































In this article
If you’re evaluating whether to move off Databricks, this article covers how the DBU billing model actually works, why the Standard tier retirement is forcing a cost reckoning for many teams, what the open-source stack underneath Databricks looks like, and where private cloud infrastructure changes the economics.
Databricks was founded by the creators of Apache Spark. The platform is built on Spark, Delta Lake, and MLflow, all of which are open source. That’s not a criticism! It’s the key fact any team evaluating Databricks alternatives needs to start from.
The question isn’t whether you can run data engineering workloads without Databricks. You can. The question is whether the operational complexity and licensing overhead of doing so is worth the cost savings for your specific workload profile. For some teams, the answer is clearly no. For others, especially those with predictable batch workloads and the engineering capacity to manage their own stack, it increasingly is.
How the Databricks Billing Model Works
Databricks uses a consumption-based model built around Databricks Units (DBUs), an internal billing currency that measures compute capacity. Every workload type consumes DBUs at a different rate. You pay for DBUs on top of the underlying cloud infrastructure, which means every Databricks deployment generates two separate bills: one to Databricks for DBU consumption and one to your cloud provider for the VMs, storage, and networking underneath.
That dual-bill structure is where cost surprises come from. The DBU charge is the visible line item. The cloud infrastructure cost, covering EC2 instances or equivalent VMs, EBS storage, and data transfer, is a separate invoice from AWS, Azure, or GCP. Cloud infrastructure costs often equal or exceed DBU charges, especially for teams with large compute requirements.
The workload type you select has an outsized effect on the DBU rate. Jobs Compute, designed for automated scheduled workloads like ETL pipelines, carries the lowest DBU rate because clusters terminate automatically when jobs finish. All-Purpose Compute, used for interactive notebooks and exploratory analysis, carries a substantially higher DBU rate per hour. The same computation running as a Jobs workload costs roughly 3 to 4 times less than running it on All-Purpose Compute. Teams that habitually run production pipelines on All-Purpose clusters because it’s convenient are paying the premium for interactivity they don’t need.
Clusters also consume DBUs while running, even when idle. If auto-termination isn’t configured, an interactive cluster left running between sessions continues generating charges.
The Standard Tier Sunset Is Forcing a Reckoning
There’s a specific pressure point for Databricks users right now. Databricks retired the Standard tier on AWS and GCP in October 2025, automatically upgrading remaining Standard workspaces to Premium. On Azure, new Standard workspace creation was blocked as of April 1, 2026, and all remaining Standard workspaces will be automatically upgraded to Premium by October 1, 2026.
Premium is not a marginal upgrade. Azure teams on Standard will see DBU rate increases of at least 35 percent when they migrate to Premium. Premium includes Unity Catalog for data governance, role-based access control, audit logging, and SQL Warehouses, but teams that don’t need those features are now paying for them regardless.
For teams that adopted Standard specifically for its cost profile and built their data pipelines around core Spark functionality, the forced upgrade to Premium is a natural moment to evaluate alternatives.
What Databricks Is Actually Built On
Understanding what’s proprietary in Databricks and what isn’t is the prerequisite for any honest evaluation of alternatives.
Apache Spark is the distributed compute engine at the core of Databricks. Databricks’ founders created Spark at UC Berkeley and spun up the company to commercialize it. Spark is open source under the Apache Software Foundation and can be deployed and operated independently.
Delta Lake is the open table format Databricks developed and open-sourced. It provides ACID transactions, schema enforcement, time travel, and incremental processing on top of object storage. The core Delta Lake library is open source. Databricks layers proprietary management tooling on top, but the table format itself is fully open.
MLflow is the open-source experiment tracking, model registry, and model serving framework that Databricks developed. It’s widely used independently of Databricks and integrates with other ML frameworks.
Apache Airflow (and alternatives like Prefect or Dagster) handles workflow orchestration. Databricks offers its own Workflows product, but Airflow is the most common open-source equivalent in production data platforms.
What Databricks contributes on top of this foundation is meaningful: a polished unified workspace, managed cluster operations, the Photon query engine, Unity Catalog for cross-workspace data governance, serverless compute, and integrated support. These aren’t trivial. But for teams whose workloads map to scheduled batch processing, ELT pipelines, and model training rather than interactive exploration and multi-team governance, the open-source components cover most of the functional requirement.
The Open-Source Lakehouse Stack
The modern open-source alternative to Databricks typically combines:
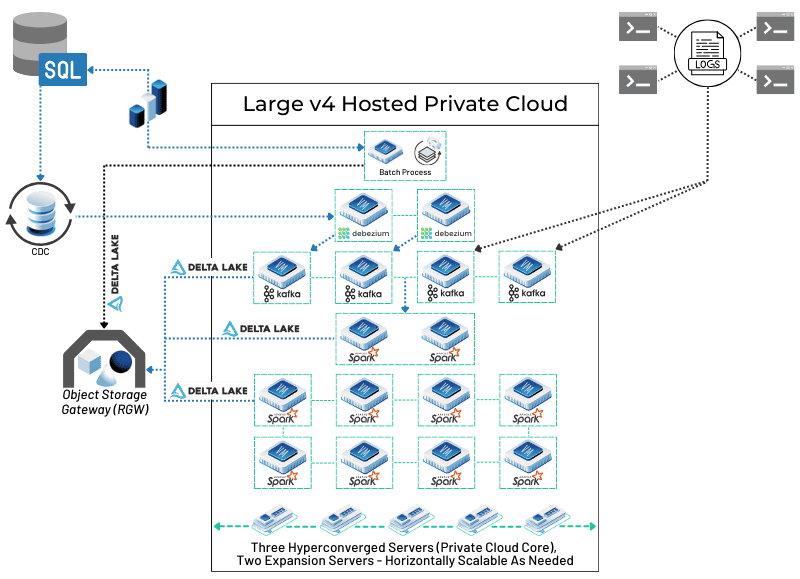
Apache Spark for distributed data processing. Runs on any compute cluster, including virtual machines provisioned through OpenStack. Spark’s PySpark API means existing Databricks notebooks often require minimal changes to run on self-managed Spark.
Delta Lake or Apache Iceberg as the table format on object storage. Both support ACID transactions, time travel, and schema evolution. Delta Lake is the format most Databricks users already have. Iceberg has broader support across query engines. Both work with Ceph’s S3-compatible object storage.
Apache Airflow for workflow orchestration. Defines, schedules, and monitors ETL and ELT pipelines as directed acyclic graphs (DAGs). The most widely deployed open-source orchestration framework for data engineering.
MLflow for experiment tracking and model registry. Runs as a standalone server on any VM. No Databricks dependency.
Apache Superset or Metabase for SQL analytics and visualization. Both are open source and cover the BI layer that Databricks SQL Warehouses provide.
Ceph for object storage. Provides S3-compatible APIs, meaning Delta Lake and Iceberg tables stored in Ceph are accessed via the same boto3 or Hadoop S3A APIs used to access AWS S3. No application changes required when the storage endpoint changes.
This stack requires more operational work than Databricks. Cluster management, Spark version upgrades, Airflow DAG monitoring, and Ceph administration all land with your team. That’s the real cost of the alternative, and it’s a genuine one. The question is whether it’s a better tradeoff than the DBU billing model at your scale and workload type.
What Changes on Private Cloud Infrastructure
When the open-source stack runs on private cloud infrastructure, two aspects of the economics change significantly.
Compute is fixed-cost. Databricks on AWS means Spark cluster compute is metered: you pay per VM-hour for the cluster, plus DBU charges. A long-running job, a misconfigured cluster size, or an unanticipated data volume spike goes on the invoice. On OpenMetal, compute is a monthly fixed price for dedicated hardware. A Spark job that runs longer than expected doesn’t generate a larger bill.
Data movement is unmetered on the private network. Spark’s shuffle operations, the data redistribution that happens during joins and aggregations, generate internal cluster traffic that crosses the network constantly. On public cloud, that traffic may cross availability zones and trigger transfer charges. On OpenMetal, each server includes 20-40 Gbps of unmetered private bandwidth. Intra-cluster Spark traffic doesn’t show up on an invoice.
OpenMetal’s XL v5 servers carry 64 cores, 1TB of DDR5-6400 RAM, and 25.6TB of NVMe storage. A three-node cluster built on XL v5 hardware provides 192 cores, 3TB of RAM, and 76.8TB of raw NVMe, with Ceph providing distributed object storage accessible via the same S3 APIs your Spark jobs already use. For teams running predictable batch workloads on a consistent schedule, the fixed-cost model gives you a number you can plan around rather than one that varies with job runtime and data volume.
The Ceph object storage layer is relevant for teams already on the lakehouse architecture. Delta Lake tables and data lake storage on Ceph use standard S3-compatible APIs, which means migrating from an S3-backed Databricks lakehouse to Ceph-backed storage is a configuration change, not a data pipeline rewrite.
What You Give Up
The open-source stack is not a complete Databricks replacement for every use case. The gaps are real.
Unity Catalog. Databricks’ centralized data governance layer handles data discovery, lineage tracking, access controls, and audit logging across workspaces. The open-source equivalent is a combination of Apache Atlas or OpenMetadata for metadata and lineage, plus custom access policies. It works, but it’s more assembly.
Managed cluster operations. Databricks handles Spark version management, cluster autoscaling configuration, and infrastructure patching. On self-managed clusters, your team owns that operational work. For organizations without dedicated platform engineering capacity, this is a genuine constraint.
Photon engine. Databricks’ proprietary Photon query engine delivers significant performance improvements over open-source Spark for SQL-heavy workloads. The open-source alternative is Spark with Apache Arrow and columnar execution improvements, which has closed the gap but isn’t equivalent at all workload types.
Serverless compute. Databricks Serverless eliminates cluster management entirely, billing only for active compute seconds. The open-source stack doesn’t have a direct equivalent.
Integrated workspace. The unified Databricks workspace that surfaces notebooks, jobs, SQL analytics, and ML experiments in one place doesn’t exist in the open-source stack. You’re assembling JupyterHub, Airflow, Superset, and MLflow separately and connecting them yourself.
For teams doing active, exploratory data science across multiple teams with strict governance requirements, Databricks’ managed platform delivers real value. For teams running well-defined, scheduled data engineering pipelines and batch processing workloads, the open-source stack covers the functional requirements at a cost structure that doesn’t scale with data volume.
How to Think About the Decision
The teams for whom this evaluation makes sense share a few characteristics: they have data engineering workloads that are primarily batch and scheduled rather than interactive, they have platform engineering capacity to manage a more assembled stack, their spend on Databricks has grown to the point where the DBU billing model is a regular budget conversation, and the Standard tier retirement has landed them in an unplanned cost increase.
For teams on the other end of the spectrum, doing heavy interactive exploration, running multi-team data products with strict governance requirements, or relying on Databricks-specific features like Photon or serverless compute, the migration overhead is unlikely to pay off.
OpenMetal’s Big Data Infrastructure use case page covers the hardware configurations and deployment patterns that work well for Spark and Kafka workloads. If you’re working through whether the open-source stack makes sense for your workload, the PoC program gives you a defined window to validate performance and cost on actual infrastructure before committing.
OpenMetal’s engineers have worked through similar evaluations with teams coming from managed data platforms. That’s available through the OpenInfra community and through direct engagement.
Frequently Asked Questions
Is Databricks open source?
Databricks is a commercial company. The core technologies it is built on, including Apache Spark, Delta Lake, and MLflow, are open source and can be deployed independently. Databricks adds proprietary features on top: the Photon query engine, Unity Catalog, managed cluster operations, serverless compute, and the integrated workspace UI. The open-source components are maintained by the Apache Software Foundation and the Linux Foundation.
What is the Databricks Standard tier retirement and who does it affect?
Databricks retired its Standard pricing tier on AWS and GCP in October 2025 and is retiring it on Azure by October 2026. Teams on Standard were automatically upgraded to Premium, which carries higher per-DBU rates. Premium includes Unity Catalog, advanced governance features, and SQL Warehouses. Teams that adopted Standard for basic Spark workloads and don’t need governance features are now paying for them. The forced upgrade is a natural trigger point for evaluating whether the open-source stack is a better fit.
What is a DBU in Databricks pricing?
A Databricks Unit (DBU) is the billing currency Databricks uses to measure compute consumption. DBU rates vary significantly by workload type: Jobs Compute (automated pipelines) carries the lowest rate, while All-Purpose Compute (interactive notebooks) carries a rate roughly 3 to 4 times higher. DBU charges are billed in addition to cloud infrastructure costs, which are charged separately by AWS, Azure, or GCP.
Can I run Delta Lake without Databricks?
Yes. Delta Lake is open source under the Linux Foundation. The Delta Lake library can be used with Apache Spark deployed on any infrastructure, including self-managed clusters on private cloud. Delta tables stored in S3-compatible object storage (including Ceph) work with the open-source Delta Lake library. Databricks-specific features like optimized file management and Predictive I/O are proprietary and not available outside the Databricks platform.
What does the Databricks alternative stack look like in practice?
A common open-source lakehouse stack combines Apache Spark for distributed compute, Delta Lake or Apache Iceberg for the table format on object storage, Apache Airflow for workflow orchestration, MLflow for experiment tracking and model registry, and Apache Superset or Metabase for SQL analytics. On OpenMetal, Spark clusters run on OpenStack-provisioned VMs, with Ceph providing S3-compatible object storage for the data lake layer.
What workloads are a good fit for moving off Databricks?
Scheduled batch ETL and ELT pipelines are the best candidates: the workload is well-defined, the compute requirement is predictable, and the Jobs Compute equivalent in open-source Spark is functionally comparable. Interactive data science workflows, multi-team governance-heavy environments, and workloads that rely on Photon performance or serverless compute are harder to migrate and often not worth the operational overhead.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog