


































In this article
- The Challenge: Why Siloed Data Systems Hurt Businesses
- The Solution: A Unified Foundation on OpenMetal
- Analyzing a Customer’s Real-World Big Data Pipeline Architecture
- Practical Strategies for Integration on OpenMetal
- Wrapping Up: Unifying Your Data Lake and Data Warehouse
- Ready to Explore Big Data Capabilities on OpenMetal Cloud?
For any data architect or engineer, the architectural debate between the data lake and the data warehouse is a familiar one.
Data lakes are unmatched for storing huge volumes of raw, semi-structured, and unstructured data, making them the ideal playground for machine learning and exploratory data science.
Data warehouses, on the other hand, provide the clean, structured, and performant foundation required for business intelligence and executive reporting. For years, the standard approach has been to build and maintain both as separate, isolated systems.
This separation, however, creates problems. It forms data silos, where information is fragmented across different environments. It necessitates complex and often brittle Extract, Transform, Load (ETL) pipelines just to move data from the lake to the warehouse. The result is a significant bottleneck that delays the journey from raw data to valuable business insight.
But this architectural tug-of-war is often a false choice born from the limitations of traditional infrastructure. A new architecture, the data lakehouse, solves this problem. It combines the low-cost, flexible storage of a data lake with the powerful data management and transactional features of a data warehouse, creating a single, unified platform for all data workloads.
This article will explain how, why, and when you should use this model. By hosting both your data lake and data warehouse workloads on a unified, high-performance platform like OpenMetal, you can create a single, cohesive ecosystem and finally remove the barriers slowing your business and its data down.
The Challenge: Why Siloed Data Systems Hurt Businesses
When a data lake and a data warehouse operate on separate infrastructures, the consequences ripple and introduce technical friction. The operational overhead of managing two distinct technology stacks, each with its own security model, access controls, monitoring tools, and failure modes, is enormous.
This leads to the classic “swivel chair” problem. Data engineers find themselves constantly switching between different consoles, command-line interfaces, and cloud environments to manage the flow of data. This context switching is both a drain on productivity and a significant source of human error and configuration drift.
More fundamentally, physically separating the lake and warehouse creates an unavoidable time lag. The data in the warehouse is, by definition, a historical snapshot of the data that was once in the lake. This creates a trust problem. Every time data is copied and transformed between systems, its integrity is put at risk. A bug in an ETL script or a network hiccup can lead to dropped records or corrupted values.
Over time, this introduces a form of data entropy, where the two systems slowly drift apart and create competing versions of the truth. When a BI report from the warehouse contradicts the output of a data science model from the lake, business leaders lose faith in both, a cultural problem far more damaging than a slow ETL job. This entire process acts as a bottleneck, slowing the “time-to-insight” and directly impeding the organization’s ability to make fast, data-driven decisions.
The table below summarizes the key architectural differences between a traditional siloed approach and a unified platform built on OpenMetal.
| Traditional Siloed Approach (Separate Lake & Warehouse) | Unified Lakehouse on OpenMetal | |
| Storage Layer | Disparate systems (e.g., HDFS/S3 for lake, proprietary for warehouse) | Unified Ceph Object Storage Cluster for all data |
| Data Flow | Complex, multi-stage ETL pipelines moving/copying data | Data refined in place; high-speed internal transfers if needed |
| Data Consistency | High risk of inconsistency and staleness between systems | Single source of truth with transactional guarantees (Delta Lake) |
| Performance | Bottlenecks from public internet transfers and VM overhead | Bare metal performance with low-latency private networking |
| Management | High operational overhead managing two distinct environments | Simplified architecture with a single foundational platform |
| Cost Model | Redundant storage costs; unpredictable public cloud egress fees | Optimized storage; predictable, lower TCO with no egress penalties |
The Solution: A Unified Foundation on OpenMetal
The path to integrating your data systems begins at the infrastructure level. OpenMetal provides a solution by offering an on-demand private cloud that fuses the best attributes of different hosting models: the agility of public cloud, the control and security of private cloud, and the raw power of bare metal. This unique combination creates the perfect foundation to break down data silos by supporting a true data lakehouse architecture.
The core of this advantage lies in two key technologies: bare metal performance and unified Ceph storage.
Bare Metal Power
First, OpenMetal clouds are built on dedicated bare metal servers. This is an important differentiator for data-intensive workloads. In a typical virtualized public cloud, a hypervisor consumes 5-10% of a server’s CPU and RAM, creating a persistent performance drag. Furthermore, the “noisy neighbor” effect, where other tenants’ workloads interfere with yours, leads to unpredictable job runtimes. By running directly on bare metal, you eliminate both the hypervisor tax and the noisy neighbor effect, ensuring direct, unmediated access to hardware for consistent, maximum performance.
Scalable Ceph Storage
Second, this powerful compute is paired with a pre-configured, massively scalable Ceph storage cluster. Ceph is an open source, software-defined storage platform that provides unified object, block, and file storage from a single system. The crucial component for modern data architectures is its RADOS Gateway (RGW), which exposes an Amazon S3-compatible API. The entire ecosystem of modern data tools, including Apache Spark and Delta Lake, is built to communicate natively with this S3 interface. This means they can read from and write to your private Ceph cluster as if it were a public cloud object store, with no code changes required.
This is the key to breaking down silos at the infrastructure level. A single, resilient Ceph cluster can serve as the storage backbone for your entire data platform. It can hold the raw, unstructured files for your data lake and simultaneously act as the storage layer for a modern data warehouse or a lakehouse architecture. By unifying storage, you get rid of any architectural division and create a single, high-throughput data repository for all your workloads. This infrastructure choice unlocks possibilities that are difficult to implement on generic, multi-tenant cloud infrastructure.
Analyzing a Customer’s Real-World Big Data Pipeline Architecture
Theory is useful, but a real-world blueprint is better. The architecture diagram below represents an in-use, modern data pipeline built by a customer on OpenMetal. It demonstrates how to assemble best-in-class open source tools on a unified foundation to create a single source of truth for all analytics needs.
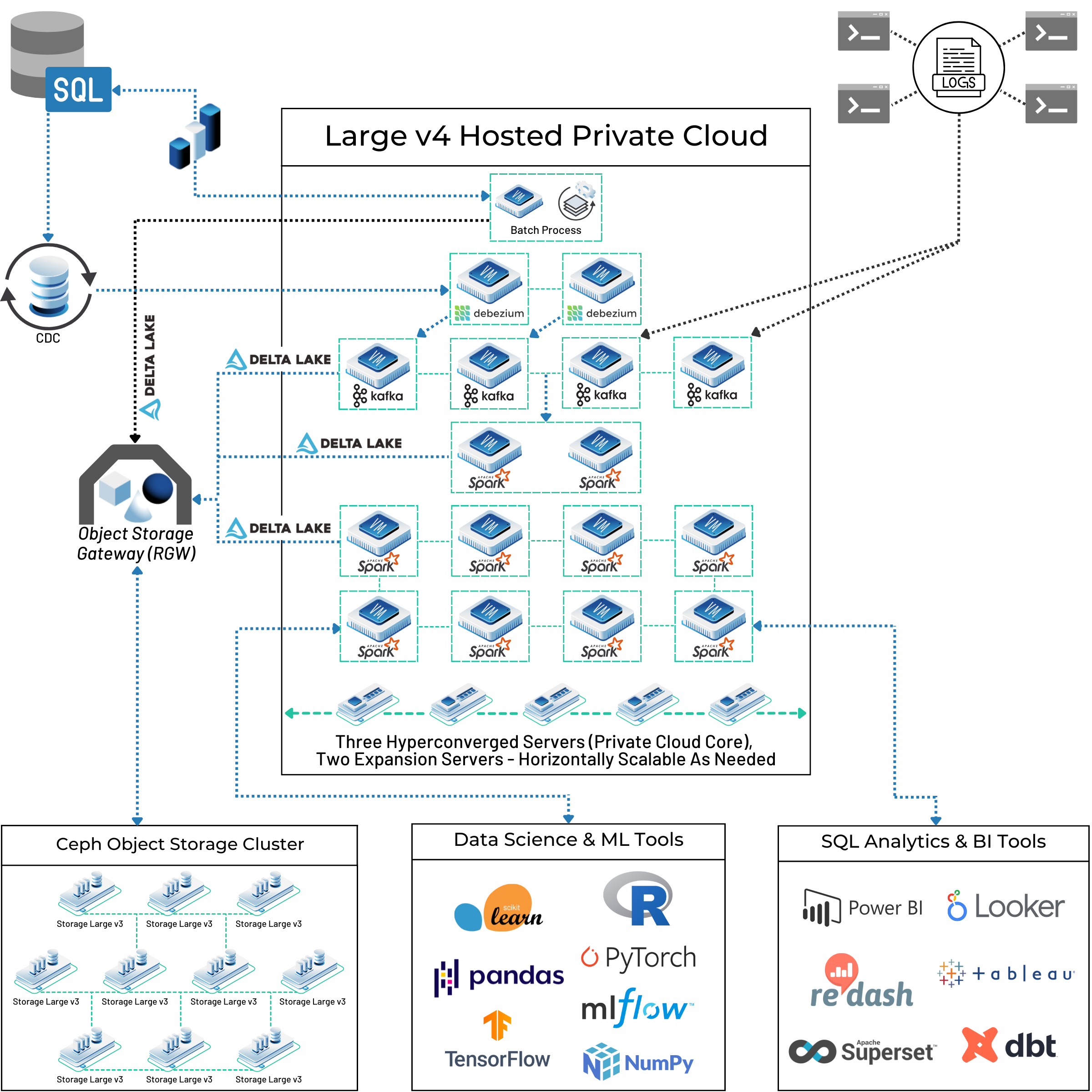
Let’s walk through the data flow from start to finish.
Data Ingestion
The pipeline ingests data from two primary sources: traditional SQL databases and application logs. For the SQL databases, the architecture uses a technique called Change Data Capture (CDC). Instead of performing periodic bulk dumps, it uses Debezium, an open source distributed platform for CDC. Debezium monitors the database’s transaction log, captures every row-level change (INSERT, UPDATE, DELETE) as it happens, and streams these changes as events. This provides an efficient, low-impact, real-time stream of data from transactional systems.
Streaming and Processing
All incoming data, whether from Debezium or log shippers, flows into Apache Kafka. Kafka acts as a durable, fault-tolerant, and scalable streaming bus, decoupling the data producers from the consumers.
From Kafka, the data is consumed in near real-time by multiple Apache Spark clusters. As shown in the diagram, these Spark clusters run on our “Large v4 Hosted Private Cloud“, which is the OpenStack-powered core running on OpenMetal’s bare metal servers. Spark serves as the massively parallel processing engine, executing the transformations and business logic required to clean, enrich, and structure the raw data.
The “Lakehouse” Core
This is the heart of the entire system. After processing by Spark, the data lands in a Delta Lake format. Critically, this Delta Lake lives on the Ceph Object Storage Cluster. This connection is the physical and logical manifestation of the unified architecture.
This combination creates a true “lakehouse”: a modern data architecture that blends the key benefits of a data lake and a data warehouse. It has the massive scalability and cost-effectiveness of a data lake because its data lives as files in a Ceph object store. At the same time, it provides the reliability, data quality, and transactional guarantees of a data warehouse, thanks to the features of Delta Lake.
This unified core serves as the single source of truth for the entire organization. This architecture mixes best-of-breed open source tools, giving the data team complete control and freedom from vendor lock-in.
Consumption
The final stage really shows the power of this unified approach. The single, curated data source in the lakehouse serves two completely different sets of consumers without requiring data duplication or movement:
- Data Science & ML Tools: Libraries and platforms like PyTorch, TensorFlow, pandas, scikit-learn, and MLflow can access the Delta Lake tables to pull clean, reliable data for model training, validation, and inference.
- SQL Analytics & BI Tools: Business intelligence platforms like Power BI, Tableau, and Looker, as well as transformation tools like dbt, can execute standard SQL queries against the very same Delta Lake tables (via the Spark SQL engine). This powers interactive dashboards, executive reports, and ad-hoc analysis.
This architecture achieves the ultimate goal: a single, consistent, and up-to-date data platform that serves all analytics use cases, from historical reporting to predictive machine learning.
Practical Strategies for Integration on OpenMetal
The architecture diagram provides a blueprint. Now, let’s translate that into actionable strategies you can use to integrate your data lake and data warehouse on OpenMetal. The primary choice is between building a unified data lakehouse or maintaining separate systems that are tightly integrated on the same high-performance infrastructure.
Strategy 1: Building a Lakehouse with Delta Lake and Ceph
For most modern data needs, this is the ideal approach. It simplifies your architecture, eliminates data silos, and provides a single source of truth for both BI and ML workloads.
The most helpful strategy is to stop thinking about moving data out of the lake and instead bring warehouse capabilities into the lake. This is the essence of the lakehouse pattern, and the key is combining Delta Lake with OpenMetal’s Ceph storage. Delta Lake is an open source storage layer that sits on top of your existing object store, adding a transaction log that provides powerful, warehouse-like features.
- ACID Transactions: This is the pivotal feature. ACID stands for Atomicity, Consistency, Isolation, and Durability. In practice, it means that every write operation to your Delta Lake is an all-or-nothing transaction. If a Spark job fails midway through writing a million records, the transaction is aborted, and the table is left in its previous, valid state. This prevents the data corruption and partially written files that commonly plague traditional data lakes.
- Schema Enforcement: By default, Delta Lake acts as a data quality gatekeeper. It checks all new writes to ensure they match the target table’s schema (column names, data types). If there’s a mismatch, it rejects the write and raises an exception. This prevents data pollution from errant scripts or bad data sources. For intentional changes, schema evolution can be explicitly allowed, letting you add new columns without rewriting the entire table.
- Time Travel: Delta Lake automatically versions every change made to a table. This impressive feature, known as Time Travel, allows you to query the data “as of” a specific timestamp or version number. This is invaluable for auditing data changes, instantly rolling back bad writes, debugging data quality issues, and ensuring the reproducibility of machine learning experiments by pinning a model to an exact version of a dataset.
Strategy 2: High-Speed Data Movement for Co-existing Systems
While the lakehouse is the goal for many, there are valid scenarios where maintaining a separate, dedicated data warehouse makes sense alongside a data lake. These situations include:
- Significant existing investment in a specialized, proprietary data warehouse platform that cannot be easily retired.
- Ultra-low-latency query requirements for specific BI dashboards that are best served by a purpose-built analytical database.
- Strict organizational separation or compliance rules that mandate physically distinct systems for different types of analytics.
- As part of a phased migration where you run both systems in parallel before a full cutover.
Even in these cases, the principle of a unified foundation holds. The strategy is to co-locate both the data lake and the data warehouse on the same OpenMetal private cloud. The advantage is proximity. Because both systems are running in the same data center, connected by OpenMetal’s high-speed, low-latency private network (standard 20Gbps), data transfers between them are incredibly fast and secure. This avoids the slow, expensive, and insecure process of moving terabytes of data over the public internet. This approach makes a phased migration strategy much more practical, allowing you to run both systems in parallel while gradually moving workloads to the modern lakehouse architecture.
Strategy 3: Unifying with Open Source Tools
The architecture shown in the diagram is built entirely on powerful, community-driven, open source technologies. This is a strategy that gives your team maximum flexibility and control. You are not tied to a single vendor’s proprietary ecosystem, pricing model, or product roadmap. You can choose the best tool for each part of the job and tune it to your specific needs.
OpenMetal’s platform is built on this same philosophy. We use open source technologies like OpenStack and Ceph to power our clouds. Our infrastructure is designed and validated to be the ideal environment for running these data tools, giving you the performance and control of a private cloud without the management burden of running your own hardware.
Wrapping Up: Unifying Your Data Lake and Data Warehouse
The long-standing division between the data lake and the data warehouse is a byproduct of legacy infrastructure that was never designed for today’s data demands. The path forward is not to build more complex bridges between these silos but to remove the silos altogether. OpenMetal provides the on-demand private cloud infrastructure that allows data teams to do just that.
By unifying your data workloads on OpenMetal, you gain tangible benefits:
- Simplified Data Architecture: A single, cohesive platform reduces operational complexity and eliminates redundant systems.
- Faster Data Flow: The combination of bare metal performance, unified Ceph storage, and high-speed private networking accelerates the entire data lifecycle, from raw ingestion to critical insight.
- Lower Total Cost of Ownership: By eliminating proprietary software licenses and unpredictable public cloud egress fees, organizations can see cloud cost reductions of up to 50% or more, all with a predictable cost model.
- Superior Performance and Control: Dedicated bare metal resources and full root access give you a level of control and performance consistency that is simply not possible in a shared, multi-tenant public cloud.
Your Infrastructure, Your Way
Perhaps most importantly, OpenMetal offers the unique flexibility to custom-build the perfect solution for your specific needs. You can seamlessly connect a hosted private cloud built on OpenStack, dedicated bare metal servers for specialized databases, GPU-accelerated nodes for machine learning, and a massive Ceph storage cluster. This ability to mix and match infrastructure types allows you to build a truly optimized, future-proof data platform.
For data architects and engineers planning their next-generation data platform, we say it’s time to move beyond the limitations of the past. A unified private cloud approach offers a path to a simpler, faster, and more cost-effective data architecture. We invite you to explore how OpenMetal can serve as the foundation for your integrated data ecosystem.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog