


































In This Article
Research firm Forrester predicts at least two major multi-day hyperscaler outages will hit in 2026 as AWS, Azure, and Google Cloud prioritize AI infrastructure upgrades over aging legacy systems. Here’s what infrastructure leaders need to know about reducing dependency and building resilience.
The 2025 AWS and Azure outages that disrupted businesses across multiple regions weren’t isolated incidents. According to Forrester’s Predictions 2026: Cloud Computing report, they were previews of what’s coming this year.
The research firm makes a stark prediction: AI data center upgrades will trigger at least two major multi-day cloud outages in 2026.
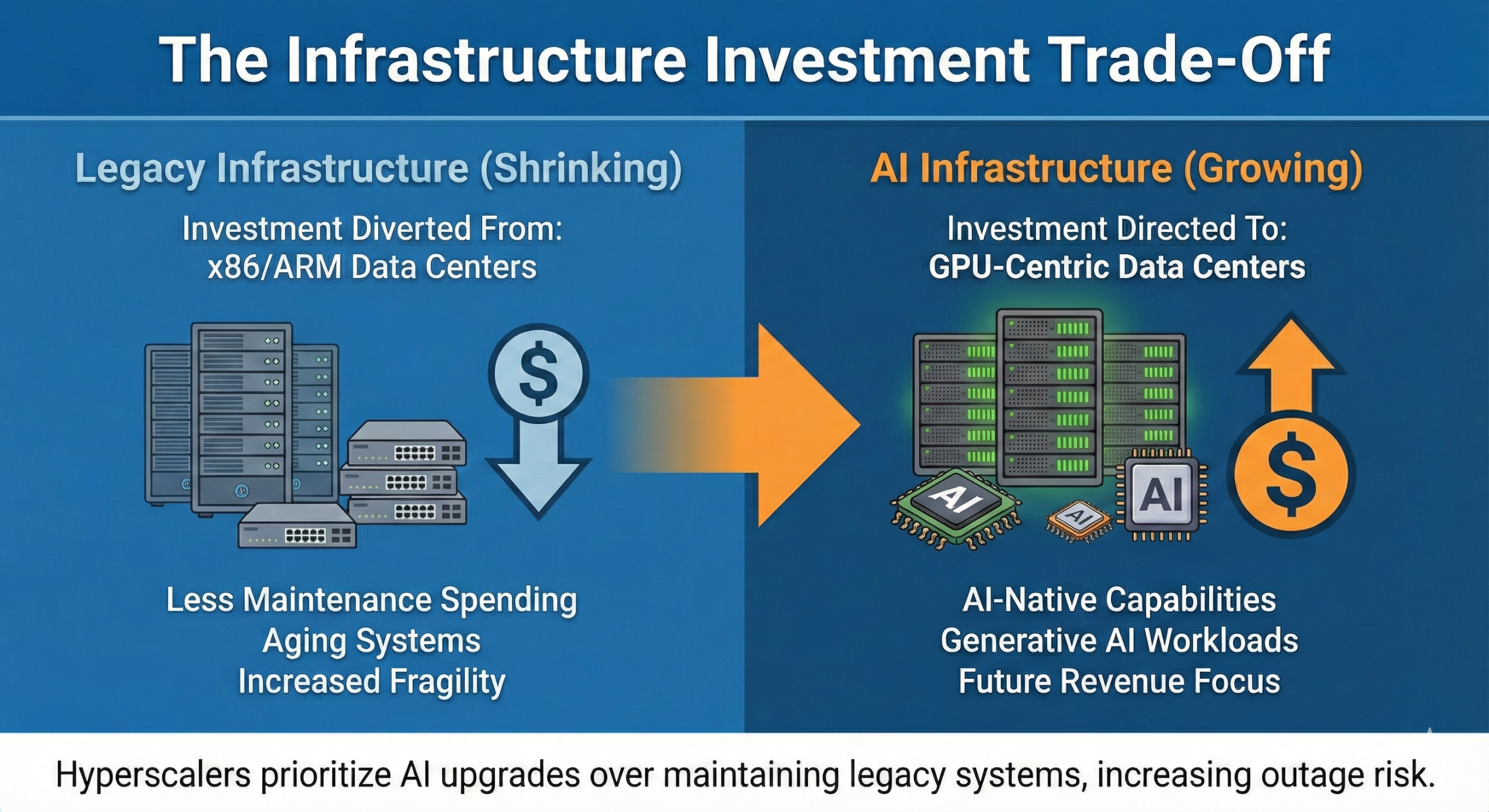
The reason? Hyperscalers are making a calculated trade-off. They’re diverting investment away from legacy x86 and ARM infrastructure to build GPU-centric data centers for AI workloads. Meanwhile, that aging infrastructure is faltering under growing complexity.
Why This Matters Now
If your business relies on hyperscaler infrastructure, you need to understand what’s driving these predictions.
The cloud’s promise was always-on infrastructure. But that promise took serious hits in 2025. AWS and Azure both suffered high-profile outages that disrupted critical services across industries and entire regions. (Read more: “How a tiny bug spiraled into a massive outage that took down the internet“, “Microsoft Azure outage triggers fresh calls for cloud competition reform“)
The 2025 incidents revealed a troubling pattern that complexity and dependencies make recovery slower and more painful. When core services fail, the cascading effects can take days to fully resolve.
Now Forrester is saying those problems will get worse before they get better.
The AI Investment Shift
Hyperscalers are in an arms race for AI dominance. They’re pouring hundreds of billions into GPU infrastructure, AI-native data centers, and generative AI capabilities.
That investment has to come from somewhere. And it seems to be coming at the expense of maintaining and upgrading the legacy infrastructure that runs most enterprise workloads today.
This creates a dangerous gap. Your production systems are running on infrastructure that’s getting less attention, less investment, and less maintenance while the hyperscalers focus on the next generation.
The result is infrastructure fragility at exactly the wrong time. As enterprises become more dependent on cloud services for critical operations, the infrastructure supporting those services is under more strain than ever.
What Enterprises Are Doing About It
The outage predictions are already changing behavior. Forrester reports that at least 15% of enterprises will seek private AI atop private clouds in 2026.
This is a specific response to AI workload concerns. The drivers include rising AI costs, data lock-in worries, and operational risk. Enterprises want control over their AI deployments and the corporate data that feeds them.
Some recent examples show this trend in action. Salesforce’s decision to shut down third-party access to the Slack API deprived customers of the ability to use their Slack data for workflow optimization on platforms other than Salesforce itself. That kind of vendor control makes enterprises nervous.
The complexity that hampered recovery from 2025 outages is forcing customers to address operational risks in their cloud strategies. And big cloud customers are starting to push back, pressuring providers to renovate their infrastructure to reduce operational risk.
The Neocloud Alternative
While hyperscalers deal with infrastructure fragility, a new category of providers is gaining ground.
Forrester predicts that “neoclouds” like CoreWeave, Lambda, and Nebius will grab $20 billion in revenue in 2026. These specialized providers focus on high-performance GPUs for AI workloads rather than trying to be everything to everyone.
Backed by NVIDIA and venture capital, neoclouds are expanding globally and integrating open source models, orchestration tools, and sovereign AI capabilities. They’re building GPU-first architecture from the ground up rather than retrofitting older data centers.
The growth is striking. Forrester expects tripled growth in enterprise neocloud deployments and regional expansions across Europe and Asia.
Building Resilience Into Your Infrastructure Strategy
If Forrester’s predictions come true, at least two major multi-day outages will hit hyperscaler infrastructure this year. That means businesses need to think differently about resilience.
Here’s what infrastructure leaders should be considering:
Reduce single points of failure. If your entire stack relies on one hyperscaler, you’re exposed. Diversifying infrastructure reduces the blast radius when outages occur.
Plan for extended recovery times. The 2025 outages showed that recovery isn’t quick when complex, interconnected systems fail. Your disaster recovery plans need to account for multi-day outages, not just hours.
Evaluate private infrastructure for critical workloads. The 15% of enterprises moving to private AI on private clouds aren’t doing it for fun. They’re making calculated decisions about where control and data sovereignty matter most for AI deployments.
Consider workload placement strategically. Not everything needs to be in the public cloud. Predictable, mission-critical workloads often perform better and more reliably on dedicated infrastructure.
Look at alternatives to hyperscalers. Neoclouds and private cloud providers offer options that weren’t viable a few years ago. The market has matured.
The Trade-Off Hyperscalers Are Making
It’s worth understanding why hyperscalers are making this choice.
AI infrastructure represents the future of cloud computing revenue. The companies that dominate AI compute will have massive competitive advantages. Missing that opportunity would be far more costly than dealing with some legacy infrastructure issues.
From a business perspective, the decision makes sense. From an enterprise customer perspective, it creates risk.
The question is whether you want your infrastructure strategy tied to that trade-off or whether you want more control over your own reliability.
What This Means for 2026 Planning
If you’re setting infrastructure strategy for 2026, the Forrester predictions should factor into your planning.
Budget for outage scenarios. Make sure your business continuity plans account for multi-day hyperscaler outages. Test those plans. Know what breaks and what keeps working when a hyperscaler goes down.
Evaluate infrastructure alternatives for your most critical systems. This doesn’t mean abandoning public cloud entirely. It means being strategic about what runs where.
Consider the total cost of downtime. If an outage costs your business millions per day, the economics of infrastructure diversity start looking very different.
And pay attention to operational risk, not just cost. The cheapest infrastructure isn’t a bargain if it’s unreliable when you need it most.
The Bigger Picture
Forrester’s predictions point to a broader shift in cloud computing. The era when hyperscalers could promise near-perfect uptime while also racing to dominate every emerging technology is ending.
Infrastructure fragility is becoming a competitive issue. Enterprises have options now that didn’t exist five years ago. Private cloud technology has matured. Neoclouds offer specialized capabilities. Bare metal providers deliver cloud-like experiences with better performance.
The infrastructure decisions you make in 2026 will determine how well you weather the outages Forrester is predicting. And more importantly, they’ll determine how much control you have over your own reliability and performance.
Two major multi-day outages might sound dramatic. But given what happened in 2025 and the investment priorities driving 2026, it’s a prediction worth taking seriously.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog