


































In this article
- Why Traditional Cloud Billing Breaks FinOps for AI
- The Real Cost of AI Budget Volatility
- How Fixed-Cost Infrastructure Changes AI Economics
- What Fixed Infrastructure Means for AI Workloads
- Building a Predictable FinOps Model for AI
- The OpenMetal Approach to AI Infrastructure
- Real-World Impact: AI Team Perspective
- When Fixed Infrastructure Makes Sense
- Making the Transition to Fixed-Cost AI Infrastructure
- Making FinOps for AI Workable
AI spending is spiraling out of control. Average monthly AI costs hit $85,521 in 2025, a staggering 36% jump from the previous year, according to CloudZero’s State of AI Costs report. Yet 94% of IT leaders report they’re still struggling to optimize these costs effectively, based on a 2025 study commissioned by Crayon.
The amount being spent matters, but the unpredictability creates even bigger problems. When your infrastructure bills fluctuate by 30-40% month-over-month based on usage patterns you can’t fully control, financial planning becomes impossible. Finance teams can’t forecast burn rates accurately. Boards lose confidence in projections. And funding rounds become harder to close when your unit economics look unstable.
This volatility stems directly from how hyperscalers bill for AI workloads: per-token for inference, per-GPU-hour for training, with complex tiering that changes as your usage scales. What starts as an acceptable monthly spend during experimentation suddenly doubles when you move to production. Then it doubles again when you add a new model or expand to a new region.
There’s a better approach. Fixed-cost infrastructure designed specifically for AI workloads eliminates billing volatility while maintaining the flexibility AI teams need. When you know exactly what your infrastructure will cost each month regardless of how many experiments you run or how many tokens you process, FinOps for AI becomes much simpler.
Why Traditional Cloud Billing Breaks FinOps for AI
AI workloads behave fundamentally differently from traditional application workloads, and hyperscaler billing models weren’t designed for this reality.
Training workloads are bursty and expensive. You might run intensive training jobs for days or weeks, consuming massive GPU resources, then have relatively quiet periods. Hyperscaler per-hour GPU billing means these spikes create unpredictable cost surges. A single training run that takes longer than expected can blow through your monthly budget.
Inference scales with business success. When your AI-powered feature gains traction, inference volumes can double or triple overnight. Per-token billing means your costs scale linearly with this success, exactly when you’re trying to demonstrate improving unit economics to investors. Microsoft’s Provisioned Throughput Units attempt to address this with reserved capacity, but they lock you into 1-year commitments with zero flexibility when your model architecture or requirements change.
Experimentation requires flexibility. AI teams need to test multiple approaches simultaneously to find the best configurations. Different model architectures, fine-tuning strategies, and performance benchmarks all require significant compute resources. Hyperscaler commitments like Provisioned Throughput Units lock you into specific usage patterns with no flexibility to shift workloads. If your research reveals that a different approach works better, you’re still paying for capacity configured for the old method. This rigidity slows innovation when AI development needs rapid iteration.
Experimentation gets expensive. AI teams need to run multiple experiments simultaneously to find optimal configurations. Testing different model sizes, comparing fine-tuning approaches, and benchmarking inference latency all consume resources. When every experiment shows up as a line item on your cloud bill, teams start self-censoring valuable research to avoid cost scrutiny.
The Real Cost of AI Budget Volatility
Unpredictable infrastructure costs create problems that extend far beyond the finance department.
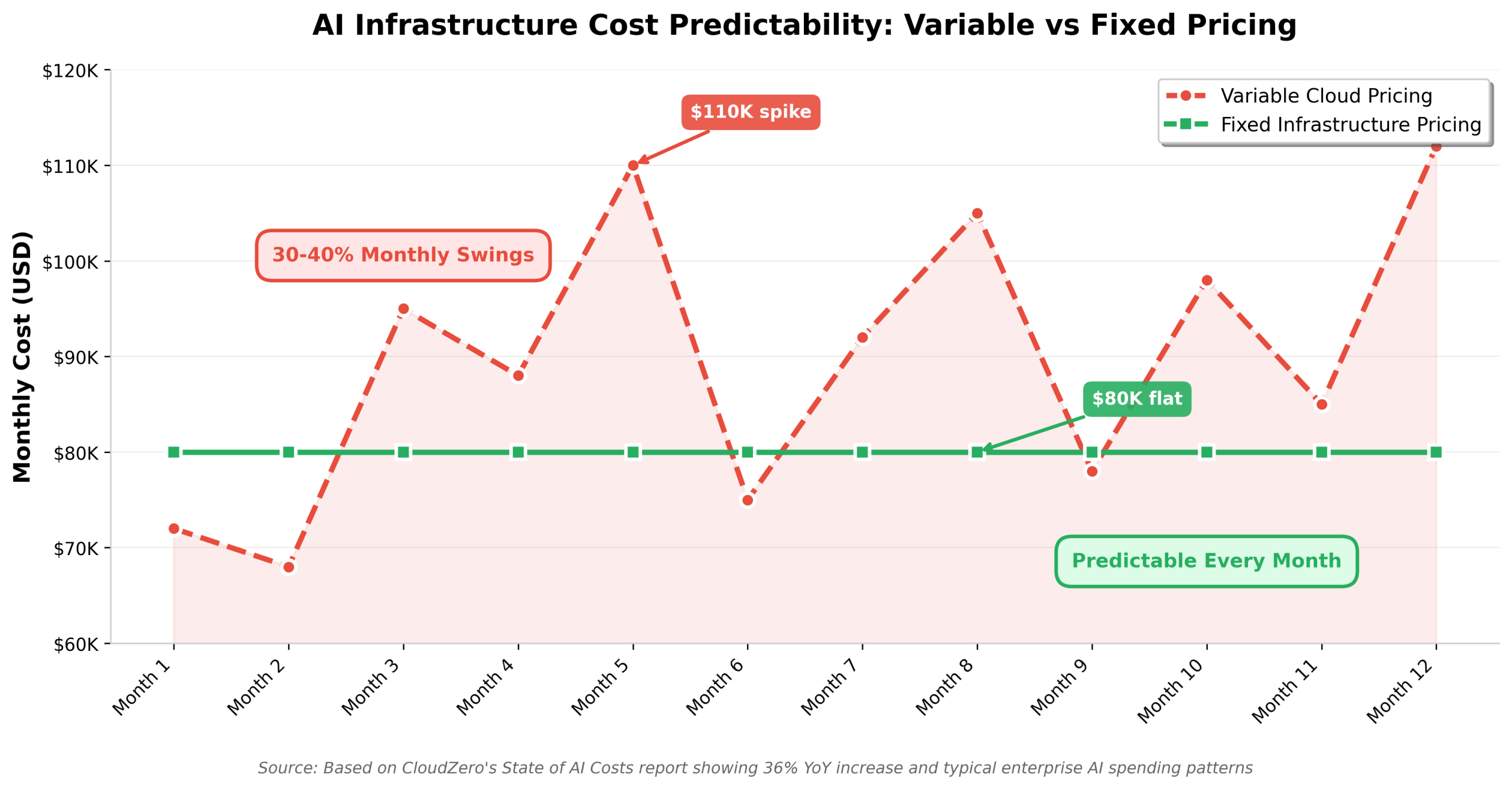
Finance can’t forecast accurately. When your monthly AI infrastructure costs swing between $60K and $110K with no clear pattern, creating reliable quarterly projections becomes guesswork. CFOs need predictable burn rates to manage runway effectively. Unpredictable costs force conservative assumptions that constrain growth, or optimistic projections that create budget overruns.
Engineering slows down. When every experiment might trigger a cost alert, engineers start asking for approval before trying new approaches. This approval overhead slows innovation velocity precisely when AI requires rapid iteration. The fastest way to kill an AI initiative is to make teams justify every GPU hour before they spin it up.
Unit economics look unstable. Investors and acquirers scrutinize unit economics closely. When your cost-per-prediction or cost-per-customer varies significantly month-to-month, it signals operational immaturity. Even if the underlying business is sound, variable infrastructure costs make your metrics look unpredictable. This directly impacts valuations and deal terms.
FinOps becomes reactive firefighting. Instead of strategic optimization, FinOps teams spend their time investigating unexpected spikes and explaining variance. “Why did GPU costs jump 40% this month?” becomes a recurring question that pulls attention away from architectural improvements and capacity planning. Reactive cost management means you’re always behind.
How Fixed-Cost Infrastructure Changes AI Economics
Fixed monthly pricing for dedicated AI infrastructure fundamentally changes how teams approach FinOps.
Predictable monthly costs enable accurate forecasting. When your infrastructure costs are fixed at $X per month regardless of how many training runs you execute or how many tokens you process, financial planning becomes straightforward. You know exactly what your quarterly spend will be. You can model growth scenarios with confidence. Finance can forecast burn rate accurately because the largest variable just became a constant.
Unlimited experimentation within capacity. With dedicated infrastructure, every experiment doesn’t generate a new cost. You can run 50 training experiments or 5 without changing your monthly bill. This removes the psychological and bureaucratic barriers to innovation. Engineers optimize for finding the best solution rather than minimizing usage. The result is faster iteration and better outcomes.
Success doesn’t punish unit economics. When your AI feature gains adoption and inference volumes triple, your infrastructure costs stay flat. This means your cost-per-prediction actually improves with scale, the way unit economics should work. Instead of infrastructure costs rising with revenue, they become a smaller percentage of each dollar earned. This predictable infrastructure cost model enables the financial stability late-stage companies need for fundraising and valuation.
Capacity planning becomes strategic. Rather than reacting to usage spikes, you plan infrastructure capacity based on business objectives. “We’ll need two additional GPU servers next quarter to support the product roadmap” is a strategic decision made during planning cycles, not an emergency response to a cost spike. FinOps teams can focus on right-sizing deployments rather than explaining variance.

What Fixed Infrastructure Means for AI Workloads
Dedicated infrastructure designed for AI provides specific advantages that directly address the challenges AI teams face.
Dedicated GPUs without noisy neighbors. When you provision an H100 or H200 GPU server, you get the entire physical server. No resource contention from other tenants. No performance throttling during peak hours. Training runs complete in predictable timeframes. Inference latency remains consistent. This performance predictability matters as much as cost predictability for production AI systems.
No per-token billing for inference. Deploy your models on your infrastructure and process unlimited inference requests. The marginal cost of each prediction approaches zero once you’ve provisioned the capacity. This fundamentally changes how you think about monetization. You can offer AI features more aggressively because incremental usage doesn’t create incremental costs.
Fixed egress and bandwidth. OpenMetal includes generous bandwidth allowances per server without the per-GB egress fees that hyperscalers impose. When you’re moving large datasets for training or serving model weights across regions, these bandwidth costs add up quickly on traditional clouds. Fixed bandwidth allocation means data movement costs are predictable and included in your base pricing. XL servers include 6 Gbps per server, with overage billing using 95th percentile measurement rather than total usage. This eliminates surprise bills from traffic spikes.
Flexible workload management. When your research direction changes or you want to test new approaches, you can repurpose your dedicated infrastructure across different workloads. The same GPU servers that run training jobs today can handle inference tomorrow, or support fine-tuning next week. You control how to allocate your capacity based on current priorities rather than being locked into predetermined usage patterns. This flexibility matches the iterative nature of AI development.
Building a Predictable FinOps Model for AI
Implementing fixed-cost infrastructure requires a different approach to capacity planning and cost management.
Start with baseline workload assessment. Analyze your current AI workloads to understand baseline requirements. How much GPU compute do your training pipelines consume monthly? What’s your steady-state inference volume? What experiments are planned for the next quarter? This baseline establishes the capacity you need to provision, similar to how you’d size database servers based on expected transaction volumes.
Provision for planned growth with headroom. Unlike variable cloud where you pay only for what you use, fixed infrastructure requires upfront capacity decisions. Provision enough capacity to handle your baseline plus expected growth. The financial benefit comes from utilization. When you’re running that capacity at 60-80% sustained usage, your effective cost per computation is dramatically lower than per-hour GPU pricing. Unused capacity provides value if it enables faster iteration.
Track utilization, not just spend. FinOps for fixed infrastructure focuses on utilization optimization rather than cost reduction. Are your GPUs running training jobs efficiently? Is inference capacity appropriately sized for demand patterns? High utilization means you’re maximizing the value of your fixed investment. Low utilization signals either overprovisioning or inefficient workload scheduling. Both represent optimization opportunities.
Use hybrid models strategically. Fixed infrastructure handles predictable baseline workloads. True burst scenarios like temporary projects, one-off experiments, or proof-of-concepts can still use variable cloud resources. The key is keeping your baseline, production-critical AI workloads on predictable infrastructure while maintaining flexibility for genuine unpredictable needs. Most organizations find their AI workloads are more predictable than they initially assumed.
The OpenMetal Approach to AI Infrastructure
OpenMetal’s dedicated bare metal infrastructure provides the foundation for predictable AI economics.
Enterprise-grade GPU servers. Deploy dedicated H100 or H200 GPU servers with complete isolation. No noisy neighbors affecting training performance. No throttling during peak hours. Each server includes dual 10 Gbps network links (20 Gbps total) for moving large datasets and model weights. Storage uses Micron 7450 MAX or 7500 MAX NVMe drives delivering sub-millisecond latency for data loading bottlenecks.
Fixed monthly pricing with transparent scaling. Each server has a fixed monthly cost based on hardware configuration, not usage. When you need additional capacity, add servers in ~20 minutes using OpenMetal’s automation. Scaling is transparent: each added server increases your monthly cost by a known amount. No surprise charges for bandwidth spikes, storage growth, or support escalations.
Integrated private cloud orchestration. OpenMetal’s hosted private cloud runs on OpenStack, providing APIs and tooling that AI teams already know. Deploy Kubernetes for ML workload orchestration. Use Ceph for distributed storage that handles large model weights and training datasets. Leverage neutron for network isolation between training, inference, and development environments. The entire stack deploys in approximately 45 seconds and scales with your needs.
Multi-region deployment without egress penalties. Run inference nodes in Los Angeles, Ashburn, Amsterdam, and Singapore to reduce latency for global users. OpenMetal’s private networking between your servers is unmetered. Moving model weights between regions or syncing training data costs nothing extra. Egress to external users uses generous included bandwidth (6 Gbps per XL server) with 95th percentile billing that smooths traffic spikes rather than charging for every byte.
Real-World Impact: AI Team Perspective
The shift from variable to fixed infrastructure pricing changes how AI teams operate day-to-day.
Experimentation accelerates. ML engineers stop worrying about cost implications of trying new approaches. Testing five different model architectures simultaneously doesn’t generate five separate cost conversations. Running hyperparameter sweeps overnight doesn’t require approval. The psychological friction disappears when experimentation is included in your fixed infrastructure cost rather than generating incremental charges.
Production deployments simplify. Moving models to production doesn’t require new cost analysis. Inference volume projections don’t need CFO approval because scaling within your provisioned capacity is already budgeted. When your AI feature launches, engineering focuses on performance and reliability rather than monitoring per-token costs. The financial anxiety that typically accompanies AI launches goes away.
Architecture decisions improve. Teams optimize for actual performance rather than minimizing cloud provider line items. Should you cache embeddings or recompute them? With per-token billing, you minimize API calls even if it adds complexity. With fixed infrastructure, you make the architecturally correct decision: caching improves latency and reduces compute load, so you cache aggressively. Better technical decisions happen when cost structure aligns with engineering best practices.
Data engineering becomes practical. Large-scale data preprocessing, feature engineering pipelines, and dataset augmentation all require moving significant data volumes and running compute-intensive operations. These foundational AI tasks are expensive on variable clouds because they don’t directly generate revenue but consume substantial resources. Fixed infrastructure makes proper data engineering economically viable. You build the foundation your models need without cost guilt.
When Fixed Infrastructure Makes Sense
Fixed-cost infrastructure isn’t right for every scenario. The economics work best in specific circumstances.
Established AI workloads with predictable baselines. If you’ve been running AI workloads for 6+ months, you understand baseline requirements. You know roughly how much GPU compute your training pipelines consume. You have inference volume patterns. This predictability makes capacity planning straightforward. Early-stage experimentation where usage patterns are completely unknown might benefit from variable pricing initially, but mature AI operations gain significant value from fixed costs.
Production AI features serving real users. Once your AI features are in production and generating business value, infrastructure should be predictable. Variable costs create financial risk precisely when your AI capabilities become revenue-critical. Fixed infrastructure provides the stability production systems need while maintaining cost predictability for financial planning. This is especially important when AI features are core to your product rather than experimental additions.
Teams running continuous training and fine-tuning. If you’re regularly training models on new data or fine-tuning based on production feedback, GPU utilization stays high. This makes fixed infrastructure highly cost-effective because you’re using the capacity you’re paying for. Teams that train models sporadically might find variable pricing more attractive, but continuous AI development operations benefit dramatically from dedicated resources.
Organizations prioritizing unit economics stability. Late-stage startups, PE-backed companies, and public companies all need predictable unit economics for financial reporting and valuation purposes. Variable infrastructure costs create EBITDA volatility that investors and acquirers discount. Fixed costs enable stable margin profiles and accurate financial projections which are critical factors in fundraising, M&A, and public market valuations.
Making the Transition to Fixed-Cost AI Infrastructure
Moving from variable cloud pricing to fixed infrastructure requires planning but delivers immediate benefits.
Assess your current baseline. Analyze 3-6 months of cloud bills to understand your AI workload patterns. What’s your minimum monthly spend? What percentage is GPU compute versus storage and networking? Where are the spikes and what causes them? This analysis reveals your predictable baseline, the foundation for fixed infrastructure sizing. Most organizations discover that 70-80% of their AI spending is actually quite predictable when examined over time.
Start with a proof of concept on fixed infrastructure. OpenMetal offers proof-of-concept programs that let you validate performance and economics before committing. Deploy a representative training workload. Run inference benchmarks. Measure actual utilization against your projections. This testing phase reveals whether fixed infrastructure will deliver the cost predictability and performance consistency you need. Most teams complete validation in 2-4 weeks.
Migrate baseline workloads first. Move your predictable, production AI workloads to fixed infrastructure while keeping experimental or highly variable workloads on traditional cloud initially. This hybrid approach captures the cost benefits where they’re largest while maintaining flexibility for genuinely unpredictable needs. As you gain confidence, you can expand the scope of what runs on fixed infrastructure based on actual utilization data.
Optimize utilization over time. With fixed infrastructure, optimization focuses on maximizing value from your capacity rather than minimizing spend. Identify idle GPU time and schedule additional experiments. Consolidate workloads to improve density. Implement better job scheduling to reduce queue times. These optimizations don’t reduce your monthly bill, but they increase the business value generated from that fixed investment. Your effective cost-per-computation improves continuously.
Making FinOps for AI Workable
The explosion in AI spending continues to accelerate. Gartner predicts that by 2029, 50% of cloud compute resources will be dedicated to AI workloads, up from less than 10% today. That five-fold increase means AI infrastructure costs will dominate cloud budgets across most industries.
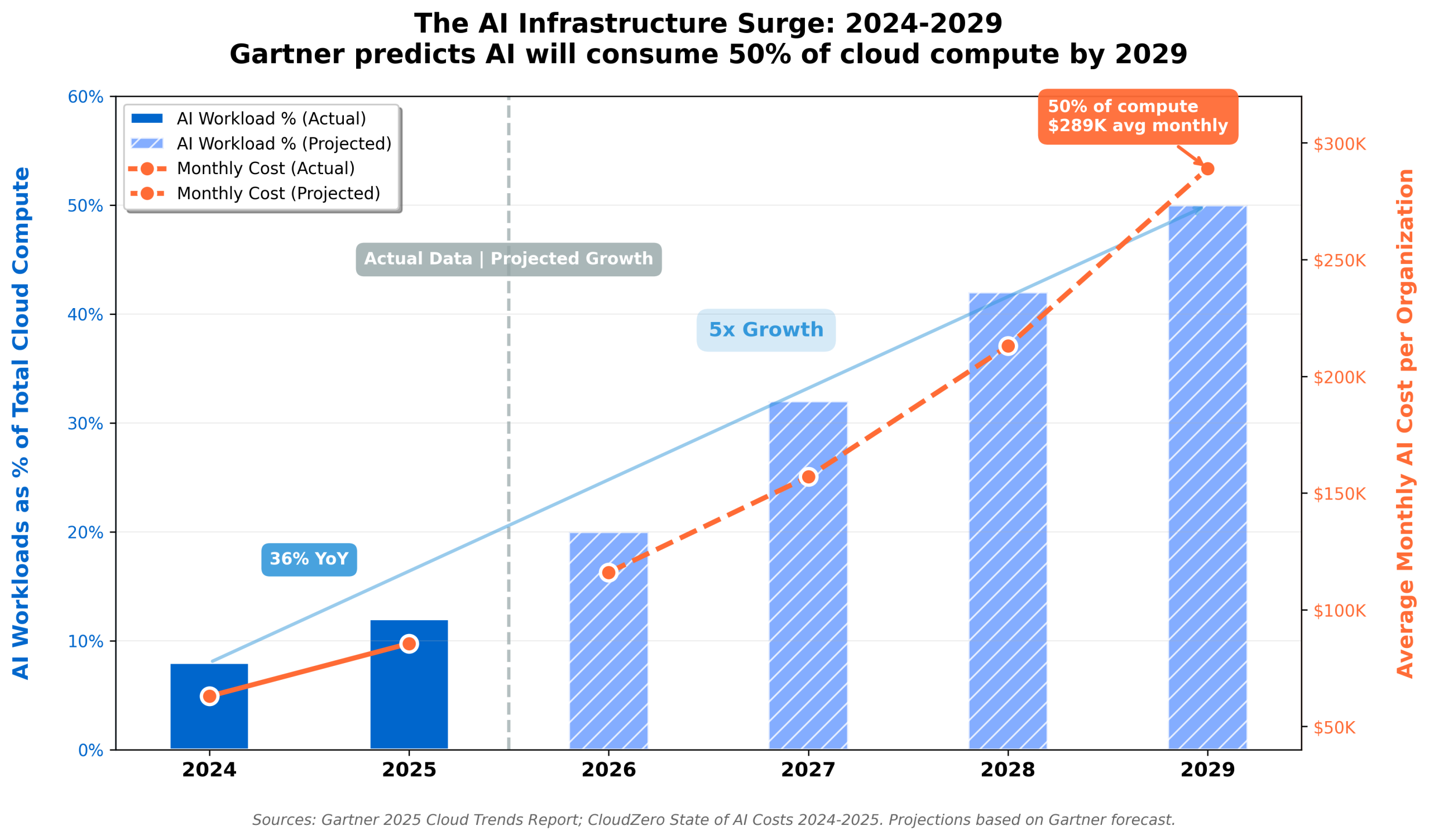
Managing this growth with variable pricing models that were designed for traditional application workloads creates unsustainable financial complexity. When monthly AI costs can swing by tens of thousands of dollars based on factors beyond your control, FinOps becomes reactive firefighting rather than strategic planning.
Fixed-cost infrastructure transforms this dynamic. Predictable monthly costs enable accurate forecasting. Dedicated resources eliminate performance variability. Unlimited experimentation within capacity accelerates innovation. And success improves unit economics rather than punishing them with rising costs.
For organizations running production AI workloads, managing continuous training pipelines, or building AI-powered products, fixed infrastructure provides strategic advantages. It aligns infrastructure economics with business goals: predictable costs, consistent performance, and the flexibility to innovate without financial anxiety.
OpenMetal’s bare metal infrastructure provides the foundation for this approach. Dedicated GPU servers, transparent monthly pricing, integrated OpenStack orchestration, and multi-region deployment without egress penalties combine to make FinOps for AI actually workable. When your infrastructure costs are predictable and your capacity is dedicated, AI teams can focus on what matters: building models that drive business value.
The AI infrastructure market is at an inflection point. Teams that establish predictable cost structures now will have competitive advantages in talent acquisition, financial planning, and sustainable scaling. As AI becomes more central to every business, infrastructure predictability becomes a strategic imperative rather than a finance department preference.
Ready to eliminate AI infrastructure cost volatility? OpenMetal’s proof-of-concept program lets you validate fixed-cost GPU infrastructure with your actual workloads. For startups, the StartUp eXcelerator Program provides up to $100,000 in cloud credits with predictable pricing that scales from MVP to IPO. Contact our team to discuss your AI infrastructure requirements and explore how predictable monthly costs can transform your FinOps approach.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog