


































In this article
Understand the core cloud native principles that matter (not just containers), why public cloud vendor lock-in violates cloud native principles, how OpenStack-based private cloud delivers true portability and automation, practical patterns for cloud native infrastructure that works anywhere, and why OpenMetal’s architecture is more cloud native than AWS.
Your engineering team just finished migrating everything to Kubernetes. Containers are running, pods are scaling, and everyone feels pretty good about being “cloud native”. Then someone asks: “But can we move these workloads to a different cloud provider if we need to?” Silence. Your Kubernetes manifests reference dozens of AWS-specific services. EBS volumes, ALBs, IAM roles for service accounts. Moving would mean rewriting half your infrastructure code.
This is the cloud native paradox. Teams adopt containers and microservices thinking they’re getting portability, but end up more locked in than before. The problem isn’t Kubernetes or containers. The problem is confusing cloud native with cloud provider services.
Real cloud native architecture means your applications can run anywhere without vendor-specific dependencies. It means infrastructure that gives you control instead of imposing constraints. It means private cloud can actually be more cloud native than public cloud.
This guide breaks down what cloud native really means beyond the buzzwords, why infrastructure choices determine your ability to achieve it, and how private cloud architecture enables true cloud native principles better than hyperscalers do.
What Cloud Native Actually Means
The Cloud Native Computing Foundation defines cloud native as technologies that “empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds”. Notice it says “public, private, and hybrid clouds”. Cloud native doesn’t mean public cloud only.
Three principles define cloud native architecture:
Portable: Applications run consistently across different environments without modification. A containerized application should work the same on your laptop, in your data center, on AWS, or on private cloud infrastructure. Portability means you’re not locked into specific vendor services or proprietary APIs.
Observable: You can understand system behavior through logging, metrics, and tracing. Cloud native systems generate telemetry data that helps you debug issues, optimize performance, and understand user behavior. Observability is built in, not bolted on after problems occur.
Automatable: Infrastructure and application deployment happens through code and APIs. You declare desired state, and automation tools make it happen. Manual configuration and click-through wizards are incompatible with cloud native principles.
These principles enable the outcomes organizations actually want: faster deployment cycles, better resource utilization, improved reliability, and reduced operational toil. But you don’t achieve these outcomes just by running containers. You achieve them by building on infrastructure that supports cloud native principles instead of fighting against them.
The Container Fallacy
Many teams believe that containerizing applications automatically makes them cloud native. You package your application in Docker images, deploy to Kubernetes, and assume you’ve achieved portability. Then reality hits.
Your containers might be portable, but your infrastructure dependencies are not. Consider a typical application on AWS EKS:
- Load balancing through AWS ALB controller
- Storage through EBS CSI driver
- Secrets management through AWS Secrets Manager
- Monitoring through CloudWatch
- DNS through Route53
- Service mesh through AWS App Mesh
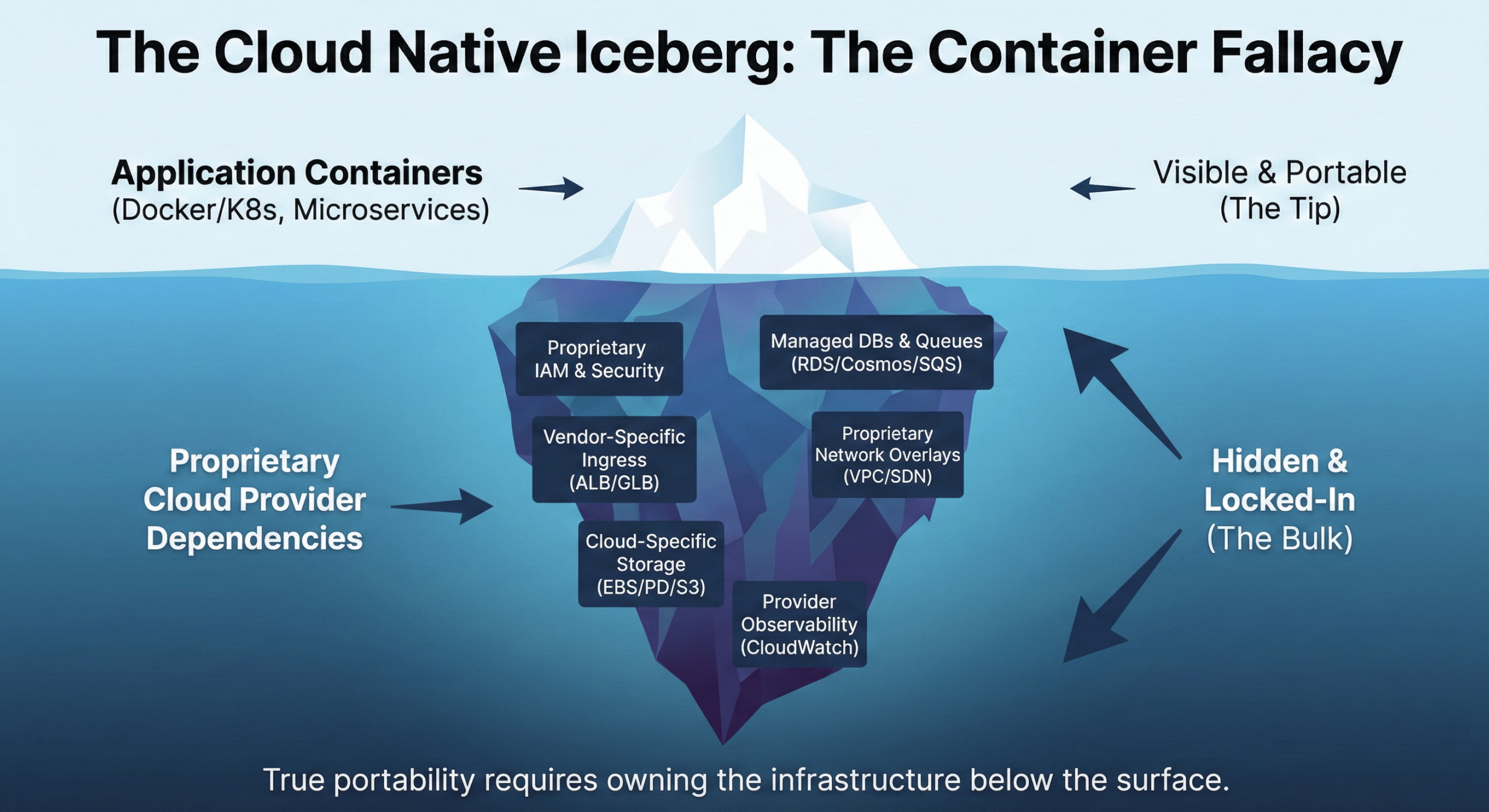
Each of these dependencies ties you to AWS. Moving to GCP or Azure means replacing every service with provider-specific equivalents. Your Kubernetes manifests become a mess of conditional logic and provider-specific configurations.
The problem gets worse with managed Kubernetes services. EKS, GKE, and AKS all implement Kubernetes differently. Node groups use different APIs. Ingress controllers work differently. IAM integration is completely different. You’re running the same container orchestrator but dealing with incompatible operational models.
True cloud native means infrastructure that doesn’t impose these constraints. OpenStack private cloud provides APIs that work the same whether you’re running in Virginia or Singapore, without provider-specific services creating lock-in.
Cloud Native Principle 1: Infrastructure Portability
Portability happens at multiple layers. Container portability is the easy part. Infrastructure portability is what separates truly cloud native architectures from vendor-locked implementations.
API Standardization
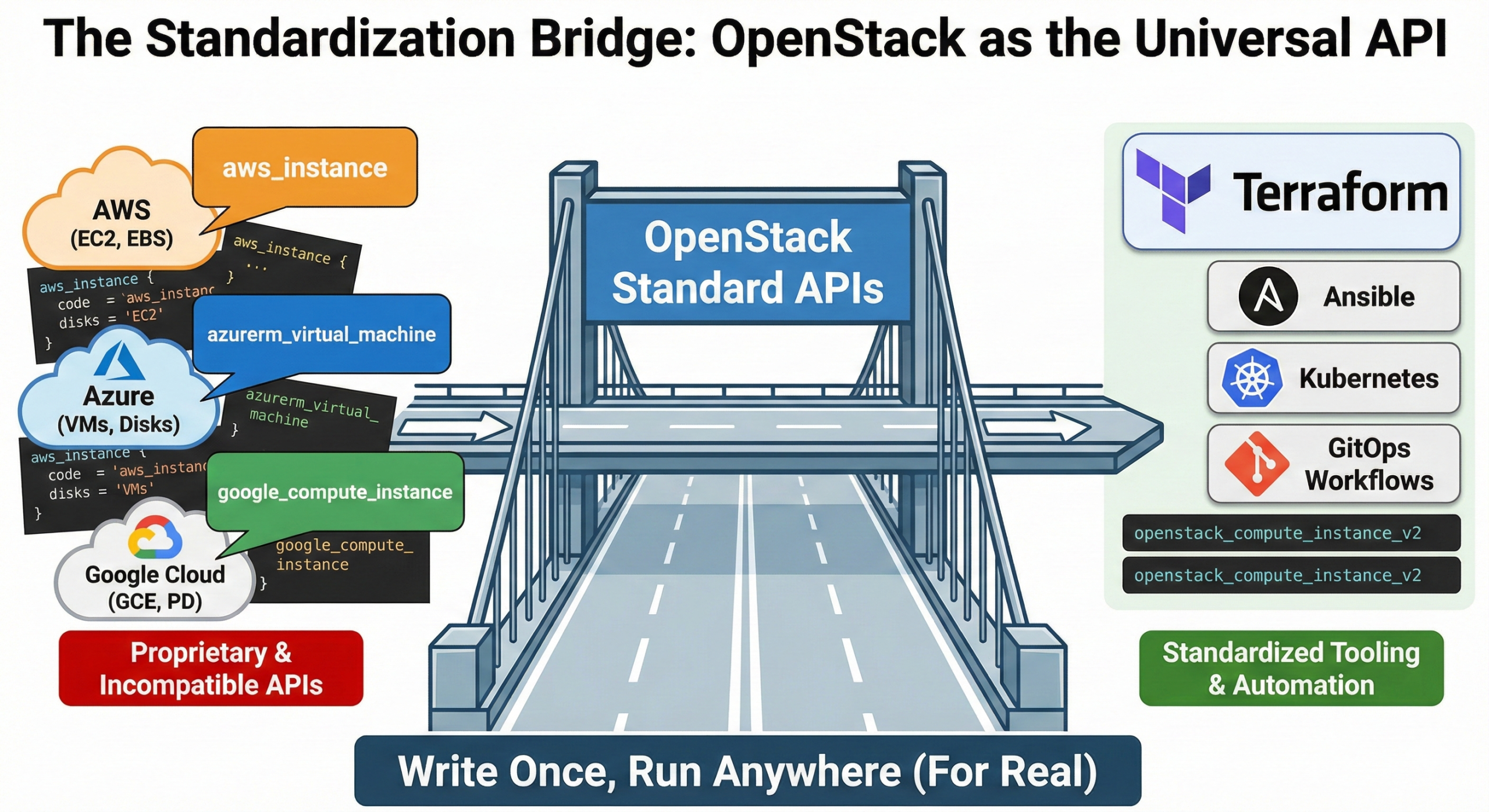
OpenStack provides standardized APIs for compute, storage, and networking. Nova manages virtual machines, Cinder manages block storage, Neutron manages networking. These APIs work identically across any OpenStack deployment.
Compare this to hyperscaler APIs. EC2, Azure VMs, and Google Compute Engine all provide virtual machines, but with completely different APIs, different instance types, different networking models, different storage options. Code written for EC2 doesn’t work on Azure without significant changes.
When you build on OpenStack, your infrastructure code is portable. Terraform modules work across any OpenStack cloud. Ansible playbooks don’t need provider-specific conditionals. Your operations team learns one API instead of three.
Storage Abstraction
Cloud native applications need persistent storage, but storage implementations vary dramatically across providers. EBS volumes, Azure Disks, and Google Persistent Disks all have different performance characteristics, snapshot mechanisms, and pricing models.
OpenStack Cinder provides consistent block storage abstraction. Your application requests a volume with specific size and performance requirements. Cinder handles provisioning from whatever backend storage you’ve configured (Ceph, LVM, or hardware arrays). Applications don’t care about storage implementation details.
This abstraction layer is essential for portability. When you move workloads between environments, storage semantics remain consistent. Performance characteristics might vary based on hardware, but API interactions stay identical.
Network Independence
Networking creates some of the worst lock-in on public clouds. VPC configurations, security groups, load balancer integrations, and DNS services all work differently across providers. Multi-region deployments compound these problems when networking assumptions differ by location.
OpenStack Neutron provides software-defined networking that abstracts physical infrastructure. You create networks, subnets, routers, and security groups through APIs that work identically everywhere. The underlying implementation might use VLANs, VXLAN overlays, or physical network devices, but applications see consistent behavior.
For Kubernetes deployments, this means CNI plugins work predictably. Calico, Cilium, or Flannel configure networking using Neutron’s APIs without provider-specific code. Your pod network configuration is portable because the underlying network primitives are standardized.
Cloud Native Principle 2: Declarative Infrastructure
Infrastructure as code is foundational to cloud native operations. You describe infrastructure in declarative configuration files, version those files in Git, and apply changes through automation pipelines.
But declarative infrastructure only works if the underlying platform supports it reliably. Hyperscalers have dozens of services, each with its own lifecycle and API quirks. Terraform providers for AWS, Azure, and GCP contain thousands of resources, each with unique behaviors and limitations.
Terraform at Scale
OpenStack’s smaller, more focused API surface makes Terraform implementations more maintainable. Instead of managing separate resources for VPCs, security groups, routing tables, NAT gateways, and internet gateways, you work with logical networks and routers.
# OpenStack network definition
resource "openstack_networking_network_v2" "app_network" {
name = "application"
admin_state_up = true
}
resource "openstack_networking_subnet_v2" "app_subnet" {
name = "application-subnet"
network_id = openstack_networking_network_v2.app_network.id
cidr = "10.0.1.0/24"
ip_version = 4
}
This code works on any OpenStack cloud. No provider-specific modules, no conditional logic for different cloud vendors, no dealing with VPC endpoint confusion. The same Terraform modules manage development, staging, and production environments across multiple data centers.
GitOps Workflows
GitOps workflows depend on predictable, idempotent infrastructure APIs. When you commit infrastructure changes to Git, automation tools apply them to your environment. This only works reliably when the infrastructure platform behaves consistently.
OpenStack’s stable APIs and predictable behavior make GitOps practical. Flux or ArgoCD can reconcile infrastructure state without surprises. Terraform plans produce expected outputs. Resource provisioning happens in predictable timeframes.
Public cloud services change constantly. APIs add parameters, default behaviors shift, and service integrations break. Your GitOps pipeline that worked last month fails today because AWS changed something. OpenStack’s commitment to API stability means infrastructure code keeps working.
Cloud Native Principle 3: Vendor Independence
Vendor lock-in happens gradually. You start with basic compute and storage. Then you add a managed database because it’s convenient. Then a message queue. Then a caching layer. Each decision makes sense individually, but collectively they bind you to one provider.
True cloud native architecture means you can change infrastructure providers when it makes business sense. Maybe costs increase. Maybe service quality degrades. Maybe you need capabilities the vendor doesn’t provide. Whatever the reason, you should be able to move.
The Cost of Lock-In
Public cloud pricing works great until it doesn’t. You optimize your instance types, use reserved instances, and negotiate enterprise agreements. Costs still climb because you’re locked in. The vendor knows switching is painful, so price increases stick.
Organizations running on private cloud infrastructure maintain negotiating leverage. You can move workloads between bare metal providers, colocation facilities, or even bring infrastructure in-house. This optionality keeps costs predictable.
Kubernetes on private cloud delivers 50-70% cost savings compared to EKS or GKE. Not because Kubernetes is cheaper (it’s the same software), but because the underlying infrastructure doesn’t include vendor premium pricing.
Compliance Flexibility
Regulatory requirements change. GDPR, HIPAA, PCI-DSS, and industry-specific regulations all impose infrastructure requirements. When you’re locked to a hyperscaler, you’re hoping they provide compliant services in regions you need.
Private cloud gives you infrastructure flexibility to meet any compliance requirement. You control data residency. You manage encryption keys. You configure network segmentation exactly as auditors require. No hoping the vendor adds features you need.
This flexibility is increasingly important as regulations tighten. Organizations facing strict compliance requirements find private cloud infrastructure is often the only viable option.
Why OpenStack Is More Cloud Native Than Public Cloud
OpenStack was designed as open infrastructure from the start. No single vendor controls it. No proprietary services create lock-in. The APIs are open standards that anyone can implement.
This architectural choice makes OpenStack inherently more cloud native than hyperscaler platforms:
Open APIs: OpenStack APIs are well-documented open standards. You can read the specifications, understand exactly how services work, and build integrations confidently. Hyperscaler APIs are proprietary black boxes that change without warning.
Implementation flexibility: Multiple vendors provide OpenStack clouds. You can run it yourself on any hardware. This implementation diversity proves the APIs are truly portable. Hyperscaler “portability” claims ring hollow when only one company can implement the APIs.
No proprietary services: OpenStack provides building blocks (compute, storage, networking) but doesn’t trap you with proprietary managed services. You bring your own databases, message queues, and application services. These run portably because they’re not tied to provider-specific integrations.
Community governance: OpenStack development happens through open technical committees. Anyone can participate in design decisions. Hyperscalers make unilateral decisions that prioritize their business model over user needs.
The Private Cloud Advantage
Private cloud architecture delivers infrastructure that truly supports cloud native principles. You get:
Predictable performance: Dedicated hardware means no noisy neighbors. Performance benchmarks you measure in development match production. Scaling characteristics are consistent.
Infrastructure control: Full root access to configure exactly what your applications need. Network architecture matches your security requirements without provider constraints.
Cost predictability: Fixed monthly costs instead of usage-based surprises. You can right-size infrastructure for actual workloads instead of over-provisioning to handle billing uncertainty.
Operational transparency: You see actual resource utilization, not abstracted metrics through provider dashboards. This transparency enables real optimization instead of guessing.
Practical Cloud Native Patterns on Private Cloud
Theory is nice, but how do you actually build cloud native applications on private cloud infrastructure?
Kubernetes Foundation
Start with Kubernetes as your application platform. OpenStack provides the infrastructure layer (compute, storage, networking) while Kubernetes handles application orchestration. This separation of concerns is cloud native architecture working correctly.
Deploy Kubernetes using standard tools like kubeadm, kops, or Cluster API. Avoid managed Kubernetes services that tie you to specific providers. Your Kubernetes clusters should be portable, and managed services sacrifice portability for convenience.
OpenStack’s Magnum project provides Kubernetes-as-a-Service if you want automated cluster management without giving up portability. Clusters created with Magnum use standard Kubernetes distributions, not proprietary forks.
Storage Patterns
Cloud native applications need persistent storage that works consistently across environments. Use Container Storage Interface (CSI) drivers that work with OpenStack Cinder.
For stateful applications like databases, Ceph provides distributed storage that scales horizontally. Applications see standard block, object, or file storage interfaces while Ceph handles replication and availability behind the scenes.
The key is avoiding proprietary storage services. RDS, DynamoDB, and CosmosDB might seem convenient, but they lock you in. Run PostgreSQL, MongoDB, or other open source databases on portable storage infrastructure instead.
Service Mesh Integration
Service meshes like Istio or Linkerd provide application-layer networking, security, and observability. They work identically on OpenStack as on any Kubernetes cluster.
This is where cloud native architecture shines. Your service mesh configuration is portable because it operates above the infrastructure layer. Security policies, traffic management rules, and observability configuration move between environments unchanged.
Contrast this with hyperscaler service meshes like AWS App Mesh that only work on AWS. Vendor-specific service meshes violate cloud native principles by tying application architecture to infrastructure provider.
Automation That Actually Works
Cloud native promises automated operations, but automation only works when infrastructure behaves predictably. Hyperscaler complexity creates automation challenges that private cloud avoids.
CI/CD Pipelines
Continuous integration and deployment pipelines need reliable infrastructure APIs. When you commit code, automated tests run in ephemeral environments. Passing tests trigger deployments to staging and production.
This workflow assumes you can provision test infrastructure quickly and reliably. OpenStack’s fast instance provisioning makes test environments practical. Spin up complete application stacks for testing, run your test suite, destroy everything. Repeat thousands of times daily.
Public cloud charges for every test environment. The cost of truly automated testing becomes prohibitive. Private cloud fixed costs mean testing doesn’t impact budget. You can test as much as needed for quality without worrying about cloud bills.
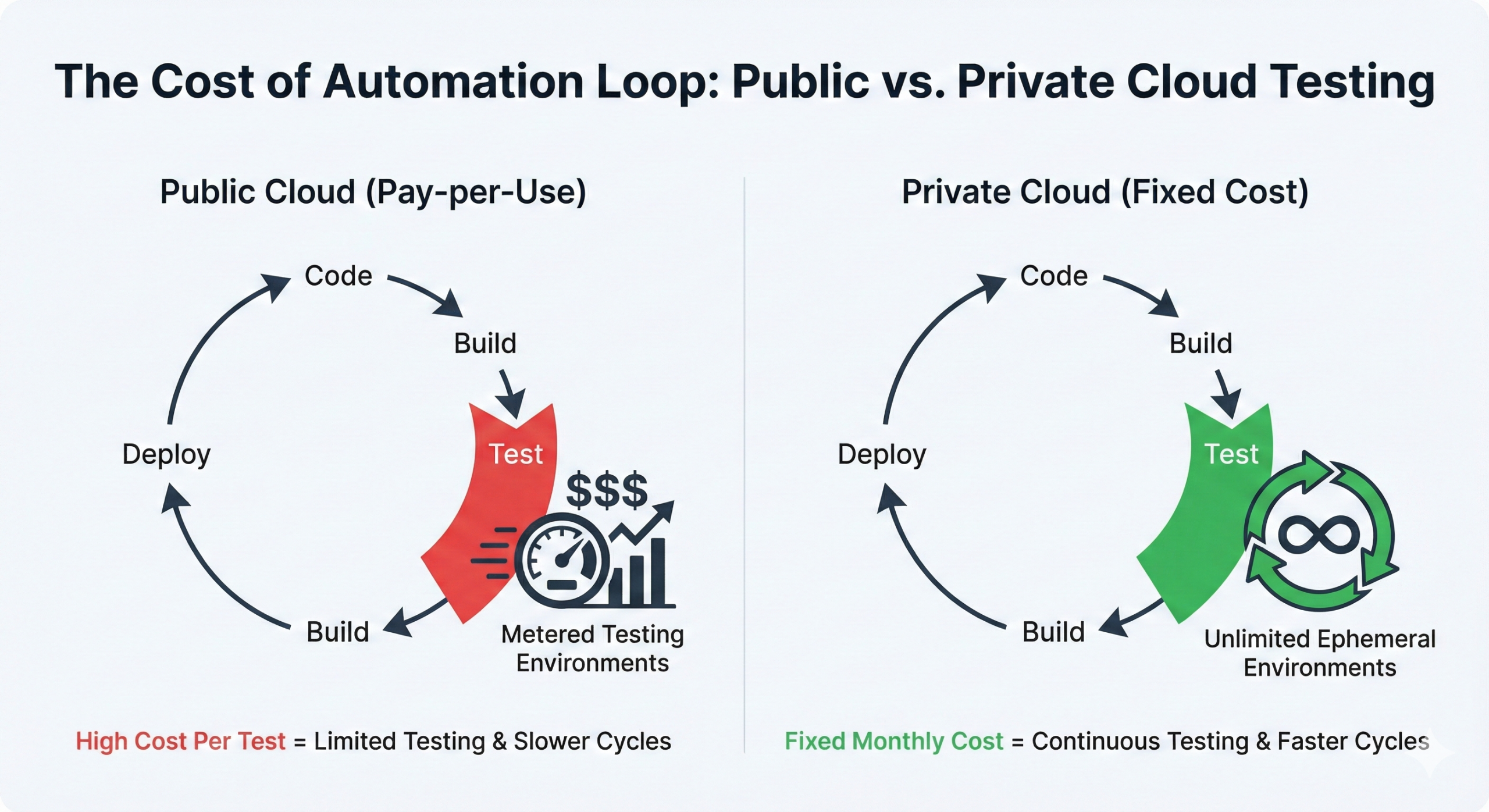
Infrastructure Testing
GitOps workflows require testing infrastructure changes before applying them to production. This means provisioning infrastructure, validating it works, then destroying it.
OpenStack’s API speed enables infrastructure testing patterns that are impractical on public cloud. Terraform changes get tested in throwaway environments in minutes. Failures are caught before affecting production. Successful changes deploy with confidence.
Observability Stack
Cloud native applications generate metrics, logs, and traces. Your observability stack needs to work identically across all environments so you have consistent insight into application behavior.
Open source observability tools (Prometheus, Grafana, Jaeger, FluentD) work great on OpenStack because they don’t depend on proprietary services. Deploy them the same way in development and production. Dashboards show the same metrics. Alerts use the same conditions.
Hyperscaler observability services (CloudWatch, Stackdriver) seem convenient until you need consistency across providers or between cloud and on-premises. Then you’re maintaining multiple telemetry pipelines and different dashboard tooling.
Common Objections to Private Cloud
Engineering teams sometimes resist private cloud because of misconceptions about operational complexity and capability limitations.
“Public Cloud Is Easier”
Public cloud marketing emphasizes ease of use. Click a few buttons, get a virtual machine. Seems simple compared to running your own infrastructure.
This simplicity is an illusion. Public cloud is only easy for hello world applications. Real systems need networking configuration, security policies, monitoring, cost management, and dozens of other concerns. Complexity doesn’t disappear; it just shifts from infrastructure to orchestration.
OpenMetal’s automated deployment makes private cloud as simple as public cloud. OpenStack clusters deploy in under a minute. You get working compute, storage, and networking without manual configuration. The difference is you get infrastructure that actually supports cloud native principles.
“We Need Managed Services”
Teams worry about operating databases, message queues, and other application services without managed offerings. This concern conflates convenience with capability.
Open source application services are mature and reliable. PostgreSQL, Redis, Kafka, and Elasticsearch work great when properly deployed. Kubernetes operators automate lifecycle management. You get the operational simplicity of managed services without the vendor lock-in.
The real question is whether convenience is worth permanent vendor lock-in. Short-term operational ease trades off against long-term architectural flexibility. Most organizations later regret managed service dependencies they can’t escape.
“Private Cloud Can’t Scale”
Another misconception is that private cloud limits scale. This is simply wrong. OpenStack clusters run hundreds of thousands of compute nodes at organizations like CERN, Walmart, and China Mobile.
Scaling private cloud just requires adding hardware. No artificial limits, no quota requests, no waiting for vendor approval. You scale horizontally by adding servers, exactly like cloud native architecture recommends.
The OpenMetal Difference
OpenMetal delivers private cloud infrastructure specifically designed for cloud native workloads. Here’s how our architecture embodies cloud native principles better than alternatives:
Instant deployment: Private cloud cores deploy in 45 seconds. This isn’t marketing hype. You get working OpenStack infrastructure with compute, Ceph storage, and software-defined networking before you finish your coffee. Fast provisioning enables the experimentation and iteration that cloud native development requires.
Standard APIs: Pure OpenStack APIs with no proprietary extensions. Your infrastructure code works on any OpenStack cloud. You’re not locked to OpenMetal. This API commitment is how we prove we’re actually cloud native.
Dedicated hardware: No noisy neighbors affecting performance. Benchmark numbers you measure during development match production. This consistency is essential for capacity planning and autoscaling.
Transparent pricing: Fixed monthly costs with no surprise charges. You can budget accurately for cloud native infrastructure instead of hoping your optimization efforts control costs.
Root access: Full control over your infrastructure. Configure exactly what your applications need. Install any tools. Implement any security model. Your infrastructure, your decisions.
Open architecture: Everything runs on OpenStack and Ceph. Both are open source projects with active communities. You’re never dependent on proprietary technology or vendor lock-in.
Getting Started with Cloud Native on Private Cloud
If you’re ready to build truly portable cloud native applications on infrastructure that supports rather than constrains you:
Start with a pilot project: Pick one application that’s causing public cloud pain. High costs, compliance challenges, or performance problems all work. Deploy it on private cloud infrastructure and measure the difference.
Audit vendor dependencies: Review your current architecture and list every proprietary service dependency. For each one, identify open source alternatives that work portably.
Build with open tools: Choose Kubernetes over EKS, PostgreSQL over RDS, Prometheus over CloudWatch. Slight increases in operational work deliver massive long-term benefits.
Automate everything: Use Terraform and GitOps workflows for infrastructure. Deploy applications with Helm or similar tooling. Make everything reproducible across environments.
Measure what matters: Track deployment frequency, lead time to production, and mean time to recovery. These metrics improve on infrastructure that enables cloud native practices rather than fighting them.
Real cloud native architecture means infrastructure that works for you instead of locking you in. Private cloud based on open standards delivers this better than hyperscaler platforms designed to maximize vendor revenue.
Ready to build cloud native applications on infrastructure that actually embodies cloud native principles? Explore OpenMetal’s hosted private cloud or contact us to discuss your cloud native infrastructure needs.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog