


































In this article
- Understanding the PoC to Production Challenge
- Starting Your Journey with OpenMetal’s Trial Programs
- The Foundation: Understanding Cloud Cores
- Strategic Expansion Paths Beyond the Core
- GPU Acceleration for AI and ML Workloads
- Architectural Flexibility: Multi-Region and Hierarchical Deployments
- The Economics of Private Cloud Scaling
- Capacity Planning: Avoiding Common Pitfalls
- Maintaining Infrastructure Consistency at Scale
- Scaling Strategies: MicroVMs and Workload Optimization
- Operational Maturity: From PoC to Production-Ready
- The Path Forward: Continuous Improvement
- Conclusion
Moving from proof of concept to production represents one of the most challenging transitions in infrastructure projects. You’ve validated your idea works, demonstrated its viability to stakeholders, and now face the question: how do you scale this into a production environment that serves real workloads reliably?
OpenMetal’s approach to private cloud scaling differs fundamentally from traditional public cloud expansion. Rather than worrying about runaway costs as you add resources, you can start with production-grade infrastructure from day one and scale strategically based on your actual workload patterns.
Understanding the PoC to Production Challenge
A proof of concept serves a specific purpose: validating feasibility with minimal investment. It demonstrates that your idea works under controlled conditions with clean data and limited scope. However, production environments demand something entirely different.
The transition from PoC to production involves multiple dimensions of scalability that many teams underestimate. You’re not simply handling more users or larger datasets. You’re addressing infrastructure capacity, data type diversity, feature expansion, and model management simultaneously. Each dimension presents distinct challenges that require deliberate planning.
Many organizations discover that their PoC, built with hardcoded variables and manual workarounds, cannot survive the transition to production without extensive refactoring. The code that worked perfectly for demonstrating feasibility often lacks the error handling, monitoring, and operational characteristics production workloads demand.
Starting Your Journey with OpenMetal’s Trial Programs
OpenMetal removes the traditional barriers between testing and production by providing enterprise-grade infrastructure and access from the start. Self-Serve Trials offer three 8-hour deployment periods per month, giving you rapid testing cycles without commitment. For more extensive validation, Proof of Concept Trials run 5-30 days with complete access to production-ready infrastructure along with engineer-to-engineer and executive support as needed. Companies with validated production workloads can access extended trial periods to thoroughly test migration strategies.
Unlike traditional PoC environments that require rebuilding for production, OpenMetal trials deploy the same infrastructure you’ll use in production. This means your validation work translates directly into your production environment without architectural rewrites.
The Foundation: Understanding Cloud Cores
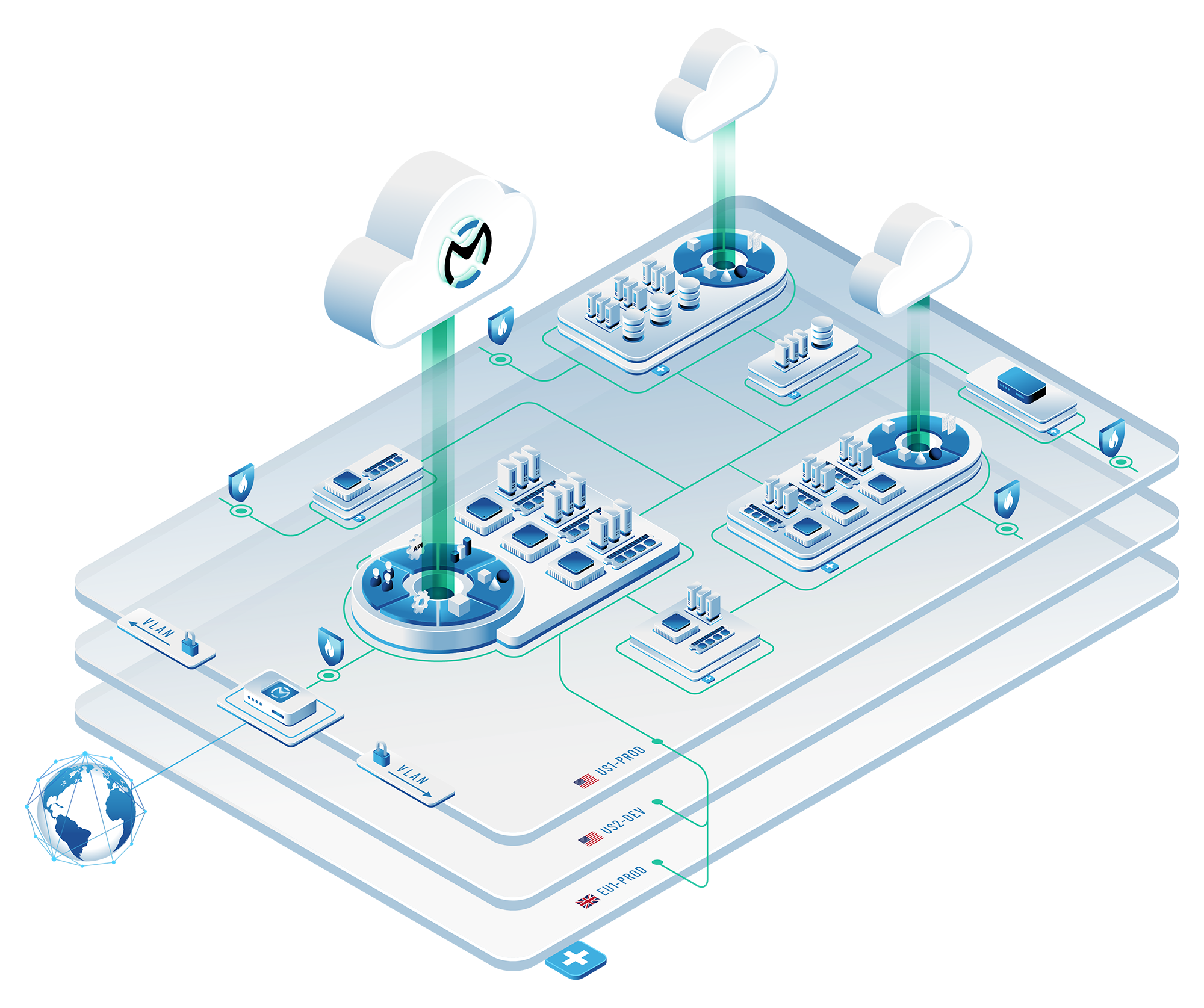
Every OpenMetal private cloud begins with a Cloud Core: three hyperconverged servers that deploy in approximately 45 seconds. This isn’t a minimal testing environment. It’s a production-ready foundation providing high availability control plane, HA Ceph-based block and object storage, and compute capabilities through OpenStack.
The three-server minimum isn’t arbitrary. This configuration enables proper Ceph redundancy with three data copies and establishes a highly available control plane that survives individual server failures. You receive full root access with Kolla-Ansible and Ceph-Ansible deployment tools, giving you complete control over your infrastructure.
Hardware tiers v1 through v4 are available based on your performance and capacity requirements. This tiered approach allows you to match your Cloud Core specifications to your workload demands without overpaying for unnecessary capacity.
Strategic Expansion Paths Beyond the Core
After launching your Cloud Core, expansion follows multiple paths depending on workload requirements. Understanding these options helps you scale efficiently without overspending.
Converged Nodes: The Most Popular Expansion Choice
 Converged nodes (also called storage and compute nodes) represent the most common expansion option for growing workloads. These servers match your Cloud Core specifications identically, preserving features like live VM migration that depend on hardware consistency.
Converged nodes (also called storage and compute nodes) represent the most common expansion option for growing workloads. These servers match your Cloud Core specifications identically, preserving features like live VM migration that depend on hardware consistency.
This approach works particularly well when your workload growth follows predictable patterns and you need balanced compute and storage expansion. Adding converged nodes increases both processing capacity and network storage proportionally, maintaining the architectural consistency of your cloud.
Compute Nodes: High-Performance Local Storage
 Compute nodes offer standalone server expansion without requiring Cloud Core matching. The key distinction lies in storage configuration: drives are configured as single drives or local RAID rather than joining network storage pools.
Compute nodes offer standalone server expansion without requiring Cloud Core matching. The key distinction lies in storage configuration: drives are configured as single drives or local RAID rather than joining network storage pools.
This configuration provides direct access to extremely high IOPS NVMe drives without network overhead. For workloads requiring maximum storage performance—databases with intensive read/write patterns, analytics processing, or rendering operations—compute nodes deliver performance that network storage cannot match.
VMs running on compute nodes can still access network storage from the Cloud Core when needed. This flexibility allows you to optimize each workload for its specific performance characteristics.
