


































In this article
- Understanding the Multi-Tenant Challenge
- The Single-Tenant Architecture Advantage
- Built for Big Data Workloads
- Scaling Without Sacrifice
- Predictable Performance, Predictable Costs
- Real-World Data Collection Scenarios
- Monitoring and Observability at Scale
- Storage Architecture for Data Collection
- Integration with Data Processing Frameworks
- Data Governance and Compliance Considerations
- When to Choose Private Cloud for Data Collection
- Getting Started with High-Volume Data Collection
- The Competitive Advantage of Reliable Data Collection
When your business depends on collecting massive volumes of data reliably and quickly, your infrastructure choice becomes one of the most important decisions you’ll make. Whether you’re processing real-time sensor data from thousands of IoT devices, ingesting continuous event streams, or handling large batch uploads, the underlying architecture directly impacts your ability to maintain consistent performance at scale.
The challenge many data engineers face isn’t just about storage capacity or processing power, it’s about predictability. Can you trust that your data pipelines will perform the same way at 2 AM as they do during peak business hours? Will a sudden spike in data ingestion crash your system or cause cascading failures downstream?
This is where the architectural differences between single-tenant and multi-tenant cloud environments become more than just technical details. They fundamentally determine whether your data collection infrastructure becomes a competitive advantage or a constant source of operational headaches.
Understanding the Multi-Tenant Challenge
In traditional multi-tenant cloud environments, you share the same physical infrastructure with other customers. While this model works well for many use cases, it creates specific challenges for high-volume data collection workloads.
The “noisy neighbor” problem is more than just an industry buzzword. When multiple tenants share CPU, memory, storage I/O, and network resources on the same physical hardware, one tenant’s spike in usage can directly impact your performance. According to data collection experts, businesses dealing with large volumes of data face challenges where errors, inconsistencies, and inefficiencies multiply as data volume increases. In a shared environment, these challenges compound because you’re fighting not just your own workload variability but everyone else’s as well.
The unpredictability manifests in several ways. Your data ingestion pipeline might process 100,000 records per second one hour, then suddenly drop to 60,000 the next—not because your application changed, but because another tenant on the same physical host started a resource-intensive job. For batch processing jobs that need to complete within specific time windows, this variability can mean the difference between meeting SLAs and explaining to stakeholders why the morning reports aren’t ready.
Storage I/O contention is particularly problematic for data collection. When you’re writing thousands of transactions per second to disk, you need consistent, predictable IOPS. Shared storage systems, even with QoS policies, can’t completely eliminate the impact of other tenants’ workloads on your performance profile.
The Single-Tenant Architecture Advantage
Single-tenant private clouds take a fundamentally different approach. Instead of sharing physical hardware, you receive dedicated bare metal servers where you’re the only tenant consuming those resources. This architectural choice eliminates resource contention at the hardware level, not just at the virtualization layer.
OpenMetal’s single-tenant private clouds provide dedicated, bare metal hardware with no shared underlying resources. Each deployment creates isolated OpenStack environments with full root-level SSH and IPMI access, giving you complete control over your infrastructure stack. Unlike virtualized private clouds that still share physical infrastructure with other tenants, this approach leads to predictable performance for high-volume data collection by preventing other tenants from consuming shared CPU, I/O, or network resources that can cause data ingestion pipelines to fail or experience variable latency.
The difference is tangible when you’re running data-intensive workloads. Your Kafka brokers get consistent disk throughput because no other tenant is competing for I/O on the same physical drives. Your Spark jobs execute with predictable timing because the CPU cores aren’t being time-sliced with other customers’ workloads. Your network-intensive data transfers happen at wire speed because the 20Gbps connection isn’t being throttled to accommodate shared bandwidth policies.
This predictability translates directly into operational benefits. You can establish reliable performance baselines, capacity plan with confidence, and set SLAs knowing your infrastructure will deliver consistent results. Your monitoring alerts become meaningful signals rather than noise from shared resource contention.
Built for Big Data Workloads
Not all infrastructure is created equal when it comes to handling big data applications. The specific requirements of distributed data processing frameworks like Apache Hadoop, Spark, Kafka, and ClickHouse demand infrastructure that can support sustained high-throughput operations, parallel processing, and massive dataset manipulation.
OpenMetal’s platform is specifically validated for these big data workloads. The infrastructure supports the deployment patterns and performance characteristics that these frameworks require to operate efficiently at scale. When you deploy a Kafka cluster for high-volume data collection, you need not just CPU and memory but also fast, consistent disk I/O for log persistence and low-latency network connectivity between brokers.
The Ceph storage architecture that underpins the platform handles massive datasets through parallel processing capabilities and built-in redundancy. Ceph’s distributed nature means data can be written and read from multiple storage nodes simultaneously, spreading both the I/O load and the data itself across the cluster. This makes it particularly well-suited for continuous data ingestion from IoT devices, sensors, and other high-frequency data sources that generate constant write streams.
You have multiple performance tiers to choose from depending on your specific data collection patterns. For applications requiring maximum IOPS like real-time financial data ingestion or high-frequency sensor networks, direct NVMe access provides the lowest latency and highest throughput. The infrastructure uses enterprise-grade Micron 7450 and 7500 MAX NVMe drives that deliver consistent performance under sustained load.
For applications where network-attached storage makes more sense—such as distributed analytics workloads that benefit from Ceph’s built-in redundancy—you get networked triplicate copy storage that protects your data while still maintaining high performance. The 20Gbps server connectivity ensures that network bandwidth doesn’t become a bottleneck as you scale your data collection operations.
Scaling Without Sacrifice
One of the most persistent myths about private cloud infrastructure is that it can’t scale as quickly as public cloud. The reality is more nuanced. While public clouds can provision new virtual machines nearly instantly, those VMs are still sharing physical resources with other tenants. When you need to scale your data collection infrastructure, adding more VMs to an already-congested physical host doesn’t actually solve your performance problem.
OpenMetal enables you to add physical servers to existing clusters in approximately 20 minutes. These aren’t virtual instances carved out of shared hardware, they’re dedicated bare metal nodes that immediately expand your available resources without impacting existing performance. This rapid scaling supports both continuous, real-time data streams and large batch upload scenarios where you need to temporarily expand capacity.
The scaling model works particularly well for data collection because it matches how these workloads actually grow. You’re not just adding CPU or memory in isolation, you’re adding complete nodes with dedicated compute, storage, and network resources. This makes it straightforward to scale distributed data processing frameworks horizontally by simply adding more workers to your cluster.
Consider a scenario where you’re deploying new IoT sensors across a manufacturing facility. As each section comes online, your data ingestion rate increases proportionally. Rather than hoping your shared public cloud resources can handle the spike, you add dedicated nodes to your cluster. Each new node brings its own compute, storage, and network capacity, allowing your data pipelines to scale linearly without degradation.
Predictable Performance, Predictable Costs
Financial predictability matters just as much as performance predictability for infrastructure decision-making. Public cloud pricing models often work well for variable workloads, but high-volume data collection tends to be more consistent. You’re continuously ingesting data, processing it, and storing it. There’s no idle time where you can scale resources to zero.
OpenMetal’s flat-rate pricing means you won’t be surprised by your monthly bill, regardless of how much data you’re processing or storing. Data collection best practices emphasize the importance of scalable infrastructure, noting that businesses generate 2.5 quintillion bytes of data every day and need systems that can accommodate this volume cost-effectively. With dedicated hardware and flat-rate pricing, you can process and store massive amounts of data without worrying about usage-based charges escalating unexpectedly.
This pricing model aligns well with how data collection workloads operate. You know roughly how much data you’ll be collecting each month. You understand your storage growth rate. You can predict compute requirements based on your processing pipelines. With flat-rate pricing, you can translate these technical metrics directly into predictable operational costs.
The alternative—paying per compute hour, per GB stored, per GB transferred, per API call—creates a complex cost model that’s difficult to predict accurately. When you’re collecting and processing millions of events per day, those per-unit charges add up quickly. More importantly, they create detrimental incentives where architectural decisions are driven by cost avoidance rather than technical excellence.
Real-World Data Collection Scenarios
To understand how single-tenant infrastructure benefits high-volume data collection, consider several real-world scenarios where architectural choices directly impact outcomes.
IoT Sensor Networks: A smart city deployment collects data from thousands of environmental sensors, traffic cameras, and infrastructure monitors. The data arrives continuously, 24/7, with occasional spikes during events or incidents. In a multi-tenant environment, those spikes might coincide with other tenants’ peak usage, causing data loss or delayed processing. With dedicated infrastructure, the ingestion pipeline handles spikes predictably because the available resources are guaranteed.
Financial Data Processing: A trading platform ingests market data feeds from multiple exchanges, requiring both high throughput and low latency. Even milliseconds of delay caused by resource contention can impact trading decisions. Single-tenant infrastructure ensures that market data processing never competes with other tenants’ workloads for CPU time or network bandwidth. Research on cloud big data infrastructure shows that enhanced data processing speed is one of the key benefits, allowing businesses to gain real-time insights and respond swiftly to market dynamics.
Healthcare Data Integration: A health system aggregates patient data from multiple sources including EHRs, wearables, lab systems, and imaging devices. Data quality and completeness are essential for clinical decision support. Inconsistent performance in the ingestion pipeline could mean missing data points that matter for patient care. Dedicated resources ensure that health data flows consistently from source systems to analytics platforms.
E-commerce Analytics: An online retailer collects clickstream data, transaction events, and inventory updates across multiple channels. According to research on high-volume data capture, a large e-commerce retailer implementing automated data capture with rigorous validation achieved a 35% reduction in data errors and a 25% improvement in delivery accuracy, directly contributing to stronger sales and reduced operational costs. Processing this data in real-time enables dynamic pricing, personalized recommendations, and inventory optimization. Performance variability in the data pipeline directly impacts the customer experience and business metrics.
Monitoring and Observability at Scale
When you’re collecting massive volumes of data, comprehensive monitoring is essential. You need visibility into every layer of your infrastructure stack to understand where bottlenecks might emerge and how your system performs under different load patterns.
With full root-level SSH and IPMI access, you can deploy monitoring agents at every level of your stack. You can track CPU utilization, memory consumption, disk I/O patterns, and network throughput at the bare metal level. You can monitor your storage cluster’s health, replication status, and capacity utilization. You can instrument your application layer to track data ingestion rates, processing latency, and pipeline health.
This deep observability becomes particularly valuable when troubleshooting performance issues. In a multi-tenant public cloud, you might see degraded performance without being able to determine the cause since you don’t have visibility into what other tenants are doing on the shared hardware. With dedicated infrastructure and full access, you can correlate performance changes directly to specific system metrics and application behaviors.
The ability to establish reliable baselines is equally important. When your infrastructure performance is consistent, your monitoring data becomes predictable. You can set meaningful alert thresholds that indicate actual problems rather than just responding to the natural variability of shared resources. Your capacity planning becomes data-driven because historical performance is a reliable indicator of future performance.
Storage Architecture for Data Collection
The storage layer is often the bottleneck in data collection pipelines, particularly when handling continuous writes from multiple sources. How you architect storage directly impacts your ability to ingest data reliably at high volumes.
Ceph’s distributed storage architecture provides several advantages for data collection workloads. Data is automatically distributed across multiple storage nodes in the cluster, which means write operations can happen in parallel rather than serializing through a single bottleneck. The built-in redundancy—with triplicate copies maintained by default—ensures that data remains available even if individual nodes fail, which is critical when you’re collecting data that can’t be easily regenerated.
The parallel processing capabilities of Ceph mean that as you add storage nodes to your cluster, both capacity and performance scale together. You’re not just getting more space to store data, you’re getting more I/O throughput to write and read data. This aligns well with data collection needs where both volume and velocity tend to grow together over time.
For use cases requiring the absolute highest performance, direct NVMe access bypasses the network layer entirely. Your applications write directly to local NVMe drives, achieving the lowest possible latency and highest possible throughput. This makes sense for applications like time-series databases or streaming analytics where write speed directly impacts the system’s ability to keep up with incoming data.
The choice between networked storage and direct NVMe often comes down to your specific requirements around redundancy, access patterns, and performance. Some organizations run hybrid architectures where hot data lives on NVMe for fast access while older data moves to networked Ceph storage for cost-effective long-term retention.
Integration with Data Processing Frameworks
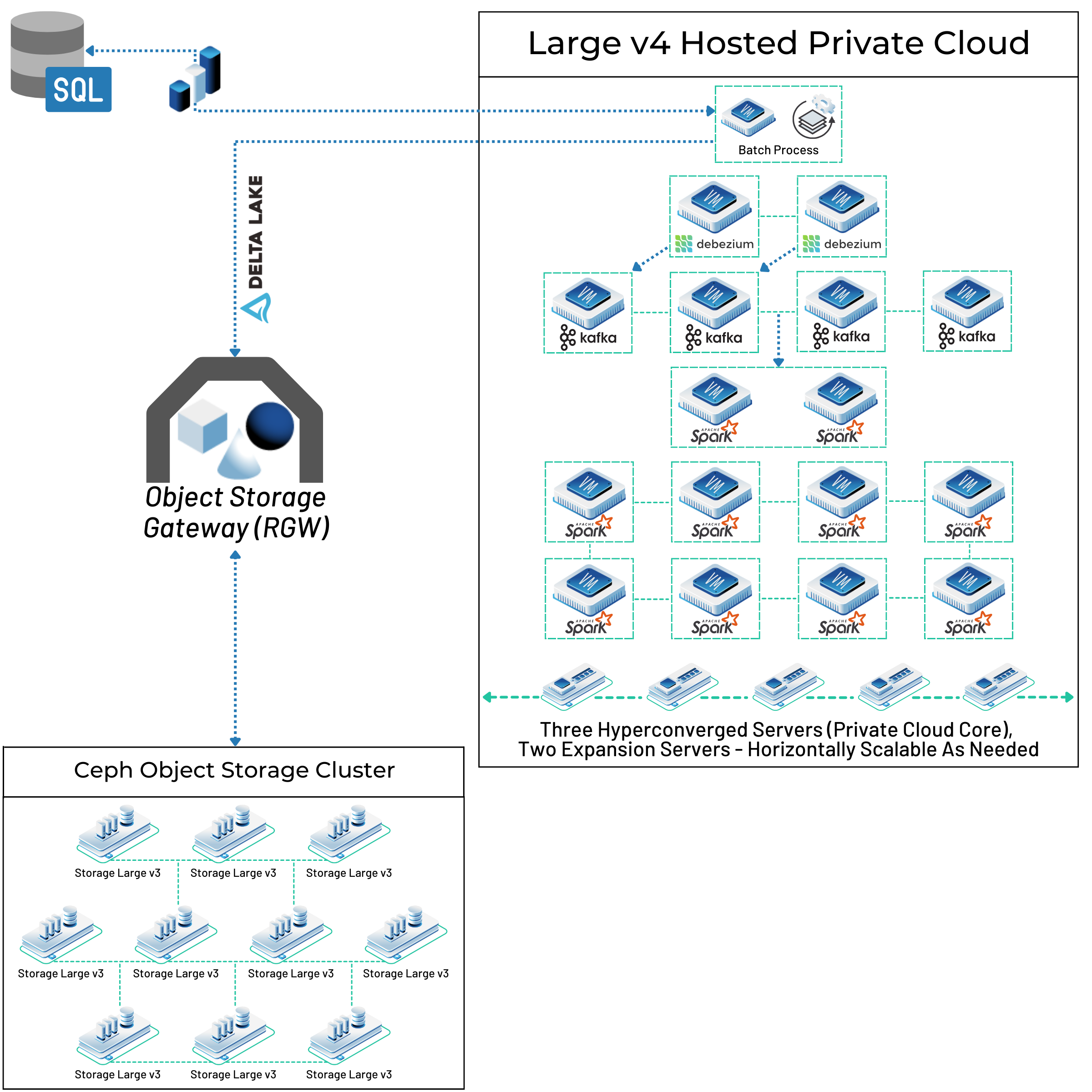
High-volume data collection rarely happens in isolation. The collected data needs to flow into processing frameworks, analytics engines, and downstream applications. Your infrastructure needs to support not just the collection itself but the entire data pipeline.
Modern big data frameworks like Apache Spark, Flink, and Storm are designed to process data in parallel across distributed clusters. They work best when the underlying infrastructure can provide consistent performance across all nodes in the cluster. In a multi-tenant environment, having some nodes on congested physical hosts while others aren’t creates imbalanced processing that reduces overall cluster efficiency.
With dedicated infrastructure, you can architect your data processing clusters knowing that every node will deliver consistent performance. Your Spark executors all have the same amount of available CPU, memory, and I/O bandwidth. Your Flink task managers can parallelize workloads evenly across the cluster without worrying about some nodes becoming bottlenecks due to resource contention.
The network performance between nodes also matters for distributed processing. Many big data operations involve shuffling data between nodes—sorting operations, joins, and aggregations all require moving data across the network. The 20Gbps connectivity between servers ensures that network bandwidth doesn’t limit your processing throughput, even when handling terabyte-scale shuffles.
For guidance on building complete data pipelines, you might want to explore our resources on building modern data lakes using open source tools or architecting high-speed ETL with Spark, Delta Lake, and Ceph.
Data Governance and Compliance Considerations
As data volumes grow, so does the complexity of managing that data according to regulatory requirements and internal policies. Where your data physically resides, who has access to it, and how it’s protected all become important considerations.
Data governance best practices recommend establishing clear policies for data collection, storage, access, and usage from the beginning. With single-tenant infrastructure, you have complete control over the physical and logical security of your environment. You’re not sharing compute or storage resources with other organizations, which simplifies compliance with regulations around data isolation.
For organizations dealing with sensitive data—whether that’s personal health information, financial records, or proprietary business data—the ability to physically isolate infrastructure becomes a meaningful compliance advantage. You can implement security controls at every layer of the stack without worrying about shared resources creating potential cross-tenant vulnerabilities.
The full access to your infrastructure also allows for comprehensive audit logging. You can track every interaction with your systems, log all data access patterns, and maintain detailed records for compliance purposes. This level of visibility and control is difficult to achieve in multi-tenant environments where you don’t have access to the physical and virtualization layers.
For more information about data governance in private cloud environments, see the discussion of achieving data sovereignty and governance for big data.
When to Choose Private Cloud for Data Collection
Not every data collection workload requires single-tenant infrastructure. Understanding when the benefits justify the architectural choice helps you make informed decisions about where to run different parts of your data ecosystem.
Consider single-tenant private cloud when:
Your data collection is continuous and predictable: If you’re ingesting data 24/7 at relatively consistent rates, flat-rate pricing on dedicated resources typically costs less than pay-per-use pricing on shared resources. The performance predictability also becomes more valuable when data collection is mission-critical.
Performance variability creates business risk: When degraded performance means lost data, missed SLAs, or poor customer experiences, eliminating the noisy neighbor problem becomes worth the infrastructure choice. If you’re processing real-time data streams where delays compound downstream, predictable performance matters.
You need high resource utilization: Multi-tenant environments often require over-provisioning to handle performance variability. With dedicated resources, you can run at higher utilization levels without degradation. This makes single-tenant infrastructure more cost-effective at scale than it first appears.
Compliance requires physical isolation: Some regulatory frameworks make shared infrastructure difficult or impossible. Single-tenant private clouds provide the physical and logical isolation needed to meet these requirements.
You’re running distributed data processing: Applications like Hadoop, Spark, and Kafka perform best with consistent performance across all cluster nodes. Dedicated infrastructure ensures that your processing clusters work efficiently without performance imbalances caused by resource contention.
For more context on making this decision, review the comparison of when to choose private cloud over public cloud for big data and explore understanding big data infrastructure options.
Getting Started with High-Volume Data Collection
If you’re currently struggling with inconsistent performance in your data collection pipelines, or if you’re planning to deploy new data-intensive applications, evaluating your infrastructure architecture should be part of the solution.
Start by benchmarking your current performance. Track not just average metrics but also variance: How much does your ingestion rate fluctuate? What’s the difference between your best and worst performance? How often do you see degraded performance that impacts your SLAs? This baseline helps you understand the cost of performance unpredictability in your current environment.
Map out your data collection patterns. How much data are you collecting per hour, per day, per month? What are your peak rates versus average rates? What’s your data retention policy, and how does that impact storage growth? Understanding these patterns helps you right-size dedicated infrastructure and predict costs accurately.
Consider your integration requirements. What processing frameworks need to consume this collected data? What analytics tools need access to it? How does data flow through your environment from collection through processing to presentation? Your infrastructure needs to support the entire pipeline, not just the collection endpoint.
For organizations ready to deploy dedicated infrastructure for data collection, OpenMetal’s hosted private cloud provides the foundation. You can explore storage cluster options that match your performance and capacity requirements. Use the cloud deployment calculator to estimate infrastructure requirements based on your data collection patterns, or review storage cluster pricing to understand cost models.
The Competitive Advantage of Reliable Data Collection
In data-driven organizations, the quality and timeliness of data collection directly impacts every downstream decision. When your infrastructure delivers consistent, predictable performance, you can build reliable systems on top of it. When performance is variable and unpredictable, that variability propagates through your entire data ecosystem.
The difference between 99% uptime and 99.9% uptime might seem small on paper—just 8.76 hours versus 52.56 minutes of downtime per year. But for data collection pipelines processing millions of events per day, those hours of downtime represent millions of potentially lost data points. In multi-tenant environments where you don’t control the physical infrastructure, you’re always vulnerable to another tenant’s workload impacting your availability.
Single-tenant private clouds eliminate an entire class of performance and reliability problems by removing resource contention at the hardware level. Your data collection infrastructure becomes a stable foundation you can build on, rather than a variable you have to work around.
As organizations continue to generate more data from more sources, the ability to collect that data reliably at high volumes becomes increasingly central to business success. The infrastructure choices you make today determine whether your data collection capabilities become a competitive advantage or a limiting factor in what you can achieve.
The question isn’t whether to collect more data—market pressures and business opportunities are driving data collection across every industry. The question is whether your infrastructure can handle that collection reliably, predictably, and cost-effectively as you scale. For organizations where the answer matters, single-tenant private cloud infrastructure provides a proven path forward.
For technical teams evaluating infrastructure for big data workloads, exploring the differences between shared and dedicated architectures helps clarify which model aligns with your requirements. The rise of open source big data tools, discussed in the rise of open source in big data, has made it easier than ever to build sophisticated data collection and processing pipelines. The remaining question is what infrastructure those pipelines run on.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog