



































Evaluating persistent storage options for Nomad or any CSI-compatible orchestrator?
Talk to us about the OpenStack + Ceph architecture in the context of your workloads.
Containers are disposable by design. You scale them up, tear them down, and reschedule them across nodes without a second thought. But the moment a container writes data that must survive that cycle — a database commit, a queue offset, a write-ahead log entry — the problem shifts from scheduling to storage.
Persistent storage for Nomad workloads depends less on the orchestrator itself and more on what sits beneath it. This article walks through how HashiCorp Nomad consumes persistent block storage via the Container Storage Interface (CSI) specification, how OpenStack Cinder backed by Ceph RBD (RADOS Block Device) provides that storage from a programmable infrastructure layer, and why this architecture — as implemented on OpenMetal’s dedicated clouds — delivers scheduler-agnostic portability without sacrificing performance predictability.
Key Takeaways
- Nomad supports CSI natively. Persistent volume provisioning, attachment, detachment, expansion, and snapshots are handled through CSI plugins that run as standard Nomad jobs
- OpenStack Cinder + Ceph RBD provides open-source, API-driven block storage. Cinder manages volume lifecycle through a REST API. Ceph distributes and replicates data across OSDs using CRUSH maps. The
cinder-csi-pluginbridges CSI to Cinder - Scheduler-agnostic infrastructure means your storage survives orchestrator changes. The same Cinder API, the same Ceph cluster, and the same RBD volumes work whether consumed by Nomad, Kubernetes, or both
- Dedicated infrastructure delivers predictable storage I/O. No shared hypervisors, no noisy neighbors, no contention for disk or network bandwidth. OpenMetal’s dedicated OpenStack + Ceph clouds give you full control over storage configuration and performance tuning
- Fixed-cost pricing removes variable-rate storage billing. Predictable infrastructure costs based on hardware provisioned, not metered usage — a simpler model for teams forecasting storage spend as data volumes grow
Stateless Is Easy. State Is Hard.
Stateless containers are the easy part of orchestration. They start, serve traffic, and die. If one fails, another takes its place. No data to migrate, no volumes to reattach, no consistency guarantees to uphold.
Stateful workloads — databases, message queues, caches with persistence, event stores — break that model. When a PostgreSQL container on VM-1 needs to be rescheduled to VM-2, its data volume must detach from one host and reattach to another without corruption. The orchestrator manages the container lifecycle. But the infrastructure layer manages the storage lifecycle. Most teams focus on the first and assume the second will sort itself out.
That assumption is where architectural debt accumulates. The answer to “where does my data live and how does it move?” depends on four technologies working together:
- Nomad (HashiCorp’s workload orchestrator, which schedules containers, VMs, and standalone binaries)
- CSI (Container Storage Interface — an open specification that lets orchestrators request and manage storage volumes from any compatible backend)
- Cinder (OpenStack’s block storage service and API), and
- Ceph RBD (RADOS Block Device — distributed, replicated block storage from the Ceph software-defined storage system).
Similar to how stateful database workloads benefit from dedicated infrastructure, stateful containers need an infrastructure layer that treats storage as a first-class concern.
What Nomad and CSI Actually Require
When a Nomad job specification declares a persistent volume, Nomad doesn’t provision that volume itself. It delegates to a CSI plugin — a pair of components (a controller plugin and a node plugin) that translate between the orchestrator’s volume requests and the actual storage backend.
The CSI specification defines this interaction through gRPC-based RPCs. The controller plugin handles volume lifecycle: CreateVolume, DeleteVolume, ControllerPublishVolume (attaching a volume to a node), and ControllerUnpublishVolume (detaching it). The node plugin handles host-side operations: NodeStageVolume (preparing the volume, such as formatting the filesystem) and NodePublishVolume (mounting it into the container’s filesystem). Together, these RPCs abstract the storage backend entirely. The orchestrator doesn’t need to know whether the underlying volume is an EBS disk, a GCP Persistent Disk, or a Ceph RBD image.
Nomad’s CSI implementation has one architectural distinction worth noting. In Kubernetes, CSI plugins typically run as DaemonSets — system-level pods managed by Kubernetes itself. In Nomad, CSI plugins run as Nomad jobs. The controller plugin runs as a service job, and the node plugin runs as a system job across all client nodes. This means the infrastructure beneath Nomad must natively support the storage backend that the CSI driver targets. There’s no managed abstraction hiding the plumbing.
CSI solves the interface between orchestrator and storage.
But what actually provides the storage? And does the answer lock you into a specific provider?
The Infrastructure Layer Most Teams Overlook
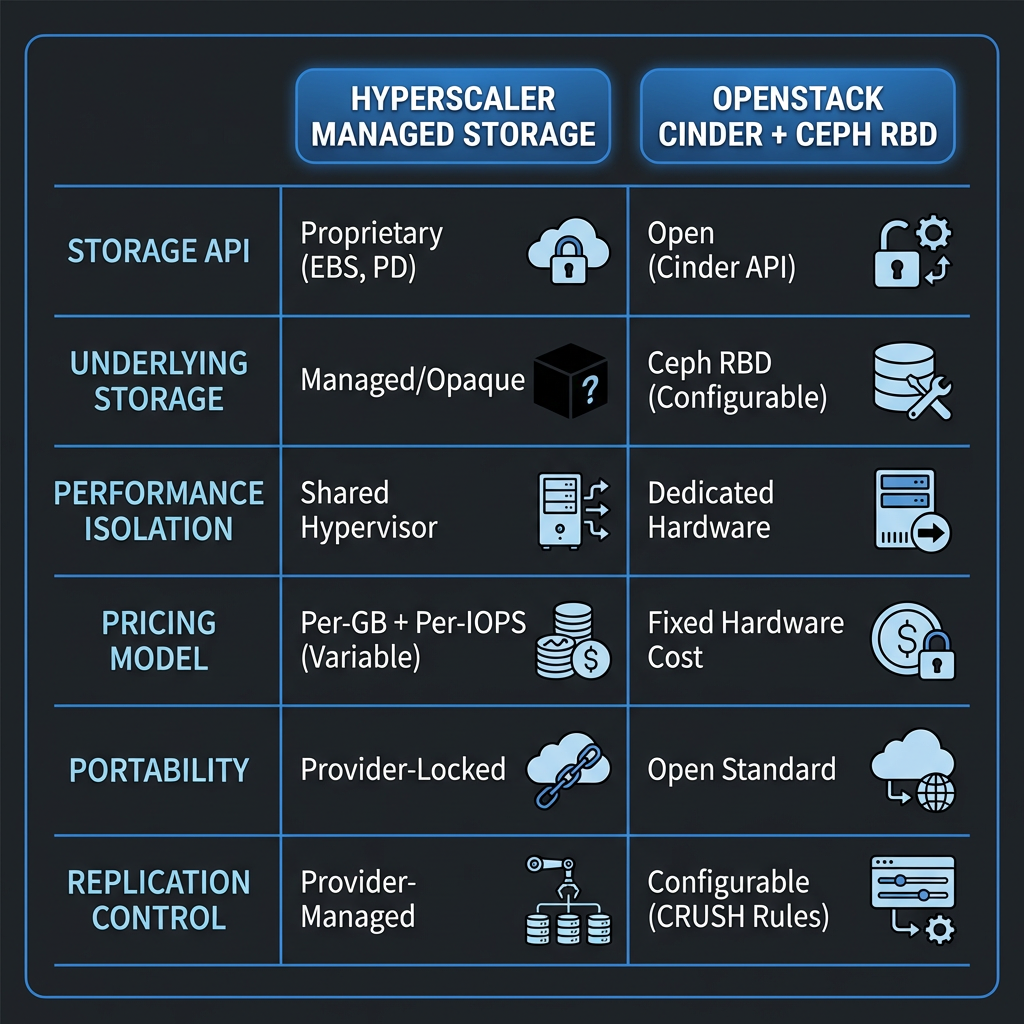 When teams deploy Nomad on a hyperscaler — AWS, GCP, or Azure — they typically reach for that provider’s managed block storage. On AWS, the Cinder CSI driver is swapped for the EBS CSI driver. On GCP, it’s the Persistent Disk CSI driver. The CSI abstraction works as designed: Nomad talks to the plugin, the plugin talks to the provider’s API, volumes attach and detach.
When teams deploy Nomad on a hyperscaler — AWS, GCP, or Azure — they typically reach for that provider’s managed block storage. On AWS, the Cinder CSI driver is swapped for the EBS CSI driver. On GCP, it’s the Persistent Disk CSI driver. The CSI abstraction works as designed: Nomad talks to the plugin, the plugin talks to the provider’s API, volumes attach and detach.
The problem isn’t functionality. It’s portability. EBS snapshots use an AWS-proprietary format. Replication policies are configured through AWS-specific APIs. Encryption is managed by AWS KMS. Performance tiers (gp3, io2, etc.) are AWS constructs with no equivalents on other providers. You can copy the bytes off an EBS volume, but you can’t copy the management layer. The storage interface is portable (CSI). The storage implementation is not.
Now consider the alternative. If your infrastructure provides block storage through an open API — OpenStack Cinder — backed by an open distributed storage system — Ceph — the same CSI interface works. But the data, the management API, the replication logic, and the encryption configuration all run on infrastructure you control. Every component in the stack is open source and speaks documented protocols.
This is what we mean by scheduler-agnostic infrastructure: an infrastructure layer that delivers storage through open interfaces so that any orchestrator speaking CSI can consume it. The storage architecture doesn’t change when you switch schedulers, add a second orchestrator, or migrate between environments. The full path looks like this:
Nomad → CSI driver (cinder-csi-plugin) → OpenStack Cinder API → Ceph RBD → Distributed storage cluster
Every link in that chain is based on an open specification or open-source implementation. No proprietary API gates access to your data.
How OpenStack + Ceph Deliver Dynamic Block Storage
OpenStack Cinder acts as the control plane for block storage. It receives API requests to create, attach, detach, snapshot, extend, and delete volumes. Cinder itself doesn’t store data — it delegates to a backend driver. In most production OpenStack deployments, that backend is Ceph RBD.
When Cinder creates a volume, it instructs the Ceph RBD driver to create a corresponding RBD image in a designated Ceph pool. Ceph distributes the image’s data across its OSD (Object Storage Daemon) cluster using CRUSH maps — an algorithm that determines data placement across failure domains. By default, each block of data is replicated three times across separate OSDs, ensuring that no single disk or node failure results in data loss.
The cinder-csi-plugin, maintained as part of the OpenStack cloud-provider project, implements the CSI gRPC specification and translates CSI calls into Cinder API calls. Despite its home in the Kubernetes cloud-provider-openstack repository, this driver conforms to the CSI spec and works with any CSI-compatible orchestrator — including Nomad.
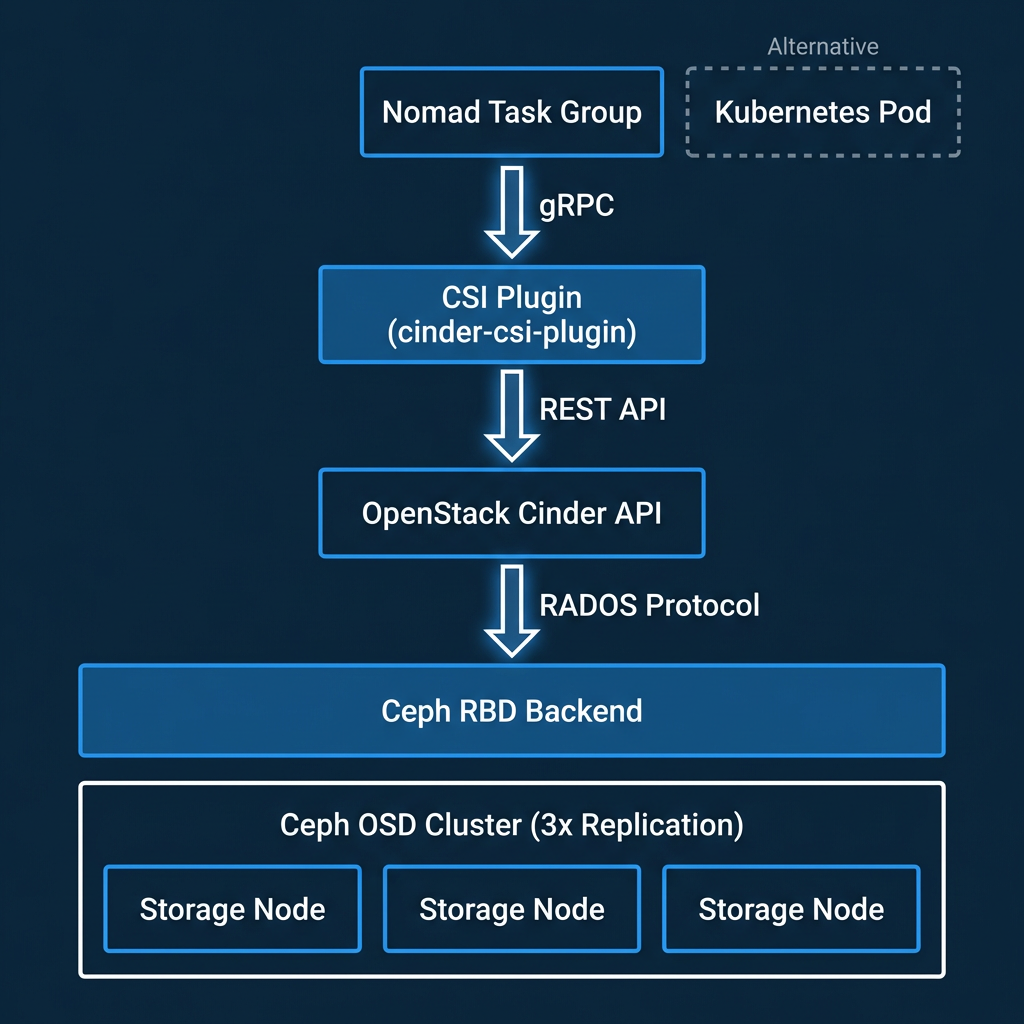 Here’s what the full lifecycle looks like for a Nomad workload:
Here’s what the full lifecycle looks like for a Nomad workload:
A Nomad job declares a CSI volume requirement. The Cinder CSI controller plugin calls the Cinder API to create a new volume, which triggers creation of an RBD image in a Ceph pool. Cinder then attaches that volume to the Nomad client VM by mapping the RBD image to the node’s kernel. The CSI node plugin formats and mounts the volume into the container’s filesystem. The container sees a standard block device.
When Nomad reschedules that workload to a different VM — due to a node failure, a rolling update, or a rebalancing decision — the CSI plugin detaches the RBD image from the old node and reattaches it to the new one. The data doesn’t move. The Ceph cluster continues serving the same RBD image; only the client mapping changes. Snapshots are handled at the Ceph layer: consistent, point-in-time, and completely independent of which orchestrator initiated them.
How OpenMetal Implements This in Dedicated Clouds
The architecture described above works on any OpenStack + Ceph deployment. What changes on OpenMetal is the infrastructure context — and that context directly affects storage performance and operational control.
Every OpenMetal cloud runs on dedicated hypervisors. Your OpenStack compute and Ceph storage nodes aren’t shared with other tenants. There are no noisy neighbors competing for disk I/O or network bandwidth. When your Ceph OSDs write replicated data, they’re writing to dedicated NVMe drives over dedicated network links. Storage latency is predictable because the hardware isn’t contended.
Ceph-backed block storage with RBD is a native capability of every OpenMetal Hosted Private Cloud deployment — not an add-on or premium tier. Ceph is deployed as part of the infrastructure from day one, with pools, replication factors, and CRUSH rules configurable per workload. A team running PostgreSQL on Nomad can configure a Ceph pool with 3x replication and SSD-only placement, while a different workload uses a separate pool tuned for throughput over latency.
Private networking via VLAN and VXLAN means Ceph replication traffic and Cinder API traffic traverse isolated networks, not shared infrastructure. This matters for both latency (replication hops stay on a private fabric) and data sovereignty (storage traffic never touches a public network).
Full root access to VMs means you install and configure the cinder-csi-plugin, Nomad, and any other components without restrictions or support tickets. OpenMetal provides the infrastructure that makes Nomad’s CSI integration work with predictable performance. It’s not a managed Nomad service — it’s dedicated infrastructure that supports whatever orchestrator you choose to run on it.
Bonded NICs deliver predictable network throughput across the cluster, ensuring that Ceph replication and client I/O aren’t bandwidth-limited by shared uplinks. When you provision storage on OpenMetal, the performance characteristics are determined by the hardware you’ve allocated — not by a shared-resource scheduling algorithm you can’t inspect.
Beyond Kubernetes: Why Scheduler Choice Should Not Dictate Storage
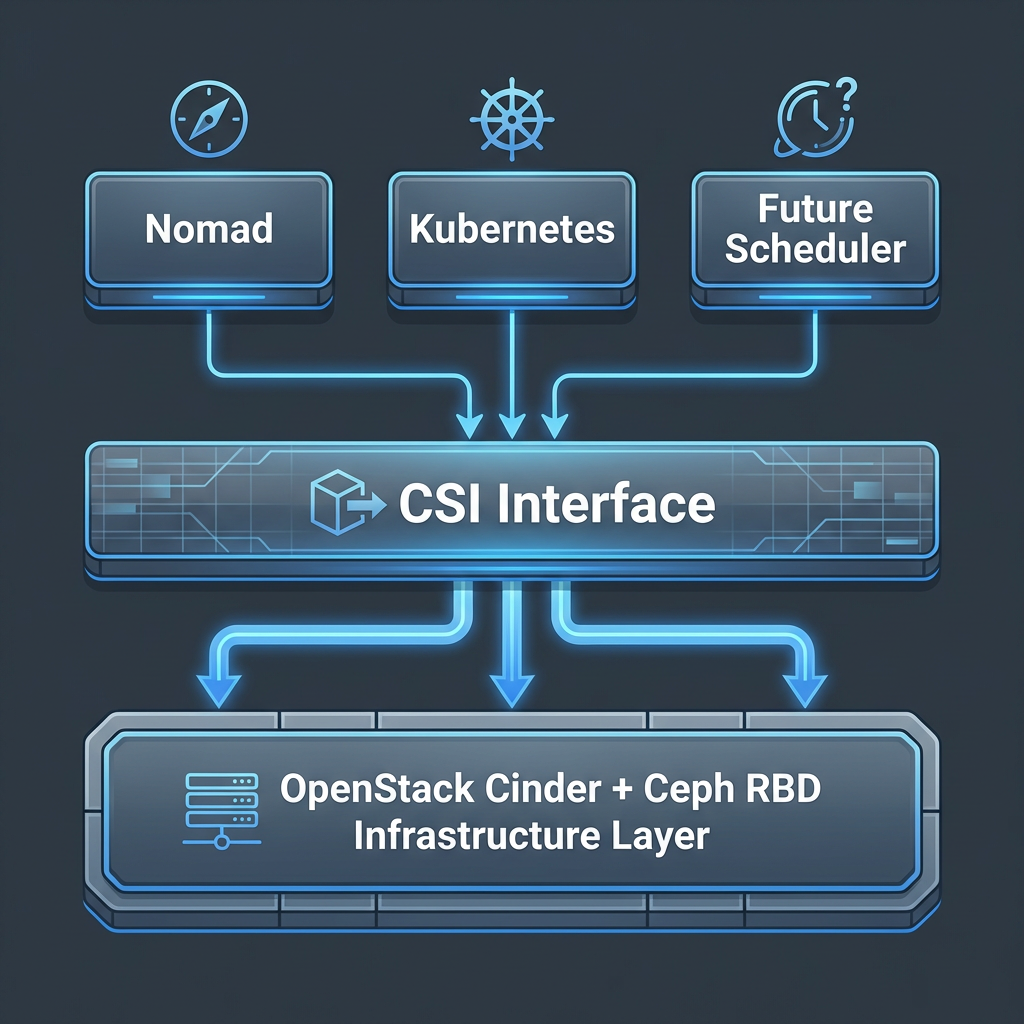 Most CSI documentation, tutorials, and tooling assume Kubernetes. This creates an implicit assumption that persistent container storage is a Kubernetes concern. It isn’t. CSI is a specification — a set of gRPC RPCs that any orchestrator can implement. Nomad implemented CSI support precisely because the specification is orchestrator-neutral.
Most CSI documentation, tutorials, and tooling assume Kubernetes. This creates an implicit assumption that persistent container storage is a Kubernetes concern. It isn’t. CSI is a specification — a set of gRPC RPCs that any orchestrator can implement. Nomad implemented CSI support precisely because the specification is orchestrator-neutral.
Scheduler-agnostic infrastructure means your storage architecture survives orchestrator changes. Run Nomad today and migrate to Kubernetes later — or run both simultaneously for different workload types — without re-architecting your storage layer. The Cinder API, the Ceph cluster, and the RBD volumes remain exactly where they are. Only the CSI plugin deployment changes.
This matters because teams increasingly choose Nomad for workloads that don’t need Kubernetes’ complexity — batch processing, mixed container-and-binary deployments, simpler service topologies. Companies like Roblox, Cloudflare, and eBay run Nomad in production at scale. These teams still need persistent storage. The infrastructure shouldn’t force them into Kubernetes to get it.
Control, Portability, and Predictable Performance
Three strategic advantages emerge from this architecture.
Control
Full root access, configurable Ceph parameters (pool sizes, replication factors, CRUSH placement rules), private networking, and no vendor-managed abstractions between your orchestrator and your data. You can inspect, tune, and audit every layer of the storage path — from the CSI plugin configuration to the Ceph OSD journal settings.
Portability
Data stored in Ceph RBD images, managed through the Cinder API, consumed via the CSI specification. Every component is open source and every interface is documented. You can move this architecture between OpenStack deployments or across data centers without rewriting your storage integration.
Predictable performance
Dedicated hardware eliminates contention. Bonded NICs deliver consistent network throughput. And fixed-cost pricing from OpenMetal means no variable storage bills that scale unpredictably with IOPS or GB-months. Hyperscaler block storage is priced per-GB-month plus per-IOPS, which makes cost forecasting difficult for workloads with growing data volumes. On dedicated infrastructure with Ceph, storage cost is determined by the hardware provisioned — not by metered usage. For teams with predictable storage requirements, this is a more forecastable cost model.
If you’re evaluating persistent storage options for Nomad or any CSI-compatible orchestrator, we’d welcome a conversation about the OpenStack + Ceph architecture in the context of your workloads.
Frequently Asked Questions
Does Nomad support persistent storage natively?
Yes. Nomad supports persistent storage through the Container Storage Interface (CSI) specification. CSI plugins run as Nomad jobs — a controller plugin manages volume lifecycle (create, attach, detach, delete) and a node plugin handles host-side mounting. Any storage backend with a CSI-compliant driver works with Nomad, including OpenStack Cinder backed by Ceph RBD.
Can I use the same storage volumes with both Nomad and Kubernetes?
When your storage is managed through OpenStack Cinder and backed by Ceph RBD, the same volumes are accessible from any orchestrator that supports the cinder-csi-plugin. The Cinder API and Ceph cluster don’t care which scheduler initiated the volume request. You can run Nomad and Kubernetes side by side on the same OpenStack infrastructure and consume storage from the same Ceph pools — though a single volume should only be attached to one orchestrator at a time.
What happens to data when Nomad reschedules a stateful workload to a different VM?
The CSI plugin detaches the Ceph RBD image from the original VM and reattaches it to the new one. The data itself doesn’t move — it stays distributed across the Ceph OSD cluster. Only the client-side mapping changes, which means the reattach operation is fast and the data remains consistent throughout the reschedule.
How does Ceph RBD on dedicated hardware compare to hyperscaler block storage like EBS?
The primary differences are control, portability, and pricing model. With Ceph RBD on dedicated infrastructure, you configure replication factors, CRUSH placement rules, and pool settings directly. Storage is accessed through open APIs (Cinder, CSI) rather than proprietary ones. And pricing is fixed based on hardware provisioned rather than variable per-GB and per-IOPS metering — which makes cost forecasting simpler for workloads with predictable storage needs.
Do I need to manage Ceph myself on OpenMetal?
OpenMetal deploys Ceph as part of every Hosted Private Cloud. The Ceph cluster runs on dedicated hardware with Cinder integration configured from day one. You get full access to tune pool settings, replication factors, and CRUSH rules for your workloads, but the underlying infrastructure — hardware, networking, Ceph deployment — is managed by OpenMetal.
More Storage based Technical Articles