Storage Clusters: Purpose-Built Capacity
 Storage clusters consist of standalone clusters of three or more servers providing network storage exclusively—block storage, object storage, and file systems without compute allocation.
Storage clusters consist of standalone clusters of three or more servers providing network storage exclusively—block storage, object storage, and file systems without compute allocation.
The most common use case involves large-scale object storage deployments. By combining high ratios of NVMe cache disks with high-capacity spinning media, storage clusters deliver excellent performance with low per-gigabyte costs. This architecture proves particularly effective for backup repositories, media archives, and data lakes requiring massive capacity at reasonable costs.
Converged Clusters: Advanced Scaling for Specific Workloads
 Converged clusters represent standalone clusters of three or more servers providing both compute and network storage. These clusters serve workloads with specific needs different from your Cloud Core but following predictable compute-to-storage ratios.
Converged clusters represent standalone clusters of three or more servers providing both compute and network storage. These clusters serve workloads with specific needs different from your Cloud Core but following predictable compute-to-storage ratios.
Large clouds often deploy converged clusters for efficiency at scale. Rather than expanding the Cloud Core indefinitely, you can create purpose-built clusters optimized for specific workload characteristics. For example, a cluster optimized for machine learning inference might have different CPU-to-storage ratios than your general-purpose Cloud Core.
This advanced option typically involves assistance from OpenMetal’s team to ensure proper configuration and integration with your existing infrastructure.
Bare Metal Servers: Maximum Control and Flexibility
 Bare metal servers operate as standalone nodes that either join your cloud to share VLANs or operate in separate networks. Each deployment includes several private VLANs and IPMI access, enabling advanced clustering scenarios.
Bare metal servers operate as standalone nodes that either join your cloud to share VLANs or operate in separate networks. Each deployment includes several private VLANs and IPMI access, enabling advanced clustering scenarios.
This option suits workloads requiring direct hardware access—Hadoop clusters, custom Ceph deployments, ClickHouse installations, or CloudStack implementations. Bare metal infrastructure gives you complete control over the operating system, networking, and storage configuration without virtualization overhead.
GPU Acceleration for AI and ML Workloads
As artificial intelligence and machine learning workloads become production requirements rather than experimental projects, GPU infrastructure becomes necessary. OpenMetal offers dedicated NVIDIA A100 and H100 GPUs without virtualization, throttling, or noisy neighbors affecting performance.
Configurations range from single GPUs to 8x GPU setups with flexible CPU/GPU pairings, RAM, and storage options. Support for MIG (Multi-Instance GPU), SR-IOV passthrough, and time-sliced sharing enables multi-tenancy when appropriate for your workloads.
Common use cases include LLM training and fine-tuning, AI inference serving, generative AI applications, and compliance-sensitive workloads requiring data sovereignty. GPU servers are currently available in US East and West regions, with expansion to Europe and Asia coming soon.
GPU configurations require monthly billing with custom orders requiring a one-year minimum commitment. This ensures serious production deployments rather than temporary experimentation.
Architectural Flexibility: Multi-Region and Hierarchical Deployments
Cloud Cores can control other Cloud Cores and expansion servers beneath them in a hierarchical structure. This capability enables large-scale deployments that span multiple data centers while maintaining centralized management.
For organizations requiring geographic distribution, OpenMetal offers globally merged clouds spanning continents through the large deployment process. This architecture addresses data sovereignty requirements, reduces latency for distributed users, and provides geographic redundancy for business continuity.
The Economics of Private Cloud Scaling
One of the most significant differences between private and public cloud scaling involves cost structures. Public cloud services charge based on resource consumption, meaning every addition increases your monthly bill. This creates a dilemma during migration: you’re paying for both your existing infrastructure and your new cloud simultaneously.
OpenMetal’s ramp pricing eliminates duplicate costs during migration. Rather than maintaining parallel environments, you can transition workloads gradually without accumulating double charges. Engineer-assisted onboarding helps ensure smooth transitions without unexpected complications.
Private cloud scaling strategy differs fundamentally from public cloud approaches. Fixed billing allows you to scale workloads large initially without incremental costs, then scale back after monitoring actual usage patterns. This reverses the typical public cloud trajectory where you start small and watch costs escalate as you add resources.
Organizations typically achieve 50% or greater cost reduction within six months compared to public cloud spending. The savings come not just from lower per-unit costs but from the ability to right-size infrastructure based on actual rather than anticipated usage patterns.
Capacity Planning: Avoiding Common Pitfalls
Effective capacity planning requires understanding both technical constraints and workload characteristics. Many teams either overcommit resources based on peak theoretical demand or underestimate requirements and face performance problems.
The distinction between horizontal and vertical scaling becomes particularly relevant during production deployment. Horizontal scaling—adding more nodes—provides better redundancy and failure tolerance. Vertical scaling—upgrading individual nodes—offers simplicity but creates single points of failure.
OpenMetal’s architecture naturally supports horizontal scaling through the quick addition of converged nodes, compute nodes, or storage clusters. This approach maintains high availability while expanding capacity incrementally based on actual demand.
Maintaining Infrastructure Consistency at Scale
As SaaS companies scale, infrastructure consistency becomes increasingly challenging. Standardized deployment processes, configuration management, and monitoring become necessary for operational efficiency.
OpenMetal’s approach to infrastructure consistency starts with standardized hardware configurations and extends through automated deployment processes. The same Kolla-Ansible and Ceph-Ansible tools that deploy your initial Cloud Core work identically for expansion resources, maintaining consistency across your entire infrastructure.
This consistency proves particularly valuable when troubleshooting production issues. Rather than maintaining tribal knowledge about which servers have which configurations, your entire infrastructure follows documented, repeatable patterns.
Scaling Strategies: MicroVMs and Workload Optimization
MicroVM architectures represent another approach to efficient scaling. By creating lightweight virtual machines with minimal overhead, you can pack more workloads onto existing infrastructure while maintaining isolation and security.
This strategy works particularly well for containerized workloads and microservices architectures. Rather than provisioning full VMs with complete operating systems for each service, microVMs provide just enough infrastructure to run your application with minimal resource overhead.
The decision between scaling out and scaling up depends on your specific workload characteristics. Stateless applications typically scale better horizontally, while stateful applications may benefit from vertical scaling approaches.
Operational Maturity: From PoC to Production-Ready
Production-ready OpenStack deployment involves more than simply installing software. It requires monitoring infrastructure, backup procedures, disaster recovery planning, and security hardening.
Documentation from your PoC phase becomes invaluable during production deployment. Even though a PoC isn’t production code, the technical decisions, initial test cases, and setup instructions provide critical context for production implementation.
Production operations demand comprehensive testing strategies including unit tests, integration tests, and end-to-end validation. Automated testing ensures stability and reliability as your infrastructure evolves and expands.
Security considerations that might be overlooked during PoC become critical in production. Data encryption, access controls, input validation, and regular security audits protect against potential threats. OpenMetal’s infrastructure includes IPMI access for secure out-of-band management and private VLANs for network isolation.
The Path Forward: Continuous Improvement
Moving from proof of concept to production isn’t a one-time transition. It’s an ongoing process of monitoring, optimization, and refinement based on actual workload behavior.
OpenMetal’s fixed-cost model enables experimentation and optimization without financial penalties. You can test different architectures, evaluate performance characteristics, and adjust configurations based on real data rather than theoretical projections.
Production cloud platforms should evolve with your business requirements. What starts as a three-node Cloud Core can expand into a globally distributed infrastructure serving millions of users or contract during slower periods without affecting functionality.
The key differentiator lies in control. Rather than accepting whatever your public cloud provider offers, you design infrastructure matching your specific requirements. This control extends from hardware selection through network architecture to storage configuration and compute allocation.
Conclusion
 Scaling from proof of concept to production involves technical challenges, architectural decisions, and operational maturity. OpenMetal’s approach simplifies this transition by providing production-grade infrastructure from day one, eliminating the rebuild phase that typically occurs between PoC and production.
Scaling from proof of concept to production involves technical challenges, architectural decisions, and operational maturity. OpenMetal’s approach simplifies this transition by providing production-grade infrastructure from day one, eliminating the rebuild phase that typically occurs between PoC and production.
Whether you’re expanding with converged nodes for balanced growth, adding compute nodes for high-performance workloads, deploying storage clusters for capacity, or integrating GPU servers for AI workloads, OpenMetal’s flexible architecture adapts to your requirements.
The economics of private cloud scaling—fixed costs, ramp pricing, and predictable growth—enable strategic planning that public cloud variable pricing makes difficult. Organizations achieve significant cost savings while gaining operational control and infrastructure flexibility.
Your journey from proof of concept to production doesn’t require accepting compromises between validation and scalability. Start testing with OpenMetal’s trial programs and discover how production-ready infrastructure accelerates your path from concept to reality.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog