


































In this article
We walk through why splitting DR across EU and APAC makes more sense than stacking everything on a single hyperscaler, covering the data residency compliance case for Amsterdam and Singapore as DR sites, a practical architecture model using US primary with warm standby in both regions, the specific hardware available at each OpenMetal location, and what the fixed-cost model means for your replication budget when you stop paying per-gigabyte egress fees.
When your primary infrastructure sits in the US and your customers span Europe and Asia-Pacific, a single-region DR site creates a problem that most continuity plans don’t acknowledge until something goes wrong. A DR environment in a second US region protects you from datacenter failures. It doesn’t protect you from a regional cloud event that takes down your primary and your recovery site at the same time, and it doesn’t help you meet the growing list of EU and APAC data residency requirements that increasingly specify where recovery infrastructure must physically reside.
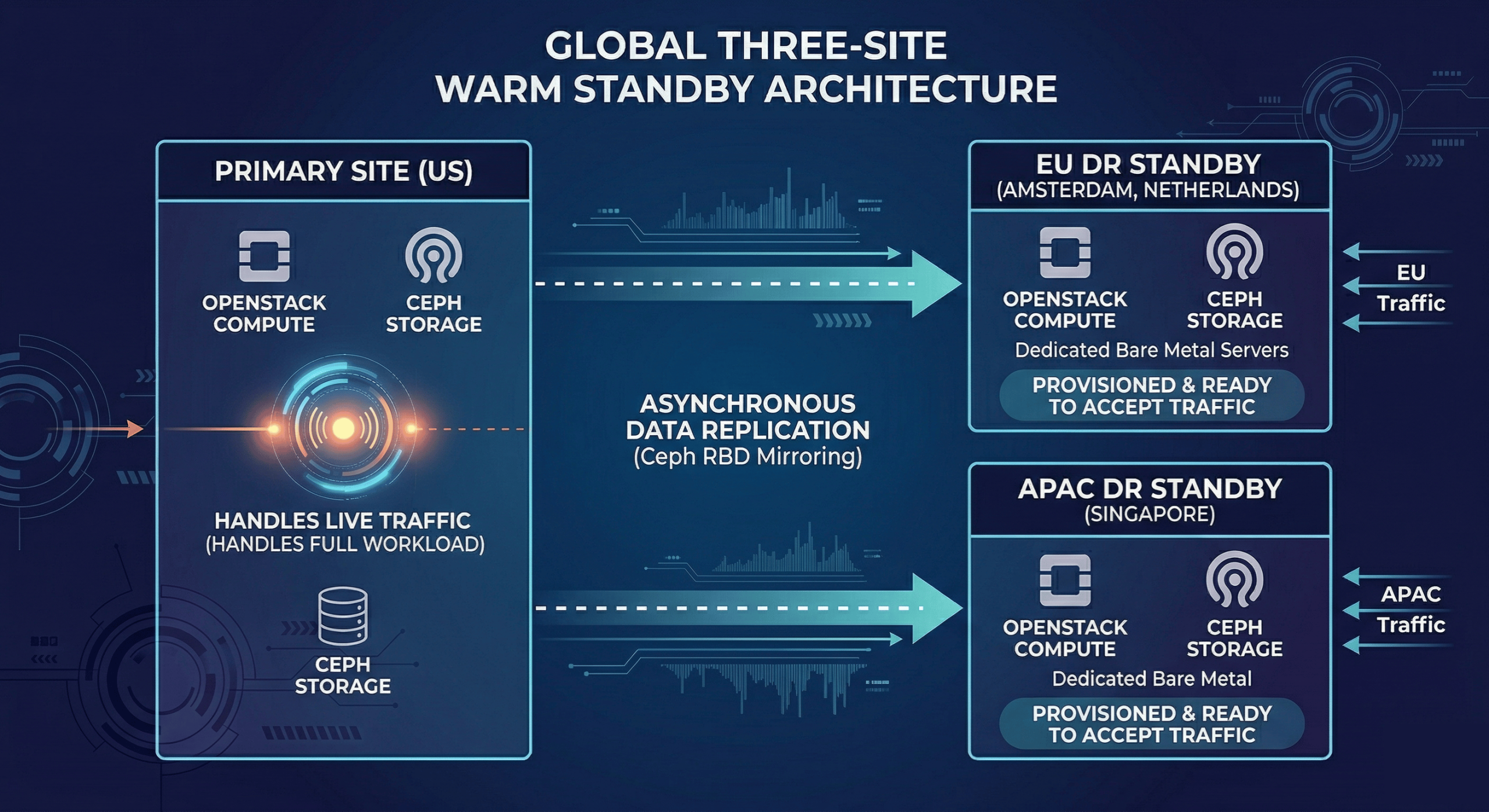
The architecture that actually solves this runs a US-based primary with warm standby capacity split between Amsterdam and Singapore. EU workloads and EU customer data replicate to Amsterdam. APAC workloads and APAC customer data replicate to Singapore. Both DR sites run on dedicated bare metal with predictable monthly pricing, which means your replication jobs and DR drills don’t generate variable egress bills on top of your infrastructure spend.
This post covers how to structure that architecture, what the compliance case is for each location, and what hardware is available at each site to support the workload profile you’re protecting.
Why a US-Primary Architecture Needs Both EU and APAC DR Sites
The obvious answer is geographic redundancy: if your US primary goes down, you want recovery capacity that isn’t dependent on US infrastructure. But the less obvious answer has more to do with compliance and latency than with outage scenarios.
GDPR gives EU residents specific rights over their personal data, and those rights extend to disaster recovery. If your EU customers’ data replicates to a US-based DR site, you’re transferring personal data outside the EU. That transfer requires either an adequacy decision covering the destination country, Standard Contractual Clauses, or another lawful transfer mechanism. In practice, this means many organizations need EU-resident DR for their EU workloads, not as a preference but as a requirement. As noted in recent analysis of the global data residency environment, data residency requirements create cascading compliance challenges where backup and disaster recovery plans need to respect localization boundaries.
The APAC case is more varied but trending in the same direction. Singapore itself doesn’t have a data localization mandate, but its neighbors increasingly do. India’s Digital Personal Data Protection Act, Indonesia’s Personal Data Protection Law, and similar frameworks in other APAC markets create a patchwork where Singapore-based infrastructure functions as a compliant APAC hub. Replicating to Singapore positions your DR architecture to serve customers in markets where cross-border data movement is increasingly restricted, without needing in-country infrastructure in every jurisdiction.
The performance argument reinforces the compliance one. A US-based DR site serving APAC users during an actual failover introduces significant latency. Singapore-based recovery infrastructure puts your users back on an endpoint that’s geographically reasonable for their traffic patterns, which matters for the user experience during what is already a disruptive event.
There’s also an infrastructure diversity argument. As covered in Why Disaster Recovery Is a Business Decision, Not a Technical One, using a different infrastructure provider as your DR site reduces the probability that a platform-level incident affects both your primary and your recovery environment simultaneously. A DR site on OpenMetal’s dedicated bare metal provides genuine separation from whatever provider runs your primary, in both regions.
The Architecture: US Primary, Amsterdam and Singapore Warm Standby
Primary Site (US)
Your US production environment handles live traffic. This is where your full workload runs day-to-day, with OpenStack managing compute and Ceph handling block and object storage. Replication runs continuously to both DR sites, with replication frequency tuned to your RPO targets per workload tier.
Amsterdam DR Site (EU)
Amsterdam serves as your EU warm standby. EU-origin traffic, EU customer data, and any workloads subject to GDPR data residency requirements replicate here. The environment stays provisioned but idle under normal conditions, ready to accept traffic within the RTO window if the primary fails. Because the environment is already running on dedicated hardware, there’s no cold-start time waiting for instances to provision: the delay is in replication lag and failover orchestration, not infrastructure spin-up.
Amsterdam’s position as a network hub makes it the right choice for EU DR. The AMS-IX internet exchange is among the largest in the world by traffic volume, and the city’s fiber connectivity to the rest of Europe and transatlantic routes is well-established. For GDPR purposes, the Netherlands is an EU member state, which means data stored in Amsterdam is stored in the EU, with no transfer mechanism required for EU-resident personal data.
For additional context on Amsterdam’s regulatory and infrastructure positioning, see the post-Brexit case for Amsterdam infrastructure.
Singapore DR Site (APAC)
Singapore serves as your APAC warm standby. APAC-origin traffic and workloads serving customers in the Asia-Pacific region replicate here. Singapore is the natural APAC hub choice for several reasons: it’s one of the most connected cities in the world by submarine cable, its Personal Data Protection Act (PDPA) is mature and generally interoperable with other privacy frameworks, and its position at the geographic center of Southeast Asia gives reasonable latency to the markets most likely to need APAC-resident DR.
For teams running AI or ML workloads, the Singapore site also supports SGX and TDX-enabled dedicated servers at the XL and XXL tiers, which matters if your DR workloads include inference pipelines or training jobs where confidential computing is a requirement. See the Singapore facility specs for full datacenter details.
Replication Strategy
The asynchronous replication guide for OpenStack clouds covers the trade-offs in detail, but the short version for a warm standby architecture is: asynchronous replication between your US primary and both DR sites is the right default for most workloads. Synchronous replication across intercontinental distances introduces latency into your production write path that’s rarely worth the RPO improvement for tier-2 and tier-3 workloads. Tier-1 workloads with near-zero RPO requirements may need synchronous replication within a single region, with asynchronous cross-region replication for DR.
Ceph RBD mirroring handles block storage replication between sites. For object storage, Swift replication provides the equivalent mechanism for S3-compatible workloads.
For failover orchestration, the five failover strategies for OpenStack clouds covers the options from active-active through cold standby. For a warm standby configuration like this one, an active-passive approach with automated health monitoring and manual failover confirmation for tier-1 workloads is usually the right balance between recovery speed and the risk of unintended failovers.
Available Hardware at Each DR Site
One of the practical decisions in designing a multi-region DR architecture is matching hardware at each DR site to the workload tier you’re protecting. You don’t need to replicate your full production hardware footprint at a warm standby site, but you do need enough capacity to run the tier-1 and tier-2 workloads that justify the DR investment in the first place.
OpenMetal offers two deployment models at both Amsterdam and Singapore: bare metal dedicated servers for teams that want single-tenant hardware they manage directly, and hosted private cloud for teams that want a fully deployed OpenStack and Ceph cluster ready to receive workloads from day one. Both run on the same underlying hardware generations. The right choice for DR depends on whether you need the flexibility of a managed OpenStack environment or direct hardware access for custom virtualization stacks.
Amsterdam Hardware
The Amsterdam site carries the widest hardware selection of the two locations, spanning Medium through XXL configurations and several high-frequency and storage-optimized variants. All servers run dual-socket configurations.
Bare Metal Dedicated Servers (Amsterdam)
- Medium v4 (Top Seller): 2x Intel Xeon Silver 4510, 24C/48T, 6.4TB NVMe, 256GB DDR5 4400MHz, 2Gbps public bandwidth — $619.20/month | $572.76/month (1-year) | $408.67/month (5-year). The right entry point for tier-3 workloads and dev/staging environments that need DR coverage without the footprint of a production server.
- Large v2: 2x Intel Xeon Silver 4314, 32C/64T, 2x 3.2TB NVMe, 512GB DDR4 3200MHz, 4Gbps — $734.40/month | $679.32/month (1-year) | $484.70/month (5-year).
- Large v2.1: 2x Intel Xeon Silver 4314, 32C/64T, 2x 6.4TB NVMe, 512GB DDR4 3200MHz, 4Gbps — $986.40/month | $912.42/month (1-year) | $651.02/month (5-year).
- Large v3: 2x Intel Xeon Gold 5416S, 32C/64T, 2x 6.4TB NVMe, 512GB DDR5 4400MHz, 4Gbps — $1,101.60/month | $1,018.98/month (1-year) | $727.06/month (5-year).
- Large v4 (Top Seller): 2x Intel Xeon Gold 6526Y, 32C/64T, 2x 6.4TB NVMe, 512GB DDR5 5200MHz, 4Gbps — $1,173.60/month | $1,085.58/month (1-year) | $774.58/month (5-year). The practical entry point for tier-2 production workloads. DDR5 memory and NVMe storage handle database workloads and virtualized environments without significant performance compromise relative to production.
- XL v2: 2x Intel Xeon Gold 6338, 64C/128T, 4x 3.2TB NVMe, 1024GB DDR4 3200MHz, 6Gbps — $1,476.00/month | $1,365.30/month (1-year) | $974.16/month (5-year).
- XL v2.1: 2x Intel Xeon Gold 6338, 64C/128T, 4x 6.4TB NVMe, 1024GB DDR4 3200MHz, 6Gbps — $1,620.00/month | $1,498.50/month (1-year) | $1,069.20/month (5-year).
- XL v2.2: 2x Intel Xeon Gold 6338, 64C/128T, 6x 6.4TB NVMe, 1024GB DDR4 3200MHz, 6Gbps — $1,893.60/month | $1,751.58/month (1-year) | $1,249.78/month (5-year).
- XL v3: 2x Intel Xeon Gold 6430, 64C/128T, 4x 6.4TB NVMe, 1024GB DDR4 4400MHz, 6Gbps — $1,843.20/month | $1,704.96/month (1-year) | $1,216.51/month (5-year).
- XL v4 (Top Seller): 2x Intel Xeon Gold 6530, 64C/128T, 4x 6.4TB NVMe, 1024GB DDR5 4800MHz, 6Gbps — $1,987.20/month | $1,838.16/month (1-year) | $1,311.55/month (5-year). Appropriate for tier-1 warm standby where the primary environment is similarly sized. Core count and memory support high VM density for production-equivalent capacity during an actual failover.
- XL v4 High Frequency: 2x Intel Xeon Gold 6544Y, 32C/64T, 4x 6.4TB NVMe, 1024GB DDR5 5200MHz, 6Gbps — $2,188.80/month | $2,024.64/month (1-year) | $1,444.61/month (5-year). For latency-sensitive workloads where clock speed matters more than core count, the 3.6/4.1GHz frequency profile is the right trade-off.
- XXL v4: 2x Intel Xeon Gold 6530, 64C/128T, 6x 6.4TB NVMe, 2048GB DDR5 4800MHz, 10Gbps — $2,779.20/month | $2,570.76/month (1-year) | $1,834.27/month (5-year). The top tier for large database or high-memory workloads that need the full production hardware footprint in DR.
- Storage Large v1: 2x Intel Xeon Silver 4210R, 20C/40T, 12x 12TB HDD plus 4x 1.92TB NVMe, 128GB DDR4 2933MHz, 4Gbps — $734.40/month | $679.32/month (1-year) | $484.70/month (5-year). Purpose-built for high-capacity storage workloads. If your DR strategy involves bulk data backup or object storage replication at scale, this is the tier for it.
Hosted Private Cloud (Amsterdam)
Private cloud deployments are clusters of three hyperconverged servers running production OpenStack and Ceph, deployed and ready to use. Rather than provisioning and configuring OpenStack yourself, you get a fully operational cluster that can begin accepting replicated workloads on day one. Pricing below is per 30-day billing cycle; longer-term commitments carry meaningful discounts.
- Medium v4: $2,376.00/month ($2,197.80/month with a 1 year agreement, $1,568.16/month with a 5 year)
- Large v2: $2,980.80/month ($2,757.24/month with a 1 year agreement, $1,967.33/month with a 5 year)
- Large v2.1: $3,736.80/month ($3,456.54/month with a 1 year agreement, $2,466.29/month with a 5 year)
- Large v3: $4,082.40/month ($3,776.22/month with a 1 year agreement, $2,694.38/month with a 5 year)
- Large v4: $4,298.40/month ($3,976.02/month with a 1 year agreement, $2,836.94/month with a 5 year)
- XL v2: $5,616.00/month ($5,194.80/month with a 1 year agreement, $3,706.56/month with a 5 year)
- XL v2.1: $6,048.00/month ($5,594.40/month with a 1 year agreement, $3,991.68/month with a 5 year)
- XL v3: $6,717.60/month ($6,213.78/month with a 1 year agreement, $4,433.62/month with a 5 year)
- XL v4: $7,149.60/month ($6,613.38/month with a 1 year agreement, $4,718.74/month with a 5 year)
- XXL v4: $10,238.40/month ($9,470.52/month with a 1 year agreement, $6,757.34/month with a 5 year)
For teams committing to DR infrastructure on a multi-year basis, the long-term pricing is worth factoring into the total cost comparison with hyperscaler DR. A Cloud Core Large v4 at the 5-year rate runs $2,836.94/month versus $4,298.40 at month-to-month, which changes the economics considerably for an organization that knows it needs GDPR-resident EU DR for the foreseeable future.
Full Amsterdam hardware specs and deployment options are available at the Amsterdam facility page and the cloud deployment calculator.
Singapore Hardware
The Singapore site offers a focused set of high-density configurations, all with 20Gbps private bandwidth included. The catalog is built around compute-intensive workloads, and all XL and XXL servers meet the hardware requirements for Intel SGX and TDX out of the box.
Bare Metal Dedicated Servers (Singapore)
- Medium v4 (Top Seller): 2x Intel Xeon Silver 4510, 24C/48T, 6.4TB NVMe, 256GB DDR4 4400MHz, 2Gbps — $792.00/month | $732.60/month (1-year) | $522.72/month (5-year). For teams running lighter DR workloads or needing a cost-effective warm standby node for non-critical APAC systems.
- Large v4 (Top Seller): 2x Intel Xeon Gold 6526Y, 32C/64T, 2x 6.4TB NVMe, 512GB DDR5 5200MHz, 4Gbps — $1,504.80/month | $1,391.94/month (1-year) | $993.17/month (5-year). The standard entry point for APAC production-equivalent DR capacity.
- XL v4 (Top Seller): 2x Intel Xeon Gold 6530, 64C/128T, 4x 6.4TB NVMe, 1024GB DDR5 4800MHz, 6Gbps — $2,541.60/month | $2,350.98/month (1-year) | $1,677.46/month (5-year). High-core-count warm standby for virtualized environments with high VM density requirements.
- XL v4 High Frequency (Top Seller): 2x Intel Xeon Gold 6544Y, 32C/64T, 4x 6.4TB NVMe, 1024GB DDR5 5200MHz, 6Gbps — $2,800.80/month | $2,590.74/month (1-year) | $1,848.53/month (5-year). The recommended tier for AI/ML inference workloads in DR, particularly where TDX-based confidential computing is required for model or data protection.
- XXL v4: 2x Intel Xeon Gold 6530, 64C/128T, 6x 6.4TB NVMe, 2048GB DDR5 4800MHz, 10Gbps — $3,556.80/month | $3,290.04/month (1-year) | $2,347.49/month (5-year). For organizations running large-scale APAC workloads where the DR site needs full production parity.
Hosted Private Cloud (Singapore)
Singapore private cloud deployments are available across the Medium v4, Large v4, XL v4, XL v4 High Frequency, and XXL v4 hardware tiers, corresponding to the bare metal generations available at that location. Pricing is currently available on request by contacting the OpenMetal team directly.
Full hardware specs and connectivity details are at the Singapore facility page.
What Fixed-Cost Infrastructure Actually Means for Multi-Region DR
The reason most multi-region DR architectures end up on hyperscalers isn’t that hyperscalers are better at DR. It’s that they’re familiar and easy to provision. The cost consequences of that decision often don’t show up until the architecture is already built.
Hyperscaler DR billing has three layers that compound: the replication agent fees (AWS Elastic Disaster Recovery runs approximately $20 per server per month), the standby compute for provisioned recovery instances, and the egress charges for data movement between sites. That last item is what makes multi-region DR on a hyperscaler particularly expensive, because continuous replication generates continuous egress. AWS charges $0.09/GB for the first 10TB of outbound transfer. Azure charges similarly. For an architecture replicating meaningful data volumes across two international DR sites, those charges add up fast. And because the charges accumulate every time you run a DR drill, organizations end up under-testing their plans to manage the bill.
OpenMetal’s bare metal pricing includes egress allotments as part of the monthly rate. The Amsterdam and Singapore servers listed above include between 2Gbps and 10Gbps public bandwidth depending on tier, and there are no per-gigabyte charges for replication traffic between OpenMetal sites. The same 125TB of monthly egress that costs roughly $7,500 on a major hyperscaler costs nothing additional on OpenMetal within the included allotment. You can verify your expected volumes against the egress pricing calculator.
The operational consequence of this is more significant than the cost saving itself. When DR testing doesn’t generate a variable bill, you test more frequently. When you test more frequently, your runbooks stay accurate and your team knows what to do when a real event happens. Research on DR readiness shows a persistent gap between organizational confidence and actual recovery capability: more than 60% of organizations believe they could recover within hours, while only 35% actually can. That gap is partly a testing frequency problem, and testing frequency is partly a cost problem. A fixed-cost DR environment removes one of the most common reasons teams under-invest in DR drills.
For a more detailed cost comparison between OpenMetal and hyperscaler DR, including the egress math at different data volumes, see Why Disaster Recovery Is a Business Decision, Not a Technical One.
Workload Tiering for a Three-Site Architecture
Not every workload needs warm standby protection at both DR sites. The right approach is to tier your workloads and allocate DR resources accordingly, using the Business Impact Analysis framework covered in the DR business decision post.
Tier 1: Revenue-Critical and Compliance-Sensitive Workloads
These replicate to both Amsterdam and Singapore, with the replication target determined by data residency: EU customer data goes to Amsterdam, APAC customer data goes to Singapore. RTO targets for tier-1 are typically 15 minutes to one hour, with near-zero RPO requiring continuous asynchronous replication. Examples: payment processing, customer-facing APIs, databases containing regulated personal data.
For OpenStack environments, Ceph RBD mirroring handles block storage replication for these workloads. The multi-site high availability infrastructure guide covers networking and compute configuration for active-passive setups at this tier.
Tier 2: Important but Not Revenue-Blocking
These may replicate to a single DR site based on where the majority of users are, or to both sites at a lower replication frequency. RTO of two to four hours is generally acceptable. Examples: internal applications, analytics pipelines, non-customer-facing databases.
The OpenStack backup automation tools guide and the OpenMetal volume backup documentation cover implementation options at this tier.
Tier 3: Non-Critical Systems
Backup and restore rather than warm standby. RTOs of eight hours or more are acceptable. These systems don’t need dedicated warm standby capacity at either DR site. OpenMetal’s backup and restore procedures for OpenStack databases and data backup tutorials cover implementation for this tier.
Compliance Documentation for a Multi-Region Architecture
A three-site DR architecture with EU and APAC nodes creates a documentation requirement that’s more complex than a single-site plan. Auditors evaluating SOC 2, HIPAA, or PCI-DSS compliance want to see that you’ve thought through what happens to regulated data in each site during a failover, not just that your systems come back online.
The key documentation artifacts for a multi-region architecture:
- Data flow documentation showing which customer data originates in which region, which DR site it replicates to, and how that mapping satisfies applicable data residency requirements.
- Per-site runbooks rather than a single DR plan. Amsterdam failover procedures differ from Singapore failover procedures, and a combined document is harder for your team to execute under pressure and harder for auditors to evaluate clearly.
- Test records organized by site. When you run a DR drill for your Amsterdam standby, the test record should document the scope, the RTO achieved, any gaps found, and remediation steps taken. Same for Singapore. Auditors want evidence that each site has been tested, not just that you have DR infrastructure.
- Vendor documentation for each site confirming the physical location of hardware, applicable certifications (SOC 2, ISO 27001, HIPAA), and the provider’s responsibilities under your shared responsibility model. OpenMetal’s datacenter locations and compliance certifications are documented at the Amsterdam facility page and Singapore facility page.
The OpenMetal operator’s manual disaster recovery section covers the technical configuration layer. The documentation most organizations are missing is the layer above that: the written procedures, data flow maps, and test evidence that compliance frameworks require.
Getting Started
The right starting point for a multi-region DR project depends on where you are in your DR maturity. If you haven’t completed a Business Impact Analysis and tiered your workloads by RPO/RTO requirements, start there before provisioning any infrastructure. The DR business decision framework walks through that process in detail.
If you have your tiers defined and are evaluating DR sites, the Amsterdam and Singapore hardware options above give you the range from cost-effective tier-3 coverage up to full production-parity warm standby for tier-1 workloads. The fixed-cost model means you can build the DR architecture your workloads actually need without the variable billing that makes multi-region DR on hyperscalers difficult to budget.
To discuss your specific architecture or get hardware recommendations for your workload profile, schedule a consultation with the OpenMetal team, or browse the full bare metal pricing catalog to start matching hardware to your DR tiers.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog