



































Ready to explore bare metal for your AI or other continuous usage workloads?
OpenMetal’s infrastructure engineers can help you model the architecture for your specific requirements.
Production AI agent systems present infrastructure challenges that differ fundamentally from traditional web applications. Unlike simple request-response patterns, AI agents maintain stateful conversations, coordinate with peer agents, and query knowledge bases in real-time, all while delivering consistent low-latency responses across thousands of concurrent interactions.
This reference architecture examines a hypothetical enterprise customer service deployment: a fleet of 100+ specialized AI agents pair Elixir’s battle-tested concurrency model with OpenMetal’s XL v5 Bare Metal Dedicated Servers. While the scenario is illustrative, the architectural patterns apply broadly to production agent workloads.
Key Takeaways
- BEAM’s lightweight processes (2KB each) allow millions of concurrent conversations without thread overhead
- Bare metal dedicated servers eliminate “noisy neighbor” latency variability, critical for SLA compliance at p95/p99 percentiles
- Three of OpenMetal XL v5 nodes provide capacity for 5,000+ concurrent conversations with 60-70% headroom for growth
- Fixed-cost bare metal pricing can deliver 50-70% savings versus equivalent hyperscaler compute instances
Why Elixir and the BEAM for AI Agent Architectures
The Erlang BEAM virtual machine was designed for telecommunications systems requiring massive concurrency, fault tolerance, and distributed operation. These characteristics align remarkably well with AI agent requirements.
The Actor Model and Lightweight Processes
How many concurrent conversations can a single server handle? With BEAM, the answer might surprise you.
BEAM processes consume roughly 2KB of memory at creation and spawn in microseconds. A single BEAM node can sustain millions of concurrent processes. For AI agents, this means each customer conversation exists as its own isolated process—maintaining conversation state, managing context windows, and handling asynchronous LLM calls without blocking other conversations.
This contrasts sharply with thread-based concurrency models. Python’s Global Interpreter Lock complicates true parallelism, often requiring multiprocessing with inter-process communication overhead. BEAM sidesteps these limitations entirely.
Supervision Trees and Fault Tolerance
What happens when an agent crashes on unexpected input? With BEAM’s supervision model, that conversation restarts in a clean state while thousands of others continue uninterrupted.
BEAM’s “let it crash” philosophy proves particularly valuable for AI systems. Unpredictable inputs are common. Defensive programming cannot anticipate every failure mode. Supervision trees isolate failures and apply automatic restart strategies—exactly what production agent systems need.
Distribution and Hot Code Upgrades
BEAM clusters distribute processes across nodes with transparent message passing. Agents on different physical servers communicate as if co-located. This distribution isn’t an afterthought—it’s fundamental to the runtime’s design.
Hot code upgrades allow deploying new agent logic without dropping connections or losing conversation state. In a 24/7 operation handling thousands of conversations, zero-downtime updates represent significant operational value.
Latency Characteristics
BEAM’s preemptive scheduler ensures no single process monopolizes CPU time, preventing tail latency spikes common in cooperative scheduling environments. Garbage collection occurs per-process rather than globally, eliminating stop-the-world pauses that could violate response time SLAs.
Why Bare Metal Infrastructure Matters
Cloud instances provide convenience but introduce layers of abstraction between applications and hardware. For latency-sensitive, high-throughput AI agent workloads, these layers have measurable costs.
Performance Predictability
Have you ever investigated why your p99 latency spiked at 3 AM? On shared infrastructure, the answer is often “noisy neighbors.”
Bare metal eliminates this problem entirely. When an LLM integration call returns, the processing overhead to prepare a response is consistent—not variable based on what other tenants are doing on shared hardware. This predictability matters for meeting response time SLAs, especially at the 95th and 99thpercentiles.
Resource Control
Direct hardware access enables configurations unavailable in virtualized environments. NUMA-aware memory allocation ensures processes access local memory rather than traversing interconnects. NVMe drives can be configured with specific queue depths and I/O schedulers for your workload patterns.
Cost Efficiency at Scale
Cloud pricing includes margins for provider profit, infrastructure redundancy, and the flexibility premium. For steady-state workloads that run continuously—like a 24/7 agent fleet—bare metal typically costs 50-70% less than equivalent cloud instances.
The cost advantage compounds when considering the over-provisioning often required in cloud environments to accommodate performance variability. With predictable bare metal performance, you can right-size infrastructure more precisely.
Network Performance
Bare metal deployments on private networks achieve consistent low-latency, high-bandwidth interconnects. This matters for agent-to-agent collaboration, distributed cache access, and RAG query patterns where microseconds accumulate across multiple network hops.
Reference Scenario: Enterprise Customer Service Agent Fleet
| Dimension | Specification |
|---|---|
| Agent Count | 100+ specialized agents across support functions |
| Concurrent Conversations | 5,000+ at peak load |
| Conversations per Agent | 10-50 concurrent |
| Response Time SLA | Sub-500ms (95th percentile) |
| Availability | 24/7 operation |
| Compliance | Regulatory audit trails, data residency requirements |
Agents specialize by function: billing inquiries, technical troubleshooting, account management, returns processing, and escalation handling. They collaborate through message passing, sharing customer context when conversations transfer between specialists.
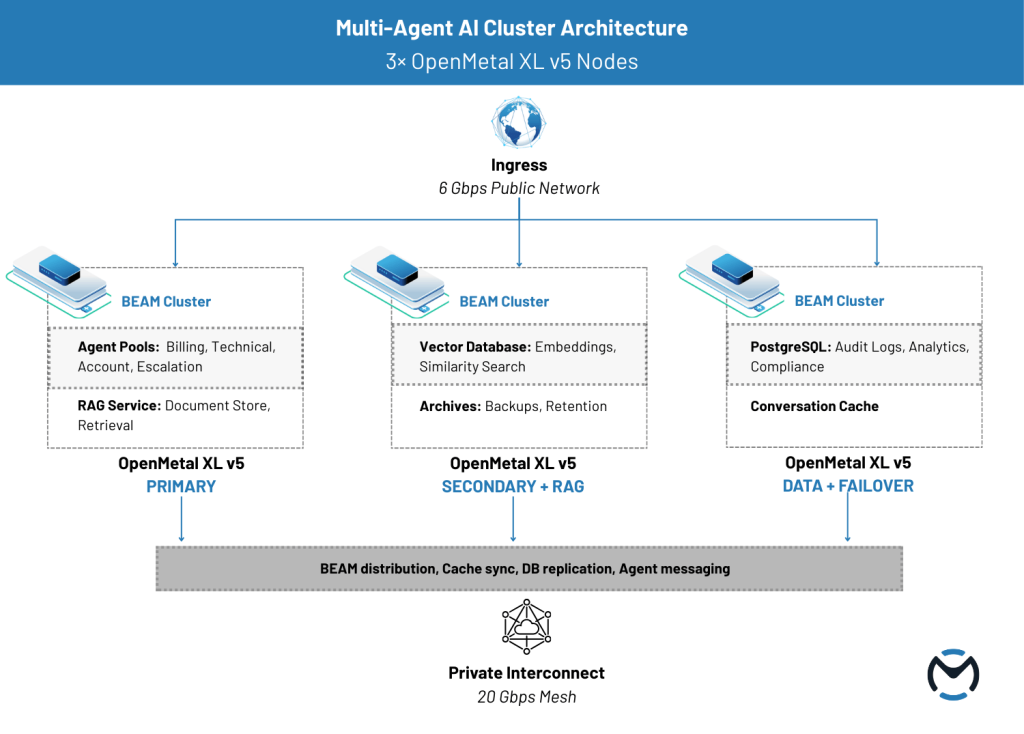
Three-Node Cluster Architecture
The architecture deploys across three OpenMetal XL v5 Bare Metal Servers, each providing substantial compute, memory, and storage resources.
Node Specifications
| Component | Specification |
|---|---|
| Processors | 2x Intel Xeon 6 6530P (64 cores / 128 threads total) |
| Memory | 1TB DDR5-6400 RAM |
| Storage | 4x 6.4TB Micron 7500 Max NVMe (25.6TB raw per node) |
| Network | 20Gbps private / 6Gbps public |
Cluster Topology
The three nodes serve distinct but overlapping roles:
- Node 1 (Primary Application): Runs the primary BEAM cluster handling agent processes and conversation management. Hosts the distributed cache for conversation state and customer context. Serves as the primary ingress point for customer traffic.
- Node 2 (Secondary Application + RAG): Participates in the BEAM cluster for agent process distribution. Hosts the vector database and embedding infrastructure for RAG capabilities. Handles knowledge base queries and document retrieval.
- Node 3 (Data + Failover): Runs PostgreSQL for persistent conversation logs and audit trails. Hosts backup BEAM node for failover scenarios. Manages long-term storage and compliance archives.
All three nodes participate in the BEAM cluster, allowing agent processes to distribute based on load. The role designations indicate primary responsibilities while maintaining flexibility for processes to run anywhere.
Architecture Diagram
Ready to explore bare metal for your AI or other continuous usage workloads? OpenMetal’s infrastructure engineers can help you model the architecture for your specific requirements.
Application Layer Architecture
Supervision Tree Design
The application structures around a hierarchical supervision tree. Each conversation spawns under a dynamic supervisor, isolating failures to individual interactions. Agent supervisors maintain pools sized to workload, with the ability to scale pools based on queue depth.
┌─────────────────────────────────────────────────────────────────────────────────┐ │ SUPERVISION TREE │ ├─────────────────────────────────────────────────────────────────────────────────┤ │ │ │ Application Supervisor │ │ ├── Cluster Manager ─────────────────── monitors node connectivity │ │ ├── Agent Pool Supervisor │ │ │ ├── Billing Agents ──────────────── N supervised processes │ │ │ ├── Technical Agents ────────────── N supervised processes │ │ │ ├── Account Agents ──────────────── N supervised processes │ │ │ └── Escalation Agents ───────────── N supervised processes │ │ ├── Conversation Manager │ │ │ └── Dynamic Supervisors ─────────── 1 per active conversation │ │ ├── RAG Service Supervisor │ │ │ ├── Embedding Workers ───────────── parallel embedding generation │ │ │ └── Vector Query Workers ────────── similarity search pool │ │ └── Integration Supervisor │ │ ├── LLM Client Pool ─────────────── managed connections to providers │ │ └── External API Clients ────────── third-party integrations │ │ │ └─────────────────────────────────────────────────────────────────────────────────┘
Conversation State Management
Conversation state lives in BEAM processes, with periodic checkpointing to a distributed cache (implemented via BEAM’s built-in distributed term storage or a library like Nebulex). This approach provides:
- Microsecond state access for active conversations
- Automatic failover if a node fails (state reconstructs from cache)
- Memory efficiency through process garbage collection
- Natural partitioning as conversations distribute across nodes
For conversations exceeding configured memory thresholds—those with extensive context windows—state pages to NVMe storage while maintaining hot paths in memory.
Agent Collaboration Patterns
Agents collaborate through typed message passing with defined protocols:
- Handoff Protocol: Transfers conversation ownership between specialists, including full context and summary
- Consultation Protocol: Agent queries a specialist without transferring ownership (e.g., billing agent asks technical agent about a product feature)
- Escalation Protocol: Prioritized routing to senior agents with urgency signaling
- Broadcast Protocol: System-wide notifications (policy changes, outage alerts)
BEAM’s location-transparent messaging means these protocols work identically whether agents reside on the same node or across the cluster.
LLM Integration Layer
LLM calls represent the primary latency component in agent responses. The integration layer implements:
- Connection pooling to LLM provider endpoints, maintaining warm connections
- Request batching where feasible, grouping multiple agent queries
- Timeout management with circuit breakers preventing cascade failures
- Response streaming to begin processing before full response arrival
- Multi-provider routing for redundancy and cost management
A dedicated process pool handles LLM calls asynchronously, allowing conversation processes to handle other work while awaiting responses.
Infrastructure Layer Configuration
Storage Allocation
The 25.6TB raw NVMe capacity per node allocates across workloads:
┌────────┬───────────────────────────────────────────────────────────────────────────┐ │ Node │ Allocation Strategy │ ├────────┼───────────────────────────────────────────────────────────────────────────┤ │ Node 1 │ 6TB conversation cache, 6TB agent state overflow, 12TB operational buffer │ ├────────┼───────────────────────────────────────────────────────────────────────────┤ │ Node 2 │ 12TB vector database, 6TB embedding cache, 6TB document store │ ├────────┼───────────────────────────────────────────────────────────────────────────┤ │ Node 3 │ 12TB PostgreSQL, 6TB WAL/backup, 6TB compliance archive │ └────────┴───────────────────────────────────────────────────────────────────────────┘
The Micron 7500 Max drives offer consistent low-latency performance for mixed read/write patterns typical of conversational AI—frequent small reads for context retrieval interspersed with writes for logging and state persistence.
Network Configuration
The 20Gbps private network forms the cluster interconnect:
- BEAM distribution traffic: Agent messaging, process migration, cluster coordination
- Cache synchronization: Distributed conversation state replication
- Database replication: PostgreSQL streaming replication for durability
- RAG queries: Vector similarity search and document retrieval
The 6Gbps public interface handles customer traffic with capacity well beyond the 5,000 concurrent conversation target, assuming typical message sizes.
Memory Allocation
The default 1TB RAM per node enables aggressive caching and large process counts:
| Component | Allocation |
|---|---|
| BEAM VM | 700GB (agent processes, conversation state, message queues) |
| Vector Database | 200GB (on Node 2 for hot index segments) |
| PostgreSQL | 200GB (on Node 3 for buffer cache) |
| Operating System | 24GB |
| Operational Buffer | Remainder for spikes and overhead |
The DDR5-6400 memory provides bandwidth for high-throughput access patterns, particularly important for RAG operations scanning large context windows.
Operational Considerations
Deployment Strategy
Blue-green deployment across the cluster enables zero-downtime updates:
- Deploy new version to standby node set
- Gradually migrate traffic using weighted routing
- Monitor error rates and latency during migration
- Complete cutover or rollback based on metrics
BEAM’s hot code upgrade capability allows behavioral updates without process restarts—useful for agent logic refinements that don’t require infrastructure changes.
Monitoring and Observability
Key metrics for agent system health:
- Conversation latency percentiles (p50, p95, p99)
- Agent process counts by type and node
- LLM call latency and error rates by provider
- Cache hit rates for conversation state and RAG queries
- Node resource utilization (CPU, memory, network, storage I/O)
- Message queue depths indicating backpressure
BEAM provides introspection capabilities for process-level monitoring without external agents, complemented by Prometheus metrics export for dashboarding.
Scaling Considerations
- Vertical headroom: The XL v5 specifications provide substantial capacity before horizontal scaling becomes necessary. The reference scenario utilizes perhaps 30-40% of cluster capacity, leaving significant room for growth.
- Horizontal expansion: Adding nodes to the BEAM cluster extends capacity linearly. New nodes join automatically through cluster discovery, and processes redistribute based on load.
- Burst handling: BEAM’s lightweight process model handles traffic spikes gracefully—spawning additional conversation processes costs microseconds and minimal memory.
Backup and Disaster Recovery
- Conversation state: Continuous replication across nodes with configurable consistency guarantees
- PostgreSQL: Streaming replication with automated failover, point-in-time recovery capability
- Vector database: Periodic snapshots to object storage, incremental backups for large indexes
- Compliance archives: Immutable storage with configurable retention policies
Recovery time objectives under 5 minutes are achievable for node failures, with the cluster continuing operation in degraded mode during recovery.
Cost Analysis
How does bare metal compare to hyperscaler alternatives for this workload? The numbers are compelling.
| Dimension | Bare Metal (3x XL v5) | Hyperscaler Equivalent |
|---|---|---|
| Instance Type | 3x OpenMetal XL v5 | 3x high-memory compute instances |
| Monthly Cost | Fixed bare metal rate | 3-4x bare metal cost |
| Annual Savings | Baseline | 50-70% premium over bare metal |
The calculation assumes:
- Reserved/committed pricing for hyperscaler (not on-demand)
- Equivalent core count, memory, and storage capacity
- Standard support tiers
Bare metal economics favor continuous workloads. The agent fleet runs 24/7 with predictable load patterns—exactly the profile where bare metal cost advantages are largest. Workloads with extreme variability or experimental phases may prefer cloud flexibility despite higher costs.
Performance Characteristics
Based on hardware specifications and documented BEAM characteristics, we can project expected behavior:
- Conversation latency: BEAM’s scheduling and garbage collection characteristics support sub-millisecond internal processing. The latency budget primarily goes to LLM calls, with infrastructure overhead in low single-digit milliseconds.
- Concurrent conversations: BEAM’s demonstrated ability to sustain millions of processes suggests the 5,000 conversation target represents modest utilization. Process memory overhead of approximately 10KB per conversation (including context buffers) totals under 50MB—trivial against 1TB available RAM.
- RAG query throughput: NVMe storage with 100K+ IOPS capability supports thousands of concurrent vector similarity searches. Memory-resident hot indexes further reduce query latency.
- Inter-node messaging: 20Gbps private network with sub-100μs latency enables agent collaboration patterns without perceivable delay.
Alternative Configurations
- Smaller deployments: A single XL v5 node can run the complete stack for development, staging, or smaller production workloads. The architecture simplifies without distribution complexity.
- GPU integration: For deployments running local LLM inference or embedding generation, GPU servers can join the cluster. BEAM processes communicate with GPU workloads through NIFs or external services.
- Storage expansion: The four NVMe slots per node accommodate larger drives as they become available. External storage arrays can extend capacity for compliance archives.
- Geographic distribution: BEAM clusters can span data centers with appropriate network configuration, enabling active-active deployments for latency-sensitive regional traffic.
Conclusion
The combination of Elixir on BEAM and bare metal dedicated server infrastructure offers a compelling architecture for production AI agent systems. BEAM’s concurrency model, fault tolerance, and distribution capabilities align with agent workload requirements. Bare metal provides the performance predictability, resource control, and cost efficiency that continuous AI operations demand.
This reference architecture demonstrates that meaningful alternatives exist to default technology choices. For engineering teams evaluating infrastructure for agent deployments, the Elixir + bare metal stack merits serious consideration alongside more conventional approaches.
Ready to explore bare metal for your AI or other continuous usage workloads? OpenMetal’s infrastructure engineers can help you model the architecture for your specific requirements.
More Posts about OpenMetal Hardware