


































In this article
- Why Modernize? The Business and Technical Advantages
- Building the Ideal Foundation for Your Modern Data Warehouse with OpenMetal
- The Phased Migration Approach and Roadmap
- Navigating Potential Challenges in Your Migration Journey
- Wrapping Up – Modernizing Your Data Warehouse with OpenMetal
- Get Started on OpenMetal for Your Big Data Project
For many years, traditional data warehouses—systems like Oracle, SQL Server, and Teradata—were the foundation of business intelligence. They were big projects, often costing a lot, and for a long time, they did what they were supposed to do: give companies a single view of their data, helping them see a “single view of their world”. These platforms helped businesses make decisions based on data, which was a big step forward at the time.
However, technology has changed a lot. The same systems that once helped organizations are now, in many cases, holding them back. Data Architects, CIOs, Database Administrators, and the like are all too familiar with the growing problems.
 The biggest issue is the very high costs for licenses and upkeep. Licenses for proprietary software, like Oracle’s per-processor or Named User Plus (NUP) models for its Enterprise Edition and related options such as Multitenant, Real Application Clusters (RAC), Advanced Compression, and Diagnostics Pack, can use up large parts of IT budgets. Similarly, SQL Server’s different editions have limits and costs that can slow down growth. These systems, which were first mainly available to large companies because of their expense, still require a lot of money for ongoing maintenance and support.
The biggest issue is the very high costs for licenses and upkeep. Licenses for proprietary software, like Oracle’s per-processor or Named User Plus (NUP) models for its Enterprise Edition and related options such as Multitenant, Real Application Clusters (RAC), Advanced Compression, and Diagnostics Pack, can use up large parts of IT budgets. Similarly, SQL Server’s different editions have limits and costs that can slow down growth. These systems, which were first mainly available to large companies because of their expense, still require a lot of money for ongoing maintenance and support.
Besides cost, limits on how much they can grow and slower performance are common problems. Legacy data warehouses, often with many additions and changes over the years, tend to get slower and more complex with each passing year. SQL Server Standard, Web, and Express editions, for example, have strict limits on processing power, memory use, and database size, which stop organizations from expanding their ability to analyze data. Even powerful systems like Teradata, though built for large-scale analysis, can become complex and hard-to-manage environments that are difficult to scale well.
The problem of rising costs in older data warehouses often sneaks up on companies. Initial investments are usually followed by required, and often expensive, maintenance contracts. As data amounts grow and the need for analysis increases, organizations find they need advanced features – such as Oracle’s special packs for multitenancy, high availability, compression, or performance diagnostics – and each of these has its own high price. Adding to this is the need for highly specialized staff to manage the growing complexity of these aging systems. This creates a situation where organizations are spending more money just to keep a system running that offers less and less in terms of performance and flexibility. This isn’t a sudden financial hit, but a slow increase, making the true total cost of ownership (TCO) a heavy load that might not be fully realized until it’s too much to handle. At this point, many organizations also realize that building a reliable data ETL pipeline requires modern infrastructure capable of scaling with data growth without driving exponential cost increases.
Also, being tied to one vendor, or lock-in, creates big strategic risks. The complex details of Oracle’s Unlimited License Agreements (ULAs) or Teradata’s unique SQL extensions and internal parts can make moving to other solutions very hard and expensive. This effectively ties an organization to one vendor’s plans and prices.
Adding to these issues is the difficulty these older systems have in working with modern data types and analytics. Traditional data warehouses were mostly built for structured data. Their fixed nature makes it hard to efficiently handle today’s varied data, which includes huge amounts of unstructured and semi-structured data. Connecting with modern AI/ML pipelines or supporting real-time analytics, which are vital for today’s business intelligence, often requires clunky fixes or just doesn’t work well. The schema-on-write models, which were perfect for the predictable, structured data of the past, find it hard to offer the schema-on-read flexibility that is often needed for data lakes and advanced AI/ML work. This inflexibility in design, like the difficulty in managing old “junk data” or forgotten tables in a mature Teradata system, becomes a major roadblock, stopping organizations from fully using new, data-driven opportunities.
In this situation, updating the data warehouse is a necessary strategic move. Using open source database solutions, hosted on strong and cost-friendly platforms like OpenMetal’s bare metal cloud, offers a rewarding way forward. This approach gives a chance to get better performance, more agility, and a much lower TCO. This changes the data warehouse from a costly operational weight into a tool for innovation.
Why Modernize? The Business and Technical Advantages
Deciding to move away from established legacy data warehouses is a big step, but the mix of business and technical benefits offered by modernization, especially with open source solutions on platforms like OpenMetal, makes a strong case for change. These benefits address the main frustrations with older systems and open up new possibilities for data-driven organizations.
Enhanced Performance for Analytics and Reporting
A big reason for modernizing is to get insights faster. Open source databases, especially those built for analytical tasks, can really improve performance. For example, ClickHouse, with its columnar storage and vectorized query execution, is known for processing huge datasets very quickly. A well-set-up PostgreSQL system can also perform strongly for many data warehousing tasks.
The choice of infrastructure is important here. With dedicated resources, databases run at their best. This can lead to big real-world improvements, like one fintech company’s 10-20x faster query responses seen when moving from BigQuery to ClickHouse, or Core Digital Media’s 30% improvement in BI report generation when moving from Teradata to Snowflake. Such performance boosts mean quicker access to important information, allowing for faster and better-informed decisions. OpenMetal’s bare metal cloud gives this direct hardware access, removing any potential hypervisor slowdown.
Outstanding Scalability and Flexibility
Business needs change, and data infrastructure must change with them. OpenMetal’s platform, with on-demand private clouds and the ability to easily add more bare metal resources, combined with the natural scalability of open source solutions like Ceph for storage, allows for flexible scaling of both computing and storage capacity.
Ceph’s design, for example, is made to scale to exabyte levels, handling huge amounts of data. This is very different from the strict scaling paths or hard limits on cores, sockets, and memory found in older systems or specific versions of proprietary databases like SQL Server Standard. This new agility ensures the data warehouse can grow with the business without needing huge upfront investments or suffering from poor performance.
Getting Out of Vendor Lock-In
One of the most strategically important reasons to modernize is to get free from vendor lock-in. Using open standards, like the strong SQL compliance in PostgreSQL and MariaDB, and using open source technologies like OpenStack (for cloud management) and Ceph (for storage) on the OpenMetal platform, gives organizations more control and freedom. This approach reduces the risks of depending on a single vendor’s product plans, pricing, and proprietary features, which can be very restrictive with complex agreements like Oracle’s ULAs. Strategic agility improves when design choices are not controlled by a single vendor.
Significant Cost Reduction (Lower TCO)
The financial weight of legacy data warehouses is a major issue. Modernization offers a lot of relief. By moving to open source databases, organizations can get rid of the high costs of proprietary software licenses from vendors like Oracle (including its Enterprise Edition and many add-on packs) and SQL Server (especially its more expensive editions). Open source software, by its nature, has no licensing fees.
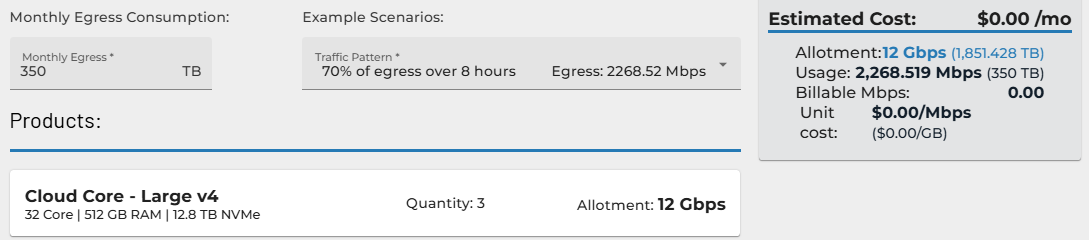
OpenMetal’s pricing model increases these savings. Our on-demand private clouds have fixed, predictable costs, which is very different from the often surprising bills from public cloud providers. A key difference is our large bandwidth and egress allowance; for instance, an OpenMetal Large V4 Cloud Core includes 4Gbps per server, which is about 1,840TB of egress, at no extra cost.
Our 95th percentile bandwidth billing model is designed to eliminate the unpredictability and financial penalties commonly associated with traditional cloud data egress pricing. Rather than charging for every gigabyte of outbound traffic, OpenMetal measures bandwidth usage over time and discards the top 5% of usage spikes—meaning you’re billed only for your typical usage patterns, not your occasional peaks.
Similar egress on major public clouds could cost thousands or tens of thousands of dollars. In fact, many of our users have reported overall cloud cost savings of up to 60% after moving to OpenMetal.
We’re transparent with all our pricing; you can use our egress calculator to see egress allowances for our various hardware tiers and calculate costs if those allowances are exceeded (which is rare for most of our customers).
Additionally, simplifying and modernizing your data warehouse setup can potentially reduce the need for highly specialized and expensive DBA staff, whose skills were often vital for managing the complexities of older, more complex systems. The performance benefits of running optimized open source databases on bare metal infrastructure also directly help save money, creating a powerful combination. When queries and ETL processes run faster, they use fewer CPU cycles and finish quicker. This efficiency means that either smaller or fewer servers can handle the current workload, or the current hardware can support more work or more users at the same time.
Both results lead to lower operational costs for computing resources. This combined benefit goes beyond just license savings and is strengthened by OpenMetal’s fixed hardware budget model, allowing organizations to maximize their processing power without worrying about runaway variable costs.
Future-Proofing Your Data Strategy
A modernized data warehouse must help, not hinder, future data projects. Open architectures make it easier to connect with the constantly changing world of modern data tools, AI/ML pipelines, and real-time analytics. Open source databases often have more or better connectors and strong community support for new technologies. ClickHouse, for example, is excellent for real-time analytical situations. The general trend towards bare metal cloud solutions is also driven by the growing needs of High-Performance Computing (HPC) for AI/ML model training and real-time data processing, putting OpenMetal users at the front of this change.
While cutting costs is an immediate and clear benefit of moving to open source, the long-term strategic value often comes from becoming an innovation booster. Open source solutions usually have active communities, like those for PostgreSQL and ClickHouse, which quickly develop new features, performance improvements, and integrations. Organizations get these advancements much faster than if they relied on a proprietary vendor’s development and release schedules.
The ability to access and, if needed, change source code gives flexibility for customization and connection with new technologies, like specialized AI/ML frameworks. This built-in adaptability makes the data platform more resilient and ready for the future, allowing quicker adoption of new analytical methods and a lasting competitive advantage.
Strengthened Data Governance and Security
In a time of increasing data rules and cyber threats, strong data governance and security are essential. OpenMetal’s on-demand private clouds offer a physically and logically separate environment for your data warehouse. Providing root-level access to the hardware and the OpenStack control plane lets organizations set up custom security configurations, detailed access controls, full auditing systems, and special tools to meet strict compliance rules like GDPR, HIPAA, or CCPA, often complemented by enterprise access control software to manage permissions and strengthen overall security governance. Also, OpenStack’s “Projects” feature can be used to create VPC-like network separation for better security.
OpenMetal provides basic security measures, including DDoS protection for network traffic and 24/7 physical security at our data centers. The idea of data control and ownership is a key benefit of private cloud setups; for instance, if using an open source monitoring solution like Monasca, all monitoring data stays within the organization’s private cloud infrastructure.
For data warehouses that handle large amounts of data that need to be shared—whether for feeding external analytics platforms, working with partners, or enabling large-scale BI use—data egress costs on major public cloud platforms can quickly become too expensive. OpenMetal’s pricing model, which includes a very large egress allowance with its hardware and uses 95th percentile billing, completely changes this financial picture. This makes it financially possible to run data-heavy warehouse workloads that involve a lot of data output, a situation that might be too expensive on other platforms. This is a critical difference for organizations whose data strategies involve extensive data movement and sharing.
To summarize the transformation, consider the shift from legacy pain points to modern gains:
Pain Point | Legacy System Reality | OpenMetal + Open Source Advantage |
|---|---|---|
| High License Costs | Expensive proprietary licenses (Oracle, SQL Server) and mandatory add-ons for essential features. | No software licensing fees for open source databases; OpenMetal’s fixed, predictable hardware pricing. |
| Poor Scalability | Monolithic architectures, hard limits on resources (e.g., SQL Server Standard ), slow to adapt to growth. | Elastic scaling of compute and storage with OpenMetal’s on-demand private clouds and Ceph; bare metal for raw power. |
| Vendor Lock-In | Dependence on proprietary SQL, complex licensing (e.g., Oracle ULA ), limited flexibility. | Freedom with open standards (SQL), open source technologies (OpenStack, Ceph), and choice of open source databases. |
| Slow Performance | Aging systems become slower, hypervisor overhead in virtualized environments, contention for resources. | Superior query speeds on bare metal (no hypervisor tax), optimized open source databases (e.g., ClickHouse), dedicated resources. |
| Security/Control Concerns | Limited control in multi-tenant public clouds, opaque security practices. | Private cloud isolation, root-level access for custom security/auditing, data sovereignty, DDoS protection. |
| Limited Modern Integration | Difficulty integrating with new data types (unstructured), AI/ML pipelines, real-time analytics. | Seamless integration with modern data tools and AI/ML due to open architecture and vibrant open source ecosystems. |
| Unpredictable Egress Costs | Significant, often escalating charges for data transfer out of major public clouds. | Very generous included egress with hardware; 95th percentile bandwidth billing; minimal, predictable costs beyond allowance, enabling data-intensive workloads. |
Building the Ideal Foundation for Your Modern Data Warehouse with OpenMetal
Choosing the right infrastructure is key for a successful data warehouse modernization project. OpenMetal stands out as an ideal foundation, offering a unique mix of performance, control, and cost-effectiveness that fits the demanding needs of modern data warehousing. OpenMetal specializes in providing on-demand private clouds and bare metal servers. We focus on empowering users through open source technologies like OpenStack for strong cloud management and Ceph for resilient, scalable storage. A key feature is that our hosted private clouds are “Day 2 ready,” meaning they can be set up and working in as little as 45 seconds, offering amazing agility for private infrastructure.
The real value of OpenMetal for data warehousing is clear when our main features are matched to the needs of these systems:
Granular Control Over the Environment
Unlike many managed public cloud data warehouse services that hide underlying details, OpenMetal provides full root access to both the bare metal hardware and the OpenStack control plane. This lets Data Architects and DBAs deeply customize the operating system, fine-tune database settings, and optimize network configurations specifically for their data warehouse workloads. We host the hardware, but it is 100% your own cloud! This level of control is vital for getting maximum performance and ensuring the environment perfectly fits application needs.
The customization and flexibility our solutions allow is something many of our customers find especially valuable when it comes to their big data needs. As you can see demonstrated in the architecture diagram below, one of our cybersecurity customers has mixed-and-matched a bare metal ClickHouse cluster with a Ceph object storage cluster along with an OpenStack-powered private cloud on our Small Cloud Core. They’ve been able to build out the perfect system for their unique needs to maximize resource optimization and cost-effectiveness for their pipeline.
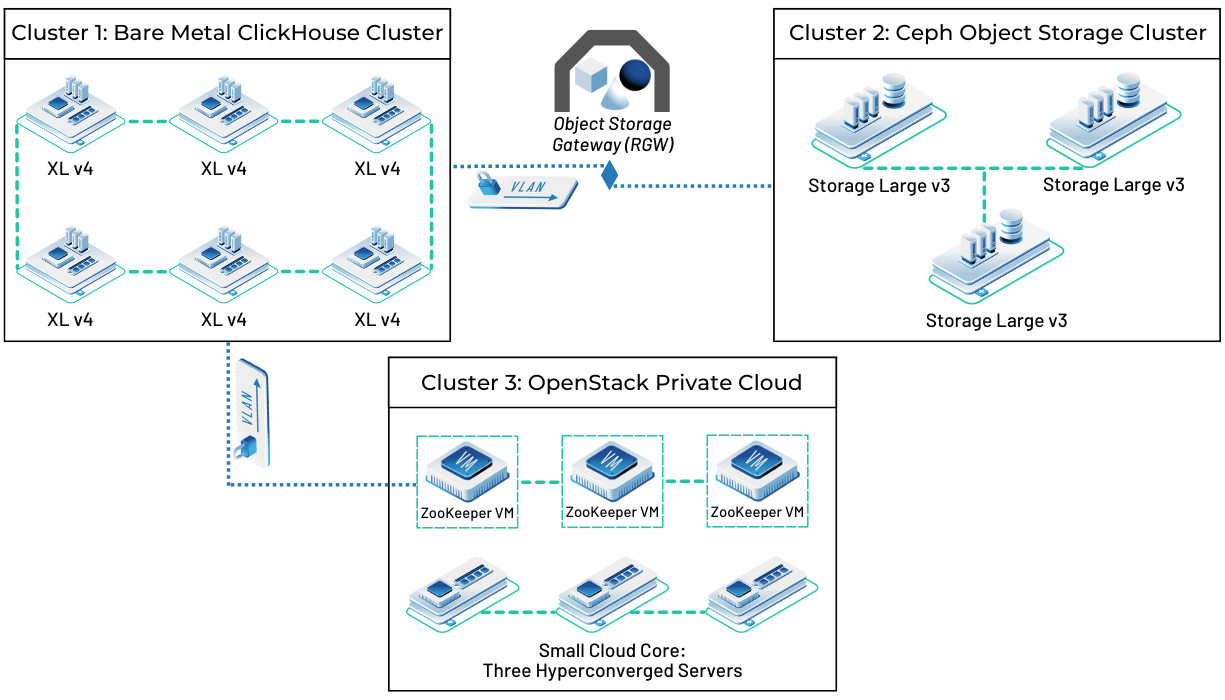
Inherent Support for Very Large Datasets
Modern data warehouses often manage terabytes, if not petabytes, of data. OpenMetal’s infrastructure is built for this size. The Ceph distributed storage system is designed for exabyte-level scalability. It provides strong and resilient block and object storage solutions ideal for holding the large and growing datasets typical of enterprise data warehouses.
We offer various storage server setups, including options with high-capacity HDDs for bulk storage, smartly sped up with NVMe drives for metadata and caching, ensuring both capacity and performance.
Uncompromised I/O Performance
Data warehouses depend heavily on I/O performance. OpenMetal’s bare metal servers provide direct, clear access to hardware resources, including high-performance NVMe SSDs. This ensures very low latency and maximum speed for intense database operations like complex queries, large data loads, sorts, and joins. Additionally, OpenMetal’s Ceph storage design allows for creating high-performance storage pools backed by NVMe drives, specifically for workloads that need the most speed.
Robust and Versatile Storage with Ceph
Ceph is not only super scalable, it’s very flexible. It offers:
- Unified Storage: The ability to provide block storage (for VM disks), object storage (S3-compatible, great for data lakes or staging areas), and even file system storage (CephFS) from a single, centrally managed cluster simplifies infrastructure.
- High Availability: Data safety and availability are ensured through methods like data replication (usually keeping three copies of data across different nodes/drives) or erasure coding for more storage-efficient fault tolerance.
- Multiple Performance Tiers: As mentioned, Ceph allows for creating different storage pools for different performance and cost needs—for example, NVMe-backed pools for hot, frequently accessed data and VM operating systems, and HDD-backed pools for less critical bulk data or colder archives.
You can see a live demonstration of Ceph’s inner workings in this video from our Director of Cloud Systems Architecture for a better understanding of this powerful open source storage platform:
Predictable Costs for Resource-Intensive Workloads
Data warehousing can use a lot of resources. OpenMetal’s fixed cost model for our private cloud hardware, along with our generous and clear egress pricing policy, brings much-needed predictability to budgeting for these demanding workloads. This is very different from the variable, usage-based pricing of many public cloud services, where costs can rise unexpectedly.
A Mix of Performance, Speed, and Flexibility for the Modern Data Warehouse
OpenMetal’s method of providing on-demand private clouds built on bare metal effectively offers the “best of both worlds”. In the past, organizations chose dedicated on-site hardware for data warehouses to ensure top performance and control, but this often meant less agility and long buying times.
Public cloud data warehouse services, on the other hand, offer agility and on-demand setup but can hide crucial control, introduce performance issues due to multi-tenancy (the “noisy neighbor” effect), and lead to unpredictable costs, especially for data egress.
OpenMetal fills this gap by delivering the raw power, dedicated resources, and deep customization options of bare metal servers, set up with cloud-like speed and managed via the OpenStack cloud operating system, which provides automation and agility. This combination is uniquely suited for modernizing data warehouses, where both top performance and operational flexibility are essential.
To build on these capabilities even further, the flexibility of Ceph within the OpenMetal environment becomes a tool for creating advanced and cost-effective data warehouse designs. Data warehouses naturally deal with data that has different access frequencies and performance needs (hot, warm, cold). Ceph on OpenMetal lets administrators create separate storage pools using different types of drives (NVMe SSDs, HDDs) and set up different data protection methods (replication for performance, erasure coding for capacity efficiency).
The data warehouse can then be designed to intelligently place data on the most suitable tier—for example, active fact tables and frequently queried dimensions on high-speed NVMe-backed block storage, while historical or less accessed data might be on more economical HDD-backed object storage, possibly accessed via external table methods if supported by the chosen open source data warehouse software. This detailed control over storage tiering, managed by the user through OpenStack and Ceph, allows for a level of cost and performance optimization that is often less clear, more restrictive, or simply not available in fully managed public cloud DWH offerings.
The S3-compatible object storage provided by Ceph also smoothly supports data lake strategies, which are increasingly common parts of modern, complete data systems built around the data warehouse.
Here we can see how OpenMetal’s specific strengths directly match the needs of data warehouse modernization:
Data Warehouse Requirement | Corresponding OpenMetal Feature/Benefit |
|---|---|
| Extreme Query Performance | Bare metal servers with high-performance NVMe SSDs; Ceph storage pools configurable with NVMe for low-latency access; no hypervisor overhead ensuring direct hardware utilization. |
| Predictable & Lower Costs | Fixed monthly pricing for private cloud hardware; generous data egress allowances with minimal costs beyond that and 95th percentile bandwidth billing; no proprietary software licensing fees for OpenStack or Ceph. |
| Massive & Scalable Storage | Ceph distributed storage designed for petabyte-scale and beyond; options for high-capacity HDD storage servers accelerated by NVMe; elastic scalability of storage resources. |
| Full Environmental Control | Root-level access to bare metal servers and the OpenStack control plane; ability to customize OS, database parameters, networking, and security configurations to optimize for specific DWH workloads. |
| Data Security & Sovereignty | Dedicated private cloud architecture providing workload isolation; customizable security policies and auditing capabilities; data resides within the customer’s controlled environment. |
| Avoiding Vendor Lock-in | Built on open source technologies: OpenStack for cloud management, Ceph for storage; supports a wide range of open source databases, promoting interoperability and freedom of choice. |
| Agility & Fast Provisioning | On-demand private cloud deployment in as little as 45 seconds; automation capabilities through OpenStack APIs, compatible with tools like Terraform and Ansible. |
The Phased Migration Approach and Roadmap
Moving a legacy data warehouse is a big job. Trying a “big bang” approach, where the whole system is switched over at once, is very risky and likely to be an expensive failure, especially with deeply established and complex systems like Teradata. A phased migration strategy, however, is less risky, easier to manage, and offers quicker value by delivering benefits in stages and allowing for ongoing learning and adjustments throughout the process. This step-by-step journey turns a huge task into a series of achievable steps.
📃 Take This Info With You – Download our Data Warehouse Phased Migration Checklist (opens in Google Docs) >>
Phase 1: Assessment and Strategic Planning
This first phase is the base for the entire migration. It starts with a thorough check of the existing legacy data warehouse. This means carefully documenting current schemas, data amounts, data types, and all connections, including upstream data sources and downstream applications or reports. Important ETL/ELT processes must be listed, along with all user reports and dashboards. Existing security rules and, importantly, current operational problems should also be noted. A key task during this check is to find and mark any “junk data”—old tables, unused queries, or unneeded information—that should not be moved to the new system.
At the same time, it’s vital to set clear migration goals, define the project’s scope, and decide on measurable success metrics (KPIs). These KPIs should cover things like target query response times, ETL job completion times, desired cost cuts (e.g., a specific TCO target), improvements in data access, and user satisfaction levels.
A big decision in this phase is choosing the right open source database technologies and supporting tools. The choice of database should be based on specific workload types, existing data models, performance needs, and the skills of the internal team.
- PostgreSQL is a strong choice for general-purpose data warehousing due to its maturity, strong SQL compliance, wide range of features, and large community. It can handle various workloads and often serves as a reliable core for many analytical systems, including those with OLTP-like parts.
- ClickHouse should be considered for situations needing extreme OLAP performance and real-time analytics on very large datasets, especially if data can be denormalized to use its columnar strengths well.
- MySQL or MariaDB (especially MariaDB with its ColumnStore engine) might be options for specific data marts or less complex analytical needs, particularly if there is a lot of existing in-house expertise. However, their limits on parallel query execution and handling complex joins must be considered.
- It’s generally best to avoid solutions like Apache Druid for a complete data warehouse replacement, given its built-in limits with complex joins, real-time updates (beyond appends), and full SQL functionality. This makes it more suited for specific real-time append-only analytical uses.
Once the technology stack is tentatively chosen, the team must design the target architecture on OpenMetal. This involves planning server configurations (CPU, RAM, NVMe/HDD storage managed by Ceph), defining the network setup within the private cloud, and outlining the high availability (HA) and disaster recovery (DR) strategy. If migrating from another cloud provider like AWS, this stage would also involve mapping services (e.g., AWS Aurora to OpenStack Trove or self-managed databases on VMs, AWS S3 to Ceph RGW object storage).
Finally, a pilot project must be chosen. This should be a small, representative part of the data warehouse—perhaps a specific data mart, a set of critical business reports, or a distinct functional area—that is complex enough to be a meaningful test but not so critical or large as to cause too much risk if problems occur.
Phase 2: Pilot Migration and Proof of Concept (PoC)
The PoC phase is used to check the assumptions made during planning and to find any unexpected problems in a controlled way. It starts with setting up the OpenMetal environment. This means provisioning the on-demand private cloud, configuring the bare metal servers, and establishing the OpenStack and Ceph infrastructure according to the target architecture design. We generally design around a 30-day PoC and will help get your environment set up for you.
Next, the selected subset of data for the pilot is moved. This usually involves extracting data from the legacy system, making necessary transformations (which may include changing schemas and data types between the old and new databases), and loading it into the chosen open source database running on OpenMetal.
Existing ETL/ELT pipelines for the pilot data must then be copied or redesigned. This might involve changing current scripts or completely rebuilding these processes using modern open source ETL tools, custom Python scripts, or transformation tools like dbt.
Rigorous testing is the main part of the PoC. This includes:
- Data Validation: Carefully checking data integrity, accuracy, and completeness. Methods include comparing row counts, calculating checksums, and performing value-level comparisons between the source and target systems. Tools like Datafold can be very helpful in programmatically proving data is the same.
- Performance Benchmarking: Measuring key performance indicators such as query response times, report generation times, and ETL job run times. These results are compared against the legacy system’s performance and the KPIs defined in Phase 1.
- User Acceptance Testing (UAT): Involving key business users to check that the reports, dashboards, and overall functionality of the pilot system meet their needs and expectations.
The final step of the PoC is to refine the overall migration plan. All learnings, identified problems (both technical and process-related), and performance results are documented. Based on these findings, the main migration strategy, timelines, resource plans, and risk reduction plans are adjusted and improved.
The PoC is much more than a simple technical test; it acts as a small version of the entire migration, reducing risk not only in technology but also in human and process areas. Success in the PoC builds momentum and support from stakeholders. Any failures or setbacks are small, contained, and provide valuable lessons that help in later phases, preventing larger, more costly mistakes when the main part of the migration is happening.
Phase 3: Incremental Migration Sprints
With a tested approach and a refined plan from the PoC, the migration continues by tackling other data marts or functional areas of the data warehouse in iterative sprints. Each sprint focuses on a manageable piece of the overall DWH.
A critical best practice during this phase is running the legacy and new systems in parallel (coexistence strategy) for a set period. This parallel operation allows for ongoing, real-world checking and comparison between the two systems. It also provides an essential backup plan should any major issues appear in the newly migrated parts of the OpenMetal-hosted warehouse.
Throughout each sprint, data and performance must be continuously checked, repeating the data integrity checks and performance benchmarks established during the PoC.
At the same time, users must be trained on the new system. This involves providing full training to DBAs, data analysts, report developers, and business end-users on the new open source database(s), related querying tools, BI interfaces, and any new reporting features.
A well-done parallel run strategy does more than just reduce risk; it can empower the migration team to be more ambitious in their modernization efforts. Knowing that a functional legacy system is available as a backup reduces the immense pressure for a perfect initial switchover of each part. This confidence can allow the team to make more significant improvements in the new system such as major ETL redesigns or adopting a different, more specialized database like ClickHouse for certain high-performance analytical workloads rather than settling for a simple “lift and shift” if greater long-term benefits can be achieved.
Phase 4: Cutover and Decommissioning
Once all functional areas have been migrated, checked, and users are comfortable with the new system, the project moves towards the final switchover. This begins with a final data synchronization to ensure the new data warehouse on OpenMetal is completely up-to-date with the latest transactional data from source systems.
Following this, all users and applications are redirected to the new environment. This involves updating database connection strings in applications, reconfiguring BI and reporting tools, and ensuring all data feeds point to the OpenMetal-hosted data warehouse.
A thorough post-migration validation is then done across the entire system to confirm that all parts are working as expected and that business processes are running smoothly.
Once the new system has proven stable and fully operational for an agreed-upon period, the legacy system can be formally shut down. This is a critical step that involves archiving any necessary historical data from the old platform (if not already migrated), shutting down the legacy servers, and, crucially, ending expensive proprietary software licenses and support contracts.
Shutting down the legacy system is not just a technical cleanup; it’s a vital financial and operational milestone. It’s at this point that the full range of cost savings—from eliminated software licenses, reduced maintenance fees, and retired specialized hardware—is truly achieved. Operationally, removing the “crutch” of the old system forces the organization to fully commit to and rely on the new, modernized platform. This forced change drives user adoption, speeds up proficiency with the new tools and capabilities, and prevents “shadow IT” operations on the old, unsupported system. It also frees up valuable IT resources that were previously used for the upkeep of the outdated infrastructure.
Phase 5: Optimization and Ongoing Management
Data warehouse modernization is not a one-time project that ends at cutover; it’s an ongoing process of improvement and development. Post-migration, efforts should focus on fine-tuning performance on the new OpenMetal platform. This involves continuously monitoring and optimizing database configurations (e.g., for PostgreSQL, this includes reviewing indexing strategies, cache settings, and query execution plans; for ClickHouse, optimizing primary keys, projections, and data sorting), server resource use (CPU, RAM, I/O on the bare metal servers), and ETL/ELT processes. For organizations using OpenStack, tuning the databases that support the OpenStack services themselves (often MySQL/MariaDB) can also help overall cloud performance, though this is different from tuning the data warehouse database itself.
Implementing monitoring and alerting is essential. This should cover system health, performance metrics (query latency, throughput, resource use), and data quality. OpenMetal clouds include built-in monitoring services from Datadog, which can provide visibility into key metrics and alert on potential issues. Alternatively, organizations can deploy open source monitoring solutions like Percona Monitoring and Management (PMM) or OpenStack Monasca.
The new platform will also open doors to explore further opportunities for optimization and using new capabilities. This could involve integrating advanced analytics tools, building AI/ML models using the data warehouse as a source, or expanding real-time data ingestion and processing capabilities.
Finally, regular reviews of performance, costs, and user satisfaction should be made a regular practice to proactively find areas for further improvement and to ensure the modernized data warehouse continues to meet changing business needs.
The following table provides a high-level overview of this phased migration roadmap:
Phase | Main Objectives | Core Activities | Success Factors |
|---|---|---|---|
| 1. Assessment & Planning | Understand current state, define goals, select technologies, design target. | Audit legacy DWH, define KPIs, choose open source DB and tools, design OpenMetal architecture, identify pilot project. | Strong stakeholder buy-in, accurate scope definition, realistic assessment of legacy complexity, appropriate technology choices. |
| 2. Pilot & PoC | Validate approach, tools, and architecture; identify risks; refine plan. | Set up OpenMetal environment, migrate pilot data subset, replicate/redesign pilot ETL, conduct rigorous data/performance/UAT testing. | Realistic PoC scope, thorough and objective testing, active user involvement, honest appraisal of PoC outcomes. |
| 3. Incremental Sprints | Migrate the bulk of the DWH in manageable stages, ensure business continuity. | Migrate data marts/functional areas iteratively, run legacy and new systems in parallel, continuously validate data and performance, train users. | Strong project management, effective change management, comprehensive user training, parallel run validation. |
| 4. Cutover & Decommissioning | Transition all operations to the new platform, realize cost savings. | Perform final data synchronization, redirect users and applications, conduct final comprehensive validation, decommission legacy system and licenses. | Flawless final data sync, clear communication plan, thorough post-cutover support, disciplined decommissioning process. |
| 5. Optimization & Evolution | Maximize value from the new platform, adapt to future needs. | Fine-tune performance (DB, server, ETL), implement comprehensive monitoring and alerting, explore new analytics/AI/ML capabilities, conduct regular reviews. | Continuous monitoring culture, proactive performance tuning, ongoing user feedback loop, strategic exploration of new features. |
Navigating Potential Challenges in Your Migration Journey
While the benefits of updating a legacy data warehouse to an open source solution on OpenMetal are many, the migration journey itself can have problems. Acknowledging these common challenges early and having plans to deal with them is helpful for a smooth and successful move.
Common migration challenges include:
Data Schema Conversion and Data Type Mapping
There are often major differences between the SQL versions used by proprietary databases (e.g., Teradata’s unique SQL style) and those of open source options like PostgreSQL or ClickHouse. Differences in supported data types, indexing methods, and partitioning strategies can make schema conversion a complex and careful task.
Rewriting or Migrating Complex SQL Queries and Stored Procedures
Legacy data warehouses often contain years, if not decades, of business logic built into complex SQL queries, stored procedures, user-defined functions, or proprietary scripting languages (like Teradata’s BTEQ scripts). Accurately moving this logic to the new database platform is often one of the most time-consuming and error-prone parts of the migration.
A big, and often underestimated, challenge here is the “hidden logic” trap. Business rules and data transformations can be hidden not just in obvious SQL code and stored procedures, but also in obscure ETL scripts, settings within BI reporting tools, or even in manual, undocumented processes that have developed around the legacy data warehouse. Finding and correctly migrating this deeply hidden logic is critical to prevent broken business processes and maintain data integrity after migration. This requires thorough investigation during the assessment phase, often involving close work with long-time business users and analysts who understand these details.
Ensuring Data Quality and Integrity
The process of extracting, transforming, and loading (ETL) large amounts of data has a built-in risk of data corruption, loss, or accidental duplication. Keeping data consistent and correct between the old and new systems, especially during times of parallel operation, is necessary to build trust in the new platform.
Minimizing Downtime and Business Disruption
For many organizations, the data warehouse is a critical system supporting ongoing operations, reporting, and decision-making. Any significant downtime during the migration can lead to lost productivity, missed opportunities, or even impact revenue. Therefore, the migration plan must be carefully organized to minimize disruption.
Skillset Adaptation for New Technologies
Internal IT teams, including DBAs and data engineers, who are very skilled with legacy proprietary systems may need a lot of training and hands-on experience to become equally good with new open source databases, the OpenStack cloud platform, Ceph storage, and related management and development tools. More than just technical training, it often means a cultural shift. Moving from a proprietary, often GUI-driven and vendor-supported legacy environment to an open source, frequently command-line-focused, and highly customizable ecosystem requires a change in thinking. Teams must adopt more DevOps practices, rely more on automation, and be willing to engage with community-driven solutions and documentation.
Open source solutions on bare metal offer power and flexibility but also require greater self-reliance, advanced troubleshooting skills, and proactive engagement with open source communities for solutions and best practices. Organizations must consciously support this cultural change alongside technical training to fully use the capabilities of the new platform and ensure long-term operational success. It may be smart to invest in training courses on your chosen new platforms before the migration is complete (or even started).
High-Level Ways to Reduce Problems, Largely Built Into the Recommended Phased Approach, Include:
- The Phased Approach Itself: The step-by-step nature of a phased migration allows the team to tackle these complex challenges in smaller, more manageable parts. Learnings from early phases can be used to reduce risk in later stages.
- Thorough Assessment and Planning (Phase 1): Carefully identifying complex queries, potential schema conflicts, data quality issues, and hidden business logic early in the project is essential. Don’t rush through this phase!
- Using Automated Tools (Where Appropriate): While not a perfect solution, various automated tools can help with tasks like schema analysis, data migration, and even partial code conversion. However, a significant amount of manual review, refactoring, and testing will almost certainly be needed. OpenMetal’s partner network may also offer specialized tools or services; for instance, solutions like Scramjet can help in complex data integration situations.
- Rigorous and Continuous Testing and Validation: This is something you must do at every stage of the migration, particularly during the PoC and throughout the parallel run sprints. Comprehensive testing is the main defense against data errors, performance slowdowns, and functional differences.
- Engaging OpenMetal Support and Expertise: Organizations should not hesitate to lean on OpenMetal’s customer success team and technical experts for help with infrastructure setup, performance optimization for their specific workloads, and connections to partners with specialized migration expertise. Our deep knowledge of OpenStack, Ceph, and bare metal environments can be very valuable. We’ve helped multiple partners design and build their big data pipelines and databases, and have been able to cut implementation time drastically while avoiding common pitfalls.
- Investing in Proactive Training and Skill Development: Acknowledge the learning curve and proactively plan for comprehensive team training on the new technologies. This investment will pay off time and time again in long-term operational efficiency and for maximizing the value from the modernized platform.
Here’s an overview of these common challenges and their corresponding primary mitigation strategies:
Challenge | Primary Mitigation Strategy |
|---|---|
| Complex Schema/SQL Conversion | Thorough upfront assessment and pilot testing of conversion processes; use of automated conversion tools where feasible, coupled with extensive manual review and refactoring. |
| Ensuring Data Quality & Integrity | Rigorous, multi-stage data validation (pre-, during-, post-migration); data profiling and cleansing activities; use of data comparison tools during parallel runs. |
| Minimizing Business Downtime | Phased rollout of functionality; Implementation of parallel run strategies; scheduling cutover activities during off-peak hours or planned maintenance windows. |
| Adapting Team Skillsets | Proactive and comprehensive training programs; encouraging certifications; mentoring by experienced consultants or OpenMetal support; fostering a culture of learning and experimentation. |
| Managing Unexpected Costs | Detailed budgeting based on PoC findings; using OpenMetal’s fixed-cost infrastructure; continuous monitoring of resource utilization in the new environment. |
By expecting these challenges and including these ways to reduce problems in the migration plan, organizations can handle the complexities of data warehouse modernization with more confidence and achieve their desired results.
Wrapping Up – Modernizing Your Data Warehouse with OpenMetal
Are you ready to move from a limited, expensive legacy data warehouse to a high-performance, agile, and cost-effective solution on OpenMetal? A modernization project of this scope can seem daunting, but using the phased migration approach we’ve outlined here should hopefully make the process much more manageable. And the results will be well worth it. You’ll gain huge improvements in both analytical abilities and cost savings, plus set your organization up for future success and a much more effective data strategy.
For Data Architects, CIOs, and Database Administrators currently dealing with the limits of outdated systems, now is the time for a serious review. Check your current data warehouse environment against the common problems of high costs, performance issues, scaling limits, vendor lock-in, and difficulties working with modern data. Then, consider the strong advantages—faster query speeds, much lower TCO, flexible scaling, freedom from proprietary limits, and a platform ready for AI/ML and real-time analytics—that a migration to an open source data warehouse hosted on OpenMetal can offer.
If you’re ready to start exploring the possibilities for your business, an initial consultation or a focused Proof of Concept is a low-risk, high-value first step. It can provide concrete, organization-specific data on potential performance gains and cost savings. This real evidence can then be used to build a strong internal business case, get stakeholder support, and confidently start the broader migration journey.
- Contact OpenMetal for a personalized consultation: Discuss your specific data warehouse challenges, modernization goals, and technical needs with our team. We can provide tailored advice and help you understand if our platform can meet your needs. Contact us here or directly schedule a consultation.
- Explore OpenMetal’s extensive resources: Look into our collection of case studies (particularly how we’re hosting a powerful ClickHouse deployment with a mix of bare metal, OpenStack, and Ceph), whitepapers, and articles covering data modernization, private cloud benefits, OpenStack, and Ceph.
- Request a Proof of Concept (PoC) environment on OpenMetal: There is no better way to check the platform’s capabilities than to test it with a subset of your own data and workloads. We offer PoC environments to help with this critical evaluation phase. Apply for a PoC here.
Modernizing your data warehouse is an investment in your organization’s data-driven future. By partnering with OpenMetal and using a strategic, phased migration, you can transform your data infrastructure into a powerful engine for innovation, efficiency, and lasting competitive advantage.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog