, you pay for a virtual “slice” of a server. Any CPU or RAM capacity within that slice that your application doesn’t use at any given moment is “wasted” from your perspective and is often reclaimed and resold by the provider. But with OpenMetal, you lease the entire physical server. This means any capacity that your VMs aren’t using is dynamically returned to your private cloud’s resource pool, where it is immediately available for your other VMs to use. This ability to fully and efficiently utilize the entire pool of resources you are paying for dramatically lowers the effective cost per workload and leads to a much lower TCO, especially for predictable, steady-state workloads.
- Real-World Savings: This combination of predictable pricing, fair egress, and total resource utilization leads to impressive savings. Most OpenMetal customers save over 25% compared to their previous public cloud bills, and many see savings of 50% or more. For example, a cybersecurity firm successfully built a high-powered ClickHouse deployment on OpenMetal for its real-time big data analytics platform. In another case, a SaaS provider achieved 50% savings by migrating its DevOps workloads to an OpenMetal private cloud.
To make this concrete, the following table provides a direct TCO comparison for a large cloud deployment. It compares the cost of running approximately 593 VMs on AWS with the cost of an equivalent OpenMetal XL v2 cloud core.
TCO at a Glance: Public vs. OpenMetal Private Cloud
| Term for ~593 VMs | AWS EC2 (c5ad.large equivalent) | OpenMetal XL v2 | Savings |
| Monthly On-Demand | $45,769.19 | $6,105.60 | 86.6% |
| 1-Year Reserved | $367,416.48 | $64,475.16 | 82.5% |
| 3-Year Reserved | $806,152.32 | $156,059.28 | 80.6% |
Note: Pricing comparison is based on data from OpenMetal’s analysis and includes 36TB of egress for both providers to ensure a fair comparison.
As the table shows, for a large, consistent workload, the savings are not marginal, but transformative. The ability to lock in a predictable cost that is over 80% lower than the public cloud equivalent frees up immense capital. That money can then be reinvested into innovation, talent, and other business priorities.
Wrapping Up: Private Cloud as a Public Cloud Alternative for Big Data Workloads
The journey for many organizations begins in the public cloud, and for good reason. Its flexibility and low barrier to entry are powerful tools for getting started. But as your data operations mature, grow in scale, and become more critical to your business, a clear “tipping point” emerges.
When this happens, the economic, performance, and control advantages of an on-demand private cloud like OpenMetal become both attractive and strategically necessary. The public cloud’s model, designed for multi-tenancy and sporadic usage, begins to work against you, imposing unpredictable costs, inconsistent performance, and frustrating limitations.
To help you determine if you’ve reached this critical tipping point, here is a simple checklist. If you find yourself answering “yes” to several of these questions, it is a strong indication that a move to a platform like OpenMetal should be seriously considered.
A Simple Checklist for Your Decision
- Are your public cloud bills becoming unpredictable and difficult to forecast, causing budget anxiety for your finance team?
- Do data egress fees represent a significant and growing line item on your cloud spend? Is this limiting your ability to pursue multi-cloud or hybrid strategies?
- Do your critical applications require high, consistent performance that is being throttled or negatively impacted by the “noisy neighbor” effect?
- Is your data growing exponentially, with predictable, consistent workloads that run 24/7?
- Do your engineering or DevOps teams need more direct, root-level control over the hardware and software stack for performance tuning, security hardening, or to meet strict compliance requirements?
- Is your technology stack built primarily on powerful open source big data tools like Apache Spark, Hadoop, Cassandra, or Kubernetes? Do you want an infrastructure that integrates with them seamlessly?
If this matches the challenges you’re facing, the next step is to get a clear picture of what a transition could look like. We invite you to schedule a consultation with one of our cloud experts. We can help you with a tailored TCO analysis and design a cloud that gives you the performance, control, and predictability your big data operations deserve.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog