


































In this article
Most DR architectures land on a single provider because it’s the path of least resistance. That convenience has a real cost: you’re using the same vendor for both production and recovery, which means a provider-wide outage, a pricing change, or a new compliance requirement can put both at risk simultaneously. This article covers the case for hybrid DR, how to design it in both directions, and where the economics actually land.
Disaster recovery planning tends to follow the production environment. If your production workloads are on AWS, the DR environment often ends up on AWS too. It’s faster to configure, your team already knows the tooling, and the replication tools are built for it. The same logic applies to Azure, and to organizations who have moved production to a private cloud.
This is understandable but worth re-thinking. The purpose of a DR environment is to be available when your production environment isn’t. If both environments share the same underlying infrastructure provider, you haven’t fully addressed the scenarios where that provider has a problem. AWS has experienced multi-region outages. Azure has had incidents that affected multiple availability zones simultaneously. These events are rare, but they’re the exact scenarios DR exists to cover.
Beyond outage risk, there’s a growing compliance dimension. Auditors reviewing SOC 2, HIPAA, and DORA compliance are increasingly asking specific questions about vendor concentration in DR architecture. Keeping production and recovery with the same provider is an answer that’s harder to defend than it used to be.
Hybrid DR addresses both problems. Running your recovery environment on a different provider from your production environment means a provider-specific incident doesn’t compromise both simultaneously. It also gives you more control over where your recovery data lives, which matters for data sovereignty requirements.
The Two Architectures Worth Considering
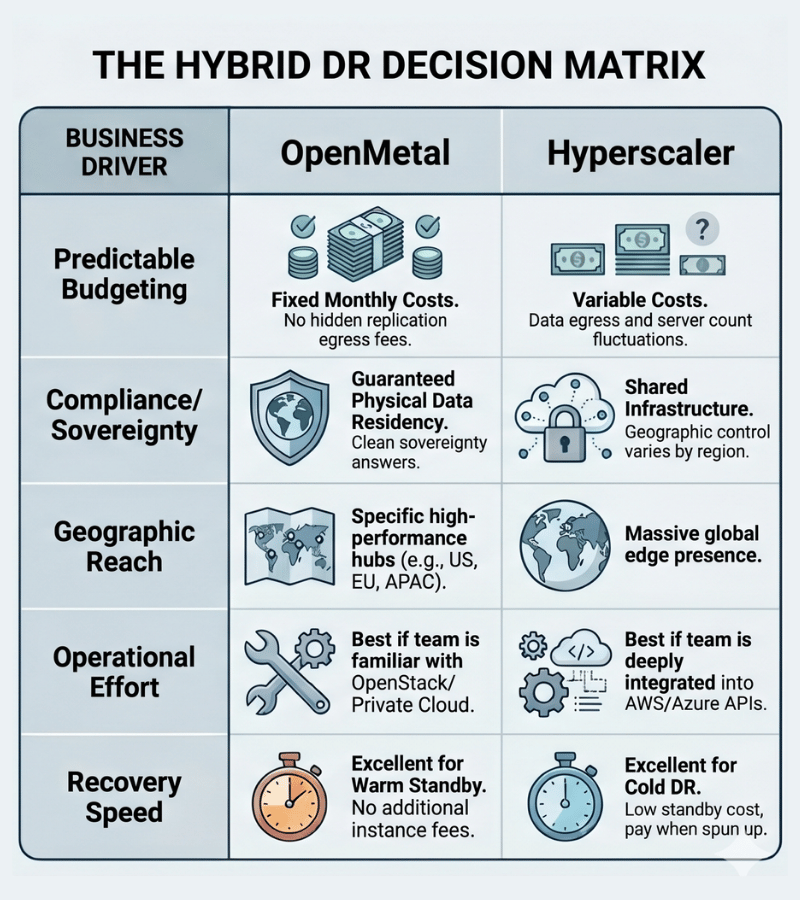
Hybrid DR between OpenMetal and a hyperscaler works in both directions, and the right direction depends on where your production workloads currently live.
OpenMetal as Primary, AWS or Azure as DR
This architecture suits organizations that have already moved production to OpenMetal’s hosted private cloud for cost or control reasons, and want to use a hyperscaler’s broad geographic footprint and elastic capacity as the recovery target.
The main advantage is flexibility on the DR side. AWS and Azure have recovery regions everywhere, and their elastic compute means you pay for standby capacity only when you need it. A cold DR environment on a hyperscaler can be genuinely inexpensive if your RTO tolerance allows for spin-up time. Warm standby costs more, but still benefits from elastic scaling during an actual recovery event when you need to handle more load than normal.
The egress consideration with this direction runs the other way from what you might expect. Sending data into AWS or Azure is free, as both providers charge nothing for ingress. The cost exposure comes when data needs to leave the hyperscaler, whether for failback to OpenMetal after a recovery event, DR drills that require pulling data back, or any ongoing reads from the recovery environment. At AWS’s standard rates of $0.09/GB for outbound internet transfer, a failback of even a few terabytes generates a meaningful bill. For organizations with large data volumes or frequent DR testing, that outbound cost needs to be factored into the DR budget from the start.
Terraform manages infrastructure-as-code consistently across both environments. OpenStack APIs on the OpenMetal side and AWS/Azure APIs on the recovery side use different providers in Terraform, but the workflow is familiar and the state can be managed centrally.
AWS or Azure as Primary, OpenMetal as DR
This is the more immediately applicable architecture for organizations still running production on a hyperscaler who are evaluating how to reduce DR costs and improve provider diversity at the same time.
The economics here are interesting. Hyperscaler DR billing has three layers that compound against each other: replication agent fees, standby compute costs for provisioned recovery instances, and egress charges every time replication traffic crosses availability zones or regions. AWS Elastic Disaster Recovery runs approximately $20 per server per month just for the replication agent, before any compute or storage costs. For organizations protecting 50 or 100 servers, that baseline cost adds up before a single byte of data moves.
OpenMetal’s fixed-cost pricing model changes the math. Your DR environment costs the same whether it’s running at zero utilization or handling a full failover. There are no per-server replication agent fees, no per-GB egress charges on replication traffic between your servers, and no surprise costs when you run a DR drill. You know what the DR environment costs every month regardless of how you use it.
For compliance-driven organizations, this direction also offers a cleaner answer to data sovereignty questions. If your production environment is on AWS US-East and your DR requirement is that recovery data stays within the EU, an OpenMetal environment in Amsterdam provides a dedicated, fixed-cost recovery location with clear physical data residency. The same logic applies to APAC requirements with OpenMetal’s Singapore location.
How to Decide Which Direction Fits
The architecture decision comes down to a few practical questions:
Where does your production data currently live? If you’re fully invested in a hyperscaler’s tooling and APIs, using that as primary and OpenMetal as DR is the lower-friction path. Migrating production is a bigger project than adding a recovery environment.
What are your RPO and RTO requirements? Cold DR on either provider is cheaper but has longer recovery times. Warm standby costs more but gets you back online faster. The right tier depends on how much downtime each workload class can actually tolerate, which is a business question more than a technical one.
Do you have data sovereignty requirements? If regulations specify where recovery data must physically reside, the location flexibility of OpenMetal’s four data centers in Ashburn, Los Angeles, Amsterdam, and Singapore may determine the architecture more than cost does.
What does your team actually know how to operate? A DR environment your team can’t execute a recovery from under pressure isn’t a DR environment. If your engineers know AWS well, keeping DR on a familiar platform has real operational value. If your team already runs OpenStack, an OpenMetal DR environment is the lower-risk option.
What’s the total cost including replication traffic? Run the numbers for your specific data volume and replication frequency before committing. The replication egress costs between providers are real and often underestimated in initial DR budgets.
What Hyperscaler DR Actually Costs
It’s worth being specific here because the numbers are frequently underestimated.
AWS Elastic Disaster Recovery charges approximately $20 per protected server per month for the replication agent. An organization protecting 50 servers pays $1,000 per month before touching compute, storage, or data transfer. Standby instances running in a warm configuration add EC2 costs on top of that. Replication traffic between AWS regions is charged at inter-region data transfer rates, which run $0.02 per GB or higher depending on the regions involved. For an organization replicating 10TB per month across regions, that’s $200 or more in data transfer fees monthly, recurring.
Azure Site Recovery pricing follows a similar structure: per-instance fees plus storage and replication traffic costs, with pricing that varies by region pair.
Against that baseline, an OpenMetal Cloud Core sized for DR starts at a fixed monthly rate regardless of how many VMs you protect within it, with no per-server replication agent fees and no per-GB charges on intra-cluster traffic. For organizations protecting larger server counts, the fixed-cost model becomes more favorable as the scale grows.
The Tooling That Makes Hybrid DR Work
A hybrid DR architecture needs a consistent layer for infrastructure-as-code, a reliable replication mechanism, and secure connectivity between environments.
Infrastructure as Code
Terraform is the practical choice for managing both sides of a hybrid DR architecture. The OpenStack Terraform provider handles OpenMetal environments, and AWS and Azure both have mature Terraform providers. Managing both environments from a single Terraform codebase means your DR infrastructure definitions stay in version control alongside your production definitions, and recovery procedures can be tested and documented as code rather than runbooks.
Replication
Several tools handle cross-provider replication well for this use case. Hystax Acura supports agentless replication between OpenStack and public cloud targets with continuous data protection and low RPOs. ZConverter handles cross-platform VM replication including OpenStack-to-AWS and OpenStack-to-Azure scenarios. For storage-level replication between OpenMetal’s Ceph-backed storage and cloud object storage, Rclone and similar tools handle synchronization reliably. The right tool depends on your RTO requirements and whether you need application-consistent snapshots or block-level replication.
Connectivity
Replication traffic between your production environment and DR environment should not travel over the public internet unencrypted. Site-to-site VPN is the baseline minimum. OpenMetal supports VPN-as-a-Service through OpenStack Neutron, which handles the private cloud side of the connection without additional tooling. For organizations with high replication volumes or latency-sensitive requirements, a dedicated private connection is worth evaluating.
Runbooks and DR Testing
The tooling only matters if the team can execute a recovery. Document the failover procedure explicitly, test it on a schedule, and make sure more than one person knows how to run it. DR environments that haven’t been tested under realistic conditions are optimistic documentation, not actual recovery capability.
When Hybrid DR Is Probably More Than You Need
Not every organization needs the complexity of a cross-provider DR architecture.
If your workloads are non-critical and your business can tolerate hours or days of downtime in a genuine disaster, a simple backup strategy with cold recovery on either provider is sufficient and significantly cheaper to operate.
If you’re a small team without dedicated infrastructure engineering capacity, managing two provider relationships and the tooling to connect them adds operational overhead that may not be justified by the risk reduction.
If you’re early-stage and your primary concern is cost rather than resilience, a single-provider DR environment in a different region is a reasonable starting point. The vendor concentration risk is real, but it’s the lower-priority problem for organizations that don’t yet have the budget or staffing to address it properly.
Hybrid DR is the right architecture when vendor concentration is a genuine risk you’ve identified, when compliance requirements are driving provider diversity, or when the economics of fixed-cost DR clearly beat the alternative at your scale. Getting to that conclusion honestly is more useful than defaulting to complexity for its own sake.
A Starting Point That Doesn’t Require a Full Commitment
One practical approach for organizations evaluating this architecture: start with OpenMetal as a DR environment for a single workload tier before committing to a full hybrid strategy.
A single OpenMetal Cloud Core running as a warm DR target for your most critical workloads gives you real experience with the hybrid architecture, a concrete cost comparison against your current DR spend, and a working proof of concept before you expand to cover your full environment. If the architecture works and the economics hold up, you expand it. If it doesn’t fit, you’ve learned that without a large commitment.
The DR use case is also one of the lower-risk entry points into private cloud infrastructure generally. Your production environment stays where it is. You’re adding a recovery layer, not migrating anything. That reduces the project risk considerably while still delivering meaningful improvement to your resilience posture.
Evaluating your DR options? See how OpenMetal’s hosted private cloud fits into a hybrid DR architecture, or use the Cloud Deployment Calculator to understand what a fixed-cost DR environment would actually cost for your scale.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog