


































In this article
When you choose a cloud provider’s APIs, you’re making a financial commitment that compounds over time. This article breaks down how proprietary cloud APIs create vendor lock-in, what that lock-in costs in migration debt and ongoing fees, and how OpenStack-based private cloud infrastructure maps to the patterns developers already know without the long-term dependency.
Every team building on public cloud eventually faces the same conversation. The infrastructure works. The application is running. But at some point, whether it’s a bill that keeps climbing, a compliance requirement that creates friction, or a pricing change that wasn’t in the roadmap, someone asks: what would it take to move?
If your application is deeply integrated with a hyperscaler’s native services, the answer is usually uncomfortable. Not because private cloud is inherently difficult, but because the APIs you built against were never designed to be portable. That’s not an accident.
What “Vendor Lock-In” Actually Means at the API Layer
Vendor lock-in is widely discussed but frequently misunderstood as a contracts problem. By the time contract terms matter, the real lock-in has already happened. It lives in the code.
When a team builds on AWS Lambda, DynamoDB, API Gateway, SQS, or Azure Service Bus, they’re importing an ecosystem of proprietary interfaces. Each of those services has its own API schema, its own SDK, its own behavior under load, and its own deprecation timeline. The application doesn’t just run in the cloud; it’s written for a specific cloud.
Vendor lock-in occurs when a cloud provider uses proprietary technologies, formats, or interfaces that are not easily interoperable with other providers, making it difficult for customers to migrate their applications and data. The research is consistent on who bears the consequences: most customers are unaware of proprietary standards that inhibit interoperability and portability of applications when taking services from cloud vendors.
This is the crux of the API lock-in problem. The decision to build on a managed service feels low-friction in the moment. The friction accumulates quietly, surfacing only when you need to do something the provider hasn’t priced in your favor. For a broader look at how cloud billing complexity compounds these costs, OpenMetal’s breakdown of fixed-cost versus usage-metered pricing is worth reading alongside this.
The Three Layers of API Lock-In Cost
1. Migration cost
When the time comes to move, for cost, compliance, performance, or strategic reasons, applications built on proprietary APIs require significant rework. Changing providers means rewriting integrations that may span the entire application stack.
Data migration is cited by 47% of enterprises as a significant barrier when considering switching providers. That figure reflects data portability, but the same dynamic applies to API portability. The more deeply a codebase integrates with provider-specific services, the more expensive and disruptive any future migration becomes.
The repatriation trend makes this concrete. According to Barclays’ Q4 2024 CIO Survey, 86% of enterprise CIOs planned to move at least some public cloud workloads back to private cloud or on-premises infrastructure, the highest figure the survey had recorded. Among those who’ve already attempted it, the costs can be significant: GEICO saw its cloud costs increase 2.5 times after spending a decade migrating over 600 applications to the public cloud, a dynamic that eventually drove repatriation planning. Migration costs run in both directions. For a detailed look at where these efforts go wrong, see OpenMetal’s analysis of common cloud repatriation failure modes.
2. SDK dependency debt
Building against a hyperscaler’s SDK means your application inherits that SDK’s lifecycle. Every version update, breaking change, or deprecation becomes your engineering team’s problem to absorb. Over time, this creates a category of technical debt that’s invisible on the balance sheet but very visible during sprints.
Technical debt accumulates as systems become increasingly tailored to specific vendor platforms, creating inextricable dependencies. This is particularly acute for teams that have adopted multiple native services, each with its own SDK, its own update cadence, and its own idiosyncrasies. The application becomes harder to reason about, harder to test in isolation, and harder to hand off to engineers who haven’t internalized a specific provider’s quirks.
3. Ongoing fees tied to proprietary service usage
Proprietary managed services don’t just create migration costs. They generate ongoing ones. API call fees, per-request charges, inter-service data transfer within the same provider, and NAT gateway fees can accumulate invisibly. These costs are documented in the pricing pages, but they’re difficult to forecast accurately before you’ve run production workloads at scale.
Cloud vendors charge significant egress fees that discourage moving data to a competitor, and the same logic extends internally: proprietary managed services create data flows that carry charges you have limited control over. The more tightly coupled your application architecture is to native services, the less leverage you have over this portion of your bill. OpenMetal’s hidden cloud costs breakdown covers this in more depth, including how egress and per-call fees compound at scale.
What Open APIs Actually Look Like
Teams evaluating private cloud infrastructure often assume they’re trading a rich, familiar API ecosystem for something more limited. In practice, the mapping is closer than most people expect.
OpenStack provides standardized APIs for compute, storage, and networking. Nova manages virtual machines, Cinder manages block storage, Neutron manages networking, and these APIs work identically across any OpenStack deployment.
For developers who know public cloud, the translation is fairly straightforward. Nova is comparable to AWS EC2, Swift provides object storage comparable to AWS S3, and Neutron handles networking similarly to AWS VPC. Heat, OpenStack’s orchestration service, maps to CloudFormation. Designate handles DNS in a pattern similar to Route 53. For a fuller picture of how OpenStack projects map to public cloud services, see What Are the Projects That Make Up OpenStack?
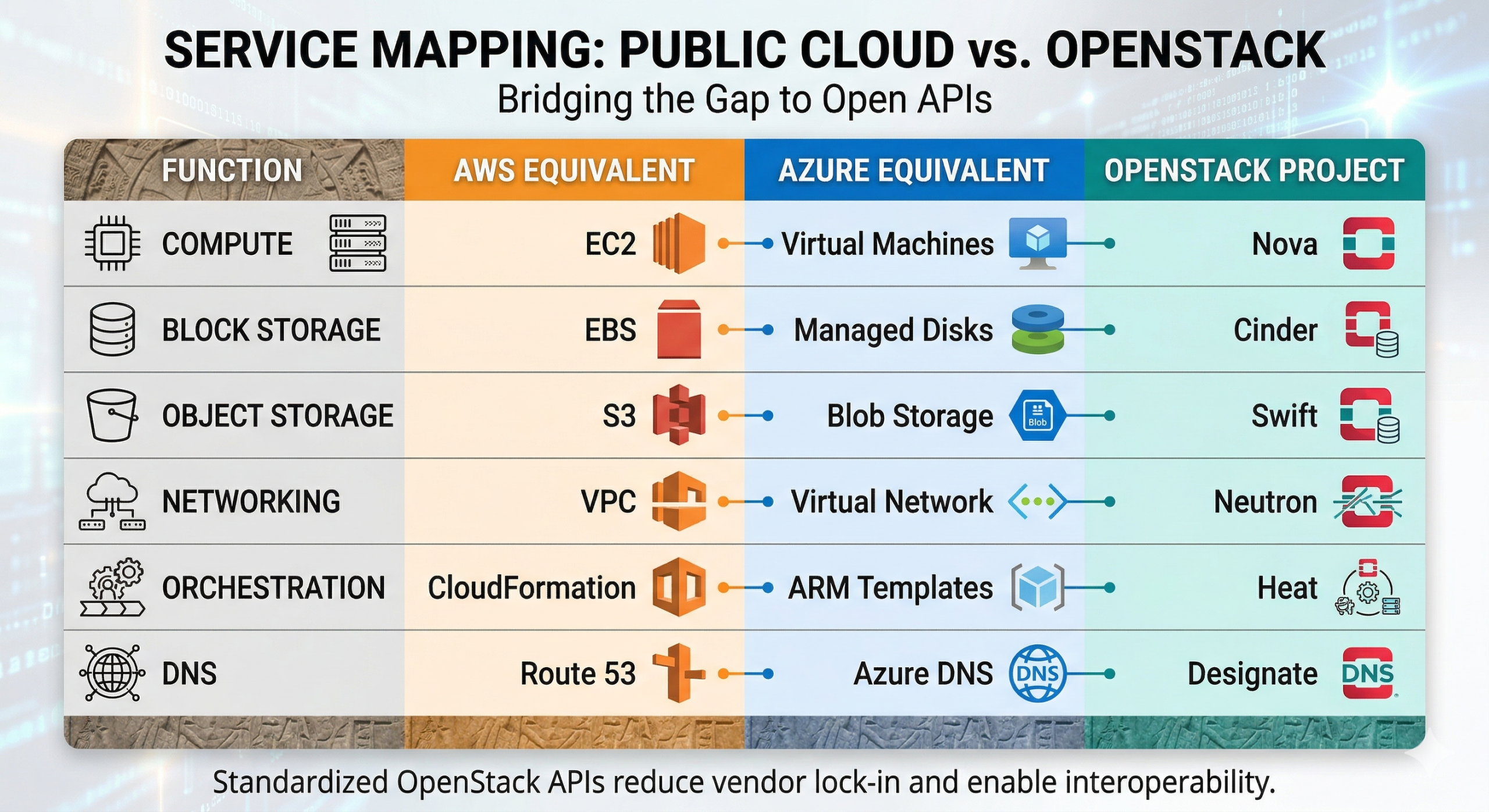
The difference from hyperscaler APIs isn’t breadth. These are open, standardized interfaces maintained by a community that includes IBM, Red Hat, Intel, and hundreds of contributing organizations. No single vendor controls the API roadmap, and no single vendor can reprice services you’ve built against.
What transfers from public cloud experience
The concern that private cloud requires starting over is largely unfounded for teams with existing cloud experience. The core operational patterns translate directly.
Terraform works natively with OpenStack. The same infrastructure-as-code workflows that manage public cloud resources work against OpenStack APIs without provider-specific rewrites. Terraform modules work across any OpenStack cloud, Ansible playbooks don’t need provider-specific conditionals, and your operations team learns one API instead of three.
Kubernetes on OpenStack behaves like Kubernetes elsewhere. CNI plugins like Calico, Cilium, or Flannel configure networking using Neutron’s APIs without provider-specific code, making pod network configuration portable because the underlying network primitives are standardized.
Container images, deployment pipelines, monitoring tooling, and most application-layer code move without modification. What changes is primarily the managed service layer, the parts of your stack that were already provider-specific. In most cases, open-source equivalents exist and are well-integrated with OpenStack environments.
What genuinely changes
Hyperscaler-native AI/ML services such as SageMaker, Vertex AI, and Azure AI have no direct OpenStack equivalent. Teams with heavy dependencies on these services would need to evaluate open-source alternatives or maintain a hybrid footprint. Similarly, applications built heavily around a provider’s serverless compute layer require rethinking, though Kubernetes-native alternatives handle most of the same use cases.
The honest framing: the more your application depends on the hyperscaler’s proprietary upper stack, the more adaptation is required. The more it depends on standardized compute, networking, storage, and container orchestration, the majority of what most applications actually need, the more directly your existing knowledge transfers. OpenMetal’s overview of cloud-native architecture on OpenStack covers how this plays out in practice for teams running production workloads.
The API Decision as a Financial Commitment
The API your team builds against today shapes your options tomorrow. An application built on open, standardized APIs can move between providers, between regions, and between deployment models without a rewrite. Code written for EC2 doesn’t work on Azure without significant changes. When you build on OpenStack, your infrastructure code is portable.
For teams evaluating cloud infrastructure for new applications, this is worth factoring in from the start. The hyperscalers offer breadth and convenience, and for some use cases those trade-offs are worth it. For teams whose core requirements are compute, storage, networking, and container orchestration, and who want predictable infrastructure costs without per-call fees on standard operations, an OpenStack-based private cloud delivers the same familiar patterns with one critical difference: the APIs are owned by no single vendor, and neither is your exit.
See how OpenMetal’s private cloud infrastructure compares on pricing and performance. Start with a free trial.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog