


































In this article
- What Exactly Is a Modern Data Lake? More Than Just Storage
- Why Open Source Data Lakes Make So Much Sense
- Inside an Open Source Data Lake: The Main Parts and Tools
- Blueprint for Success: Design Tips and Best Practices
- Navigating the Open Source Path and Dealing with Challenges
- Looking Ahead and What’s Next for Open Source Data Lakes
- Wrapping Up: Building Your Data Future on Open Foundations
- Get Started on OpenMetal for Your Big Data Project
We’re creating more data than ever before. At the same time, things like Artificial Intelligence (AI) and Machine Learning (ML) are changing how businesses use that data. This combination has completely changed the game for company data. To stay ahead, companies know they need to use all their data, not just some of it. That’s where the modern data lake comes in. It’s become a must-have piece of technology, much more than just a place to dump raw data.
What Exactly Is a Modern Data Lake? More Than Just Storage
Think of a modern data lake in 2025 as a smart, central system built to bring in, store, change, protect, and manage huge amounts of all kinds of data. It can handle neat, organized data from regular databases, messy data like text documents or videos, and everything in between like data from website clicks, phone sensors, or social media.
What really makes a modern data lake different from older systems, like traditional data warehouses, is something called “schema-on-read”. Old warehouses made you organize (define a schema for) your data before you could load it in (schema-on-write). Data lakes let you load data just as it is, in its original format. You only figure out the structure (apply a schema) when you actually need to use the data for analysis. This makes data lakes incredibly flexible. Data scientists and analysts can explore different kinds of data and try new ideas without being stuck with a structure decided long ago.
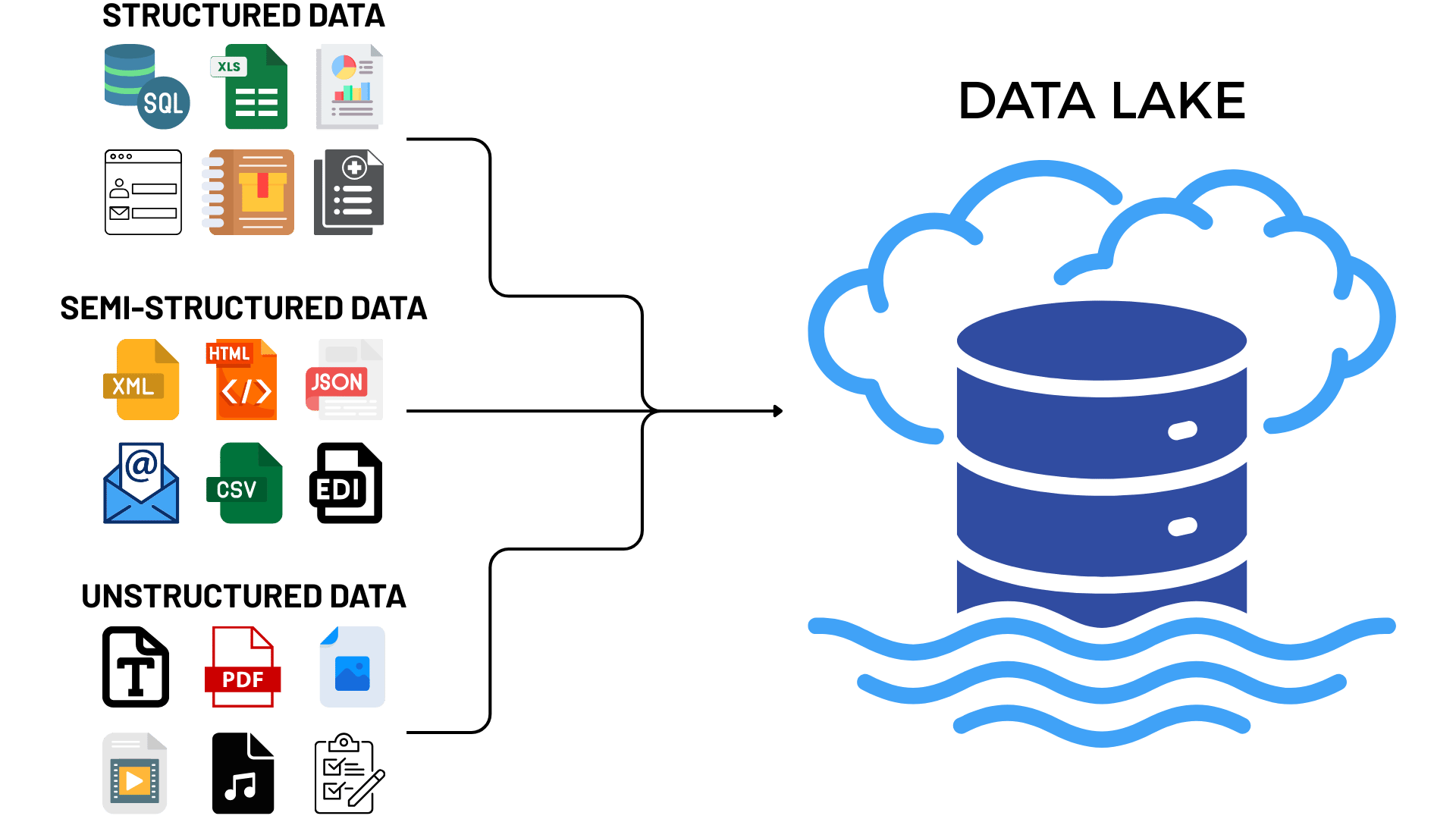
Data lakes have come a long way. Early versions sometimes became messy “data swamps” where good information got lost because there wasn’t enough organization or security. Today’s modern data lakes have strong controls, security, and automation built right in. Key features now include:
- One Central Place: Holds all data types, making storing and managing everything easy.
- Schema-on-Read: Flexible structure applied during analysis.
- Handles Everything: Works with organized, messy, and in-between data.
- Grows With You: Designed for huge amounts of data, often using flexible cloud systems.
- Saves Money: Uses standard computers or pay-as-you-go cloud storage.
- Built for Advanced Analysis: Great for ML, AI, and finding new patterns.
- Safe and Organized: Includes tools for finding data, managing details, tracking changes, controlling access, locking things down (encryption), and keeping records.
- Works Automatically: Can automate bringing data in, changing it, and keeping track of details.
Why Now? Big Data, AI, and the Need to Move Fast
Why are modern data lakes so important right now? First, the sheer amount and variety of data businesses create today is just too much for old database systems. Second, AI and ML need huge amounts of different kinds of data to learn effectively – often the raw, messy data that data lakes are perfect for storing. Traditional warehouses, which focus on organized reports, just can’t keep up.
Finally, businesses need to be quick. They need to add new data sources fast, try out new ways to analyze things, and get answers sooner. Old ways of preparing data (Extract, Transform, Load [ETL]) and rigid structures slow things down. Data lakes, being flexible, and allowing direct access to raw data, let teams move faster and adapt as the business changes.
Going All-In On Open Source
So, you need this powerful data platform. How do you build it? You could buy a ready-made solution from a specific company. But we think there’s a better way: building your modern data lake using open source tools. Open source means the software’s code is available for anyone to see, use, and improve.
There’s a huge collection of strong, proven open source tools for every part of a data lake. Choosing this path gives you big advantages in cost, flexibility, speed of new ideas, openness, and control over your company’s data future.
Why Open Source Data Lakes Make So Much Sense
Choosing open source tools for your data lake is a smart move with real benefits that go way beyond just saving money at the start. It gives you amazing flexibility, helps you innovate faster, and puts you in complete charge of your important data systems.
Saving Money: No Licensing Fees, No Being Locked In
The most obvious money saver with open source is that you don’t pay big fees for software licenses, which you often do with company-specific (proprietary) platforms. These costs can add up fast, especially as you store more data and do more with it. Open source tools often have very generous licenses (like the Apache 2.0 license) that make the total cost much lower and make it easier for companies of any size to get started.
But the real long-term win is avoiding “vendor lock-in”. When you buy a proprietary solution, you depend on that one company for everything – updates, fixes, help, and what comes next. This limits your choices, makes it hard to use tools from other companies, and leaves you open to price hikes or changes you don’t like. Trying to switch away from a proprietary system later can be incredibly difficult and expensive. Open source sets you free! You can pick, mix, and swap out tools based on what works best for you, keeping your options open and staying in control. Many of them also play nicely with proprietary tools, so if there are any that you do want (or have) to use, you can still do so.
Flexibility and Customization: Making It Fit Your Needs
Open source software lets you look at the code, change it, and add to it. This means you can shape your data lake exactly how your business needs it. If a feature is missing or needs tweaking, your team can build it or work with the open source community, instead of waiting for a vendor to maybe add it someday.
This flexibility also applies to the overall design. Unlike pre-packaged proprietary systems that might be good at some things but weak at others, open source lets you pick the very best tool for each job – bringing data in, storing it, processing it, querying it, managing it. This helps you build a data lake that’s perfectly tuned for your goals.
The common “schema-on-read” approach in open source tools adds even more flexibility, letting you look at the same raw data in different ways without expensive upfront changes.
Faster Innovation: The Power of the Community
The open source world moves fast because so many people work together. Projects run by groups like the Apache Software Foundation (ASF) or the Linux Foundation get ideas and code from developers, users, and companies all over the world. This team effort often leads to new features, faster bug fixes, and better connections between tools compared to a single company working alone. New ideas and technologies often get added more quickly. Plus, your company can join these communities, help shape the tools, add your own improvements, and learn from everyone else.
Openness and Control: Owning Your Data System
Open source is completely transparent. You can see the code, so you know exactly how your data lake tools work, how data gets processed, and how security is handled. No more “black boxes” where you can’t see inside, which builds trust and makes security checks easier. This openness gives you more control. You’re not stuck with a vendor’s plans, update schedules, or decisions to stop supporting a feature. You own your technology, so you can make your own choices about how it works, how secure it is, and where it goes next, making sure it always helps your business succeed.
Open Source vs. Proprietary Data Lake Comparison
| Feature | Open Source Approach | Proprietary Approach |
|---|---|---|
| Cost Model | Mostly running costs (computers, people); few or no license fees | License fees (often big and repeating) + running costs |
| Vendor Lock-In | Very little; free to switch tools/providers | High risk; depend on vendor for updates, help, future plans |
| Flexibility/Customization | High; can see and change the code to fit needs | Limited; usually stuck with what the vendor offers |
| Innovation Speed | Often faster because many people contribute | Depends on the vendor’s schedule and what they focus on |
| Transparency | High; code is open to look at and check | Low; often a “black box” with little view inside |
| Community Support | Strong; big forums, guides, shared knowledge (response time varies) | Usually just vendor guides/forums |
| Enterprise Support | Available from other companies or vendors supporting specific tools (costs money) | Included or sold as a service by the main vendor |
Inside an Open Source Data Lake: The Main Parts and Tools
Building a modern data lake with open source tools means putting together a team of specialized players, each handling a specific part of the data’s journey. While every setup is a bit different, they usually follow a pattern with layers or zones that help manage the data as it flows through.
How It’s Organized: Layers and Zones (Raw, Processed, Ready-to-Use)
A well-built data lake often uses layers to keep data organized as it goes from raw stuff to useful information. Common zones include:
- Raw Zone (or Landing/Bronze Zone): This is where all data first arrives. It’s stored exactly as it came in, untouched. This keeps the original copy safe and provides a record you can check. All data types (organized, messy, in-between) live here.
- Processed Zone (or Standardized/Cleaned/Silver Zone): Data from the Raw Zone gets its first cleanup here. It’s checked, fixed, organized, and maybe put into a standard format. Sometimes structure (schema) is added, and data is often saved in formats like Parquet or ORC that make querying faster. This zone has more trustworthy data ready for wider use.
- Curated Zone (or Application/Business-Ready/Gold Zone): Data here is polished even further. It’s often combined, added to, and shaped specifically for digital reports, business dashboards, and complex analysis. It’s highly organized, fast to query, and ready for business users and applications to use directly.
- Sandbox Zone: Think of this as an optional playground. Data scientists and analysts can experiment here, mixing curated data with outside information or building models without messing up the main zones.
This layered approach (sometimes called a “Medallion Architecture” ) adds structure, makes management easier, improves data quality step-by-step, and serves different user needs along the way.
A. Bringing Data In: The Front Door for All Data Types
The ingestion layer is like the front door, responsible for reliably collecting data from many different places. It needs to handle different formats, structures, and speeds (like big batches or continuous streams). Here are some popular open source tools involved:
- Apache NiFi: A powerful tool with a drag-and-drop visual interface for moving, changing, and managing data flows between systems. It’s great for handling different data types and protocols, can add extra info to data, and works for both batches and real-time streams. It also automatically tracks where data came from (provenance).
- Apache Kafka: A system built for handling fast, continuous streams of data, like website clicks, sensor readings, or application logs. It’s become a standard for high-speed, real-time data collection. Kafka is reliable (it copies data to prevent loss), handles huge amounts of data, and can grow easily. Its Kafka Connect feature helps link it to many common data sources and destinations.
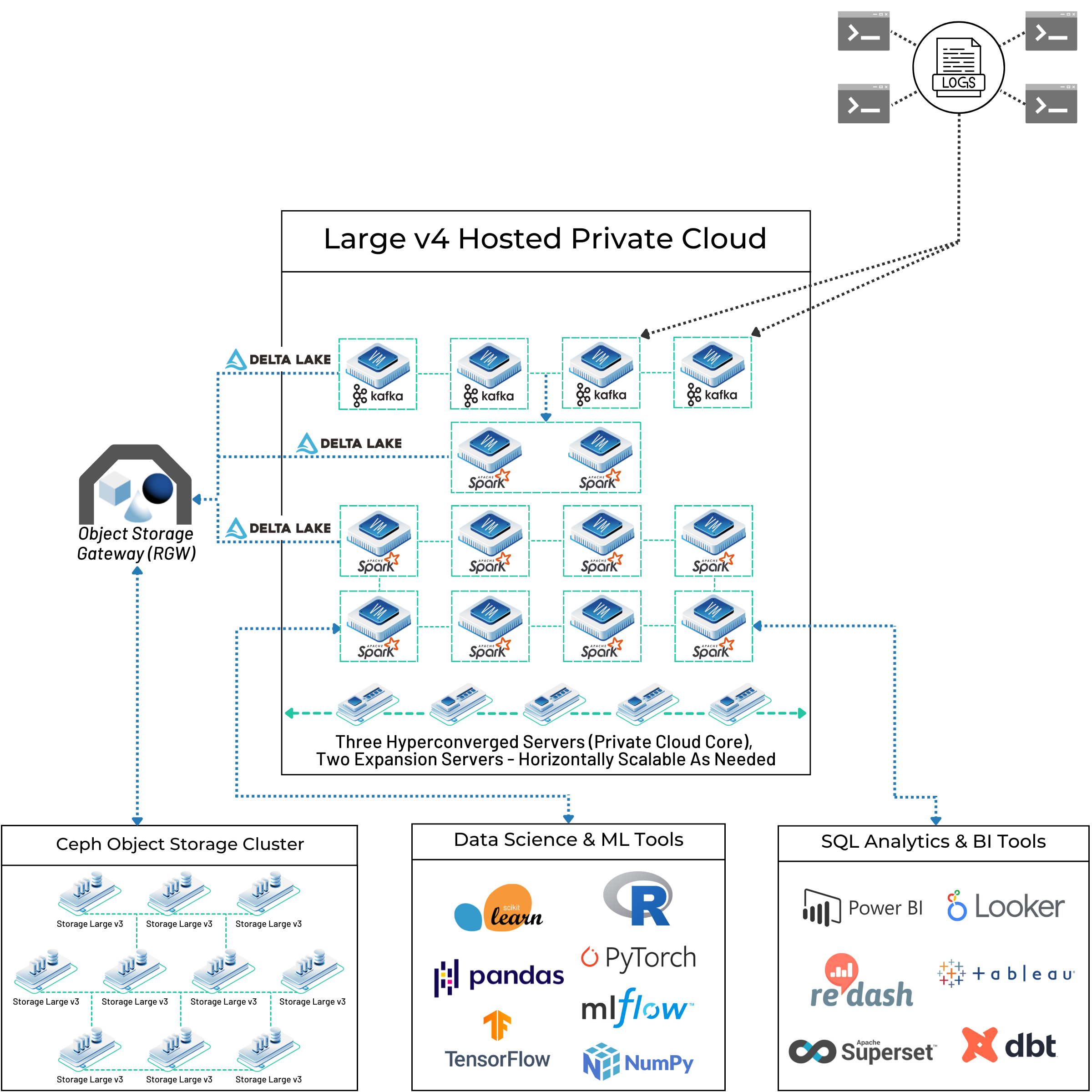
For capturing changes directly from databases in real-time, Kafka is often paired with Debezium. Debezium is an open source Change Data Capture (CDC) platform that monitors databases for any new entries, updates, or deletions at the row level. It then streams these changes as events to Kafka topics, allowing the data lake to stay synchronized with operational databases almost instantly. This combination is powerful for building event-driven architectures and ensuring the data lake has the freshest data for analysis. Kafka Connect plays a key role here, allowing Debezium connectors to source data and other sink connectors to deliver it from Kafka to the data lake. Our customers have been able to use Debezium and Kafka to build powerful ingestion capabilities in their big data pipelines – you can see one real world example in the diagram below. We’ll show you more pieces of this as we go and the full architecture layout for this setup later on!

- Fluentd: An open source tool focused on collecting log data. It gathers logs from many places, organizes them (often into a format called JSON), and sends them to destinations like data lake storage. It’s lightweight, flexible, and has many add-ons (plugins), making it popular, especially for systems using containers like Kubernetes.
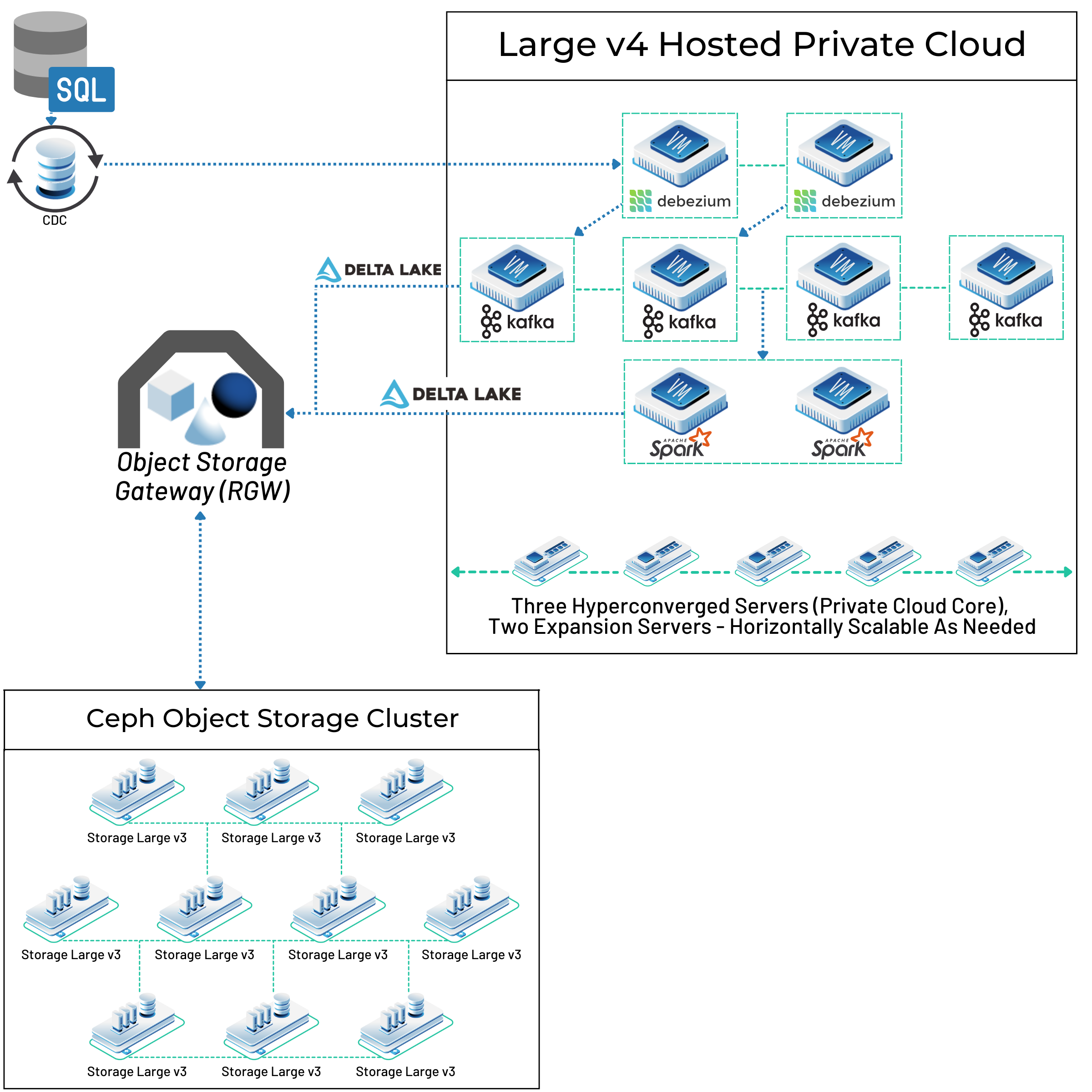
Choosing the right tool depends on where the data comes from (batch or stream? organized or messy?), what changes you need to make, and what systems you already have. Often, data lakes use a mix of these tools. Many of our customers have used Kafka in particular.
B. Storing the Data: A Scalable and Safe Foundation
The storage layer is the heart of the data lake. It needs to handle huge amounts of data, be very reliable, not cost too much, and work with different data formats. Open source offers great choices for both the storage system itself and the file types you use.
Storage Systems:
- HDFS (Hadoop Distributed File System): The original storage for Hadoop, HDFS is built to store huge amounts of data across many standard computers. It’s good at handling failures (by copying data blocks), moving large batches of data quickly, growing easily, and being cost-effective. However, it can be slower for quick lookups than other options and traditionally linked storage and computing together, though newer setups often separate them.
- MinIO: A fast, open source object storage system that works exactly like Amazon S3. This makes it great for building data lakes on your own computers or mixing your systems with the cloud, as applications designed for S3 will work with MinIO. MinIO is known for being very fast, making good use of modern computers, and is suitable for demanding tasks like AI/ML and analytics. It runs on standard hardware, saving money and allowing growth.
- Ceph: A flexible, software-based storage system that provides object, block (like a hard drive), and file storage all from one distributed system. Ceph can grow incredibly large (to exabytes), is reliable (using copying or clever encoding), and separates storage from specific hardware. Its versatility makes it good for cloud setups (like OpenStack), container storage (Kubernetes), and large data lakes needing different storage types. We build on and recommend Ceph here at OpenMetal and have seen it used successfully in many big data pipelines, like in the use case architecture we shared above.

File Formats:
Picking the right file format is key to saving storage space and making queries run faster.
- Apache Parquet: A very popular open source format that stores data by column instead of by row. When you query, the system only needs to read the columns you asked for, which saves a lot of time and makes analysis faster. Parquet also compresses data very well (because data in a column is usually similar) and handles complex data structures and changes to the structure over time. It consistently beats row-based formats like CSV for analysis in terms of space, speed, and cost.
- Apache ORC (Optimized Row Columnar): Another fast columnar format, first made for Apache Hive. ORC often compresses data even better than Parquet because of smart techniques and built-in indexes (like little tables of contents). These indexes help query tools skip reading data they don’t need, speeding things up, especially in Hive and Presto/Trino. It also handles complex data types.
- Apache Avro: A row-based format good for writing data quickly and sharing data between systems. Its main strength is handling changes to the data structure (schema evolution). The structure rules (schema, written in JSON) are usually stored with the data, so systems can easily handle things like new fields being added or old ones removed. Avro creates small binary files and works with many programming languages, making it great for sending records in streams (like with Kafka) or storing individual records efficiently.
Comparing Data Lake Storage Formats (Parquet, ORC, Avro)
| Feature | Apache Parquet | Apache ORC | Apache Avro |
|---|---|---|---|
| Storage Type | Column-based | Column-based (with row groups) | Row-based |
| Compression | High; good column compression | Very High; often better than Parquet due to smart techniques, indexes | Medium; small binary format, supports compression |
| Query Speed (Reading) | Excellent for analysis (reads only needed columns) | Excellent, often fastest for batches (Hive/Presto) due to indexes skipping data | Slower for analysis (reads full rows) |
| Query Speed (Writing) | Medium | Medium | Excellent for writing lots of data/serializing |
| Handling Structure Changes | Good; supports adding/removing columns, changing types | Good; supports structure changes | Excellent; structure stored with data, handles changes easily |
| Best For | General analysis, read-heavy tasks, Spark users | Data warehousing on Hadoop, Hive users, needing high compression | Sending data, Kafka messages, write-heavy tasks, changing structures |
C. Processing Data: Turning Raw Stuff Into Value
The processing layer is where the real work happens: raw data gets transformed, cleaned up, combined, and analyzed. Open source engines provide the power for these tasks.
- Apache Spark: A very popular engine for large-scale data work. Spark can handle batch processing, real-time streaming (Structured Streaming), SQL queries (Spark SQL), machine learning (MLlib), and graph analysis (GraphX). It’s known for speed, which comes from doing calculations in memory and having a smart execution plan. It works with many programming languages (Scala, Java, Python, R), making it usable by many people. Spark connects well with different storage systems (HDFS, S3, Delta Lake) and is a key part of many modern data lakes and lakehouses. Our customers building big data pipelines and lakehouses lean heavily on Spark to process data from multiple sources.
- Apache Flink: A powerful engine built specifically for processing continuous streams of data, especially when you need to keep track of information over time (stateful computations). Flink is excellent at very fast, real-time stream processing. It has advanced features like handling data that arrives out of order correctly (event-time processing), guaranteeing that each piece of data is processed exactly once (even if things fail), and managing complex state information reliably. While known for streaming, Flink can also handle batch jobs. It’s often picked over Spark Streaming when very low delay and complex tracking are needed.
- Apache Beam: A way to define data processing pipelines (both batch and streaming) using one standard model and set of tools (SDKs for Java, Python, Go). Beam’s big advantage is portability: a pipeline written with Beam can run on different processing engines (called “runners”) like Spark, Flink, Google Cloud Dataflow, and others. It hides the details of the specific engine, letting developers focus on the pipeline’s logic and avoid getting locked into one system.
Comparing Stream Processing Engines (Flink vs. Spark Streaming)
| Feature | Apache Flink | Apache Spark Streaming (Structured Streaming) |
|---|---|---|
| How it Processes | True Stream Processing (one event at a time) | Micro-batching (processes tiny batches) (Structured Streaming is closer to continuous) |
| Speed (Latency) | Very Low (milliseconds) | Low (seconds to sub-second) |
| Handling Out-of-Order Data | Excellent; built to handle late events correctly | Supported, but historically less mature than Flink’s |
| Tracking Info Over Time (State) | Strong and efficient; built for complex tracking | Supported; improved with Structured Streaming |
| Exactly-Once Guarantee | Strong support using checkpoints | Supported, often needs special connectors |
D. Data Catalog and Metadata: Finding and Understanding Your Data
As data lakes get bigger, you need tools to keep them organized and prevent them from becoming messy “data swamps”. Data catalogs help people find data, understand where it came from (lineage), know what it means for the business, and manage rules (governance).
- Apache Atlas: A detailed metadata and governance tool, especially good for systems in the Hadoop family. Atlas lets you create business dictionaries, label data (like “Personal Info” or “Sensitive”), and visually track data’s journey through tools like Hive and Kafka. Its big strength is working closely with Apache Ranger (a security tool) to set detailed security rules based on these labels.
- Amundsen (from Lyft): An open source data discovery tool focused on making it easy for people to find the data they need. It has a user-friendly search (like Google’s PageRank) that highlights popular and useful datasets. Amundsen shows both automatically gathered details (like usage stats) and information added by users (descriptions, tags). It also helps people collaborate by showing who uses data often. Its built-in governance features aren’t as deep as Atlas, and tracking data lineage often requires connecting to other tools like dbt.
- DataHub (from LinkedIn): A modern metadata platform designed for finding, watching, and governing data in today’s complex systems. DataHub uses a structured approach to defining metadata, updates details in near real-time using streaming (often via Kafka), and can work in a setup where different teams manage their own metadata – good for ideas like Data Mesh. It connects to many data sources and offers features like data profiling, lineage tracking, and support for data contracts.
E. Workflow Orchestration: Automating Complex Data Jobs
Data lake tasks often involve many steps using different tools that depend on each other. Workflow orchestrators automate the running, scheduling, watching, and handling of errors for these complex jobs (pipelines).
- Apache Airflow: A very popular and mature open source tool for defining, scheduling, and monitoring workflows using Python code. Workflows are set up as visual charts (Directed Acyclic Graphs or DAGs). Airflow has a huge number of connectors (providers and operators) for working with countless data sources, storage systems, and processing engines. Its flexibility, ability to grow, and good user interface for monitoring make it a standard choice for complex data jobs. Newer features like data-aware scheduling make it even better.
- Prefect: A modern, Python-friendly workflow tool focused on being reliable, easy to set up dynamically, and easy to watch. Prefect lets developers easily add scheduling, retries, logging, and caching to their existing Python code using simple commands (decorators). Its hybrid model separates the control part (Prefect Cloud or server) from the work part (where tasks actually run), giving flexibility and security. It supports workflows triggered by events and has a nice interface for monitoring.
- Dagster: An orchestration tool built around the idea of “data assets” – the actual things pipelines create (like tables, files, or models). Dagster focuses on the whole development process, offering strong tools for local development and testing, built-in tracking of data lineage and status, and ways to check data quality. Its clear, asset-focused approach aims to make data pipelines easier to understand, manage, and trust. It connects with many tools and cloud systems.
F. Querying and Analytics: Getting Answers from Your Data
Query engines are the tools users (analysts, data scientists, reporting tools) use to ask questions and get insights from the data lake. Open source offers several fast options that can handle different data formats and huge amounts of data.
- PrestoDB: A distributed SQL query engine built for fast, interactive, on-the-fly analysis across large datasets living in different places. Originally from Facebook, Presto uses connectors to query data where it sits (in HDFS, S3, databases, etc.) without moving it. Its parallel processing design and in-memory calculations allow for quick queries on petabytes of data.
- ClickHouse: An open source, column-oriented database management system (DBMS) built for extreme speed. While Presto and Trino are designed to query data where it lives (in your data lake files), ClickHouse is a high-performance analytical database that can ingest massive volumes of data (billions of rows per second) and make it available for real-time queries. It’s not uncommon to stream data from Kafka directly into ClickHouse for real-time dashboards and analytics, while also storing the raw data in a data lake (like Ceph with Iceberg or Delta Lake formats). In environments where ClickHouse complements operational systems such as SQL Server, teams often rely on dedicated SQL Server Management Tools to manage transactional workloads, schema changes, and query optimization, while using ClickHouse for high-speed analytical processing. Modern integrations even allow ClickHouse to directly query data from object storage and data lake table formats, making it a good tool for use cases that demand instant analytical results on massive, high-ingestion datasets.
- Trino (used to be PrestoSQL): A community-led project based on the original Presto, sharing the same goal: fast, distributed SQL queries across different data sources. Trino focuses on following the standard SQL rules, growing easily, and combining data from multiple sources in one query (federation). It’s widely used for interactive analysis, dashboards, and even some data preparation jobs directly on data lakes. It powers platforms like Starburst Galaxy and is an option in Amazon Athena.
- Apache Hive: Mainly a data warehouse system built for Hadoop, Hive provides a SQL-like way (HiveQL) to query large datasets. It turns HiveQL queries into batch jobs (using MapReduce, Tez, or Spark), making it good for large-scale processing and data preparation, but generally slower for quick, interactive questions compared to Presto/Trino or Impala. It relies heavily on the Hive Metastore to keep track of table structures and locations.
- Apache Impala: A parallel SQL query engine from Cloudera, designed for fast, interactive queries on data in Hadoop (HDFS, HBase) and cloud storage (S3, ADLS). Impala skips MapReduce and uses its own distributed engine, making it much faster than Hive for reporting and exploration within the Cloudera/Hadoop world. It uses the Hive Metastore but has its own way of running queries.
G. Governance and Security: Protecting Your Data
Making sure data is secure and following the rules (governance) is critical for any data lake, especially with so much potentially sensitive data stored there. Open source tools help manage this centrally.
- Apache Ranger: A full security system for the Hadoop world, offering central control over security rules, detailed permissions, and tracking (auditing). Ranger lets administrators set rules (based on users, groups, roles, or data labels from Atlas) for accessing things in HDFS, Hive, HBase, Kafka, and more. Rules can control access down to specific columns or rows, and Ranger can also hide (mask) sensitive data. Small plugins within each tool enforce these rules.
- Apache Knox Gateway: A gateway application that acts like a secure front door for accessing Hadoop services over the web (REST/HTTP). Knox makes security simpler by handling user login (authentication, connecting to systems like LDAP/AD), checking permissions (authorization), and logging activity centrally. It hides the internal cluster details and provides security at the edge. Knox works with Ranger to manage security rules.
H. The Lakehouse: Mixing the Best of Lakes and Warehouses
A big step forward is the “Data Lakehouse,” which tries to combine the flexibility and scale of data lakes with the reliability, speed, and control of data warehouses. This is mostly possible thanks to open table formats that add database-like features (like reliable transactions) on top of standard files (like Parquet) stored in cheap object storage.
- Delta Lake: An open source storage layer (started by Databricks) that adds reliable transactions (ACID), better handling of metadata, and data versioning (time travel) to data lakes using Parquet files. It uses a transaction log to keep track of changes and ensure data is trustworthy. Delta Lake supports checking and changing data structures (schema enforcement/evolution) and works smoothly with Apache Spark for both batch and streaming data. Its UniForm feature aims to make it work better with Iceberg and Hudi tools. Our customer’s big data pipeline uses Delta Lake to handle data from multiple sources before it gets passed along to the Ceph storage cluster.

- Apache Iceberg: An open table format built for huge datasets. It provides reliable transactions (ACID), handles schema changes well (tracking columns by unique IDs), allows changing how data is split (partition evolution) without rewriting everything, and supports time travel using snapshots. Iceberg uses a smart metadata structure to track data files (Parquet, ORC, Avro) efficiently, making queries faster by skipping irrelevant data. Its “hidden partitioning” makes querying simpler for users. Iceberg is designed to work with many query engines like Spark, Trino, Flink, and Hive.
- Apache Hudi: An open data lakehouse platform that adds features for processing data incrementally right on the data lake. Hudi supports fast updates and deletes using smart indexing methods and offers two main table types: Copy-on-Write (CoW) for read-heavy tasks and Merge-on-Read (MoR) for write-heavy, near real-time data loading. It provides reliable transactions (ACID), time travel, and built-in, automatic services for tasks like cleaning up, organizing, and indexing data, which reduces the work needed to maintain the tables.
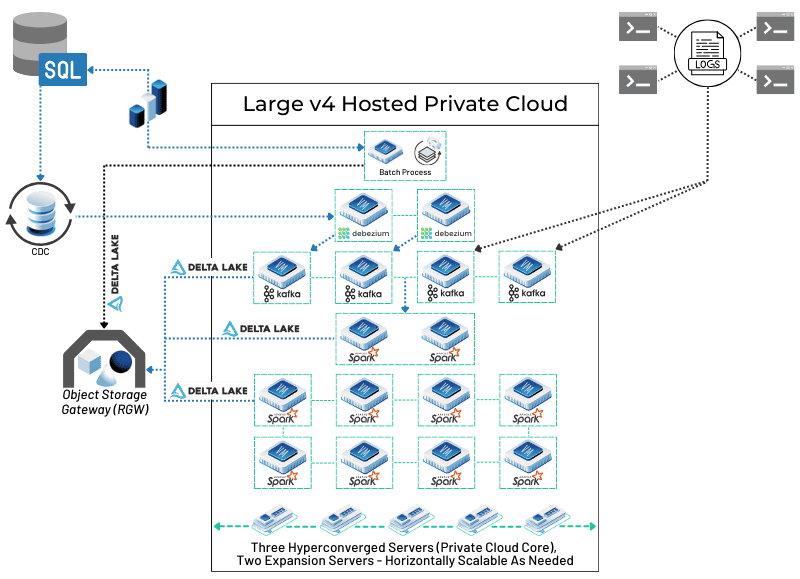
These table formats are a major improvement. They allow more reliable and faster analysis directly on the data lake, reducing the need for complex data pipelines to move data into separate data warehouses for structured queries and reporting.
Comparing Data Lakehouse Table Formats (Delta Lake, Iceberg, Hudi)
| Feature | Delta Lake | Apache Iceberg | Apache Hudi |
|---|---|---|---|
| Reliable Transactions (ACID) | Yes (uses transaction log) | Yes (uses atomic metadata changes) | Yes (uses commit timeline, controls access) |
| Time Travel (Query Old Data) | Yes (based on log versions) | Yes (based on snapshots) | Yes (based on commit timeline) |
| Schema Changes | Yes (add, reorder, rename, type change – some limits) | Yes (add, drop, rename, update, reorder columns via ID tracking) | Yes (compatible changes) |
| Partition Changes | Limited (needs data rewrite) | Yes (change partition rules without rewrite; hidden partitioning) | Limited (usually needs rewrite) |
| Handling Simultaneous Writes | Optimistic Concurrency Control | Optimistic Concurrency Control | Optimistic, supports MVCC, non-blocking options |
| Indexing (for speed) | Data Skipping, Z-Ordering (Databricks), Bloom Filters (OSS) | Min/Max stats for skipping files | Pluggable Indexing (Bloom, Hash, Record-level, Secondary) |
| Table Types (Write Modes) | Copy-on-Write (default) | Copy-on-Write (default) | Copy-on-Write (CoW) and Merge-on-Read (MoR) |
| Works Well With | Spark (native), Presto, Trino, Flink, Hive, Snowflake, BigQuery, Redshift | Spark, Trino, Flink, Presto, Hive | Spark, Flink, Presto, Trino, Hive, Impala |
| Unique Strengths | Great Spark connection, UniForm works with others | Strong schema/partition changes, works with many engines, good metadata focus | Incremental processing, fast updates/deletes, built-in table services, MoR option |
Blueprint for Success: Design Tips and Best Practices
Building and running a successful open source data lake is of course about more than just picking tools. You’ll need smart planning and good practices to make sure your lake is scalable, reliable, fast, well-managed, and actually useful.
Designing for Growth, Reliability, and Speed
- Scalability (Growing Easily): Your design must plan for more data later. Choose storage systems (like HDFS, Ceph, MinIO) that grow by adding more machines, and processing engines (Spark, Flink, Trino) that can spread work across flexible groups of computers (clusters). Separating storage from computing lets each grow on its own, saving money and resources.
- Reliability (Trustworthiness): Your data needs to be safe and always available. Use storage that copies data (like HDFS/Ceph) or is naturally durable (cloud storage). Use processing engines that can recover from errors (Spark can re-calculate lost work, Flink saves checkpoints). Use lakehouse formats that guarantee transactions (ACID in Delta Lake, Iceberg, Hudi). Make sure your automated workflows (in Airflow, Prefect, Dagster) handle errors and can retry tasks.
- Performance (Speed): Making things fast involves several tricks. Use good file formats (columnar like Parquet/ORC for analysis) and compression. Split your data smartly (partitioning) so queries don’t have to scan everything. Use built-in indexes in formats like ORC or lakehouse tables (Hudi, Delta) to find data faster. Keep frequently used data in memory (caching) using tools like Spark. Processing engines also try to optimize queries automatically.
Smart Data Organization: Partitioning and Zoning
An organized data lake is easier to use and performs better.
- Data Zoning: Using logical zones (like Raw, Processed, Curated) gives structure, tracks data origins, separates data by quality, and serves different users. It keeps end-users away from the raw, messy data, ensuring they use validated information from the curated zone.
- Partitioning: Splitting large datasets into smaller chunks based on common query filters (like date, region, department) is key for speed. Queries can then scan only the needed chunks. Choose partition keys based on how people usually query the data. But don’t overdo it – too many tiny partitions can slow things down. Lakehouse formats like Iceberg have advantages like “hidden partitioning,” which hides the physical layout from users and lets you change partitioning later without breaking queries or rewriting data.
Building in Governance and Security from Day One
Rules (governance) and security need to be part of the plan from the start.
- Data Governance: Set clear rules for data quality, how data is used, how long it’s kept, and compliance. Use data catalogs (Atlas, Amundsen, DataHub) to manage details (metadata), track data origins (lineage), add business meaning (tags, descriptions), and help people find data. Build data quality checks into your data pipelines.
- Security: Use multiple layers of security.
- Authentication: Check who users are (e.g., using Kerberos or company logins like LDAP/AD, maybe via Apache Knox).
- Authorization: Control what authenticated users can do using tools like Apache Ranger. Set up Role-Based Access Control (RBAC) and maybe rules based on data tags from a catalog like Atlas. Give users only the minimum access they need.
- Encryption: Protect data by scrambling it, both when it’s stored (in HDFS, Ceph, MinIO, cloud storage) and when it’s moving over the network. Manage the encryption keys securely.
- Auditing: Keep detailed logs of who accessed or changed data, for security checks and compliance reports.
- Perimeter Security: Use gateways like Apache Knox as a secure front door.
- Data Masking/Tokenization: Hide sensitive data when needed (like for testing or analysis by users who shouldn’t see the real details).
Why Monitoring and Observability Are Key
You need to constantly watch your open source data lake to keep it healthy, fast, and reliable. Observability means understanding why things are happening, which helps fix problems and make improvements.
- What to Watch: Keep track of data pipeline status (did they work? how long did they take?), data quality (is data complete? accurate? on time?), system resources (CPU, memory, disk, network use), query speed, and costs.
- Open Source Tools: People often use a mix of open source tools:
- Prometheus: Collects measurements (metrics) over time from applications and systems. It pulls data at set intervals.
- Grafana: Creates dashboards and visualizations from data collected by Prometheus (and other sources). You can see key metrics and set up alerts.
- ELK Stack (Elasticsearch, Logstash, Kibana): A popular set of tools for collecting, storing, and analyzing log files. Logstash gathers logs, Elasticsearch stores and indexes them for searching, and Kibana provides the interface to view and analyze them. This is vital for figuring out why pipelines failed or investigating security issues.
Good monitoring gives you early warnings, helps tune performance, checks data quality, and supports governance by tracking data use.
Comparing Open Source Monitoring Tools (Prometheus, Grafana, ELK)
| Prometheus | Grafana | ELK Stack (Elasticsearch, Logstash, Kibana) | |
|---|---|---|---|
| Main Job | Collects measurements (metrics) and sends alerts | Shows data visually, makes dashboards and sends alerts | Gathers, stores, searches & shows log files |
| How it Gets Data | Pulls data from monitored systems | Connects to data sources (like Prometheus, Elasticsearch) | Pushes data using agents (Logstash/Beats) |
| Storage | Has its own time-series database (TSDB) | Doesn’t store data; uses connected sources | Elasticsearch stores and searches data |
| Strengths | Efficient metric storage, powerful query language (PromQL), alerting, finds services automatically | Great visualizations, connects to many sources, flexible dashboards, alerting | Powerful text search, scalable log storage, integrated interface (Kibana) |
| Typical Data Lake Use | Watching resource use (CPU, memory, network), pipeline stats (speed, delay), query engine performance | Making dashboards to see system health, pipeline status, query speed; setting alerts on important numbers | Gathering logs from all parts (ingestion, processing, storage) for fixing bugs, checking security, auditing |
The Strength of Being Modular: Advantages of a Decoupled Design
Building your data lake from independent pieces (modules) that work together is a smart approach for making it resilient and easy to change. Instead of one giant system, you have separate parts (ingestion, storage, processing, querying, catalog) that talk to each other through clear rules (APIs or protocols).
This has many benefits:
- Flexibility: Easily swap or upgrade one piece without affecting others.
- Independent Scaling: Grow storage, computing, or ingestion separately as needed, saving money.
- Best Tool for the Job: Pick the top open source tool for each function.
- Problem Isolation: If one part fails, the rest of the lake can keep working.
- Faster Development: Teams can work on different modules at the same time.
- Easier Maintenance: Smaller, focused pieces are often simpler to manage.
This is very different from tightly linked proprietary systems where you can’t easily separate or replace parts.
Building on a Solid Foundation with OpenMetal
Making these design ideas work well really depends on the computer systems (the infrastructure) you build them on. Your choice of where to host everything—public cloud, private cloud, your own servers—affects speed, growth, control, and cost. The wrong infrastructure can slow things down, cost too much, or limit your options, undoing the benefits of choosing open source.
Infrastructure-as-a-Service (IaaS) providers like OpenMetal offer setups built to handle tough open source data jobs. We help connect the flexible software you choose with the powerful hardware you need. Our options, like Hosted Private Clouds (using OpenStack and Ceph) and Bare Metal Servers (physical servers just for you), fit well with what an open source data lake needs.
Performance
OpenMetal gives you access to fast hardware, including strong Intel Xeon processors, lots of RAM (DDR4/DDR5), and very fast NVMe SSD storage (like Micron 7450 MAX). This speed is essential for tasks that read and write a lot of data, common in processing (Spark, Flink), querying (Trino, Presto), and the transaction parts of lakehouse formats (Delta, Iceberg, Hudi).
Bare metal servers remove the slowdown from virtualization (the “hypervisor tax”), letting your open source software use the hardware directly for top speed. Fast internal networking (like 20Gbps+) helps move data quickly between storage and compute.
Scalability and Reliability
The infrastructure lets you grow storage (using Ceph clusters that can reach petabytes) and compute (adding more servers or cloud instances) separately, matching the decoupled design idea. Backup systems are built-in, like RAID 1 for operating systems on bare metal and the natural fault tolerance of Ceph storage.
Control and Customization
We give you full “root” access on private cloud and bare metal. This deep control is key for tuning operating systems, setting up open source tools perfectly, applying specific security rules, and making sure everything works together – things often limited in public clouds. This fits perfectly with the control you want when choosing open source.
Security and Compliance
Having your own private cloud or bare metal server (single-tenant) is naturally more secure and private than sharing resources in a public cloud (multi-tenant). This helps meet rules about where data can live (data sovereignty) and other compliance needs. OpenMetal uses secure Tier III data centers.
Cost-Effectiveness and Predictability
OpenMetal uses clear, fixed pricing for hardware/cloud resources, unlike the often confusing and changing usage-based bills from public clouds. Fair prices for moving data out (egress) avoid surprise bills, which can be a big problem for data-heavy jobs. Renting the full hardware lets you use resources more efficiently compared to paying for small virtual slices in public clouds, saving more money. Using open source platforms like OpenStack and Ceph also avoids proprietary infrastructure license fees.
By providing infrastructure that offers speed, scalability, control, and predictable costs, solutions like OpenMetal help companies get the full benefits of building their data lakes with open source tools.
As you can see in our customer’s full big data architecture diagram below, you can mix and match open source tools to create a powerful pipeline that will accomplish your goals while saving you a ton of money over proprietary platforms. Building on OpenMetal’s infrastructure will give you hardware that’s 100% dedicated to you plus the flexibility to use private clouds built on OpenStack along with bare metal if it makes sense. You’ll avoid paying for multiple licenses for closed source tools and getting locked into their use, and can easily scale without incurring outrageous additional costs.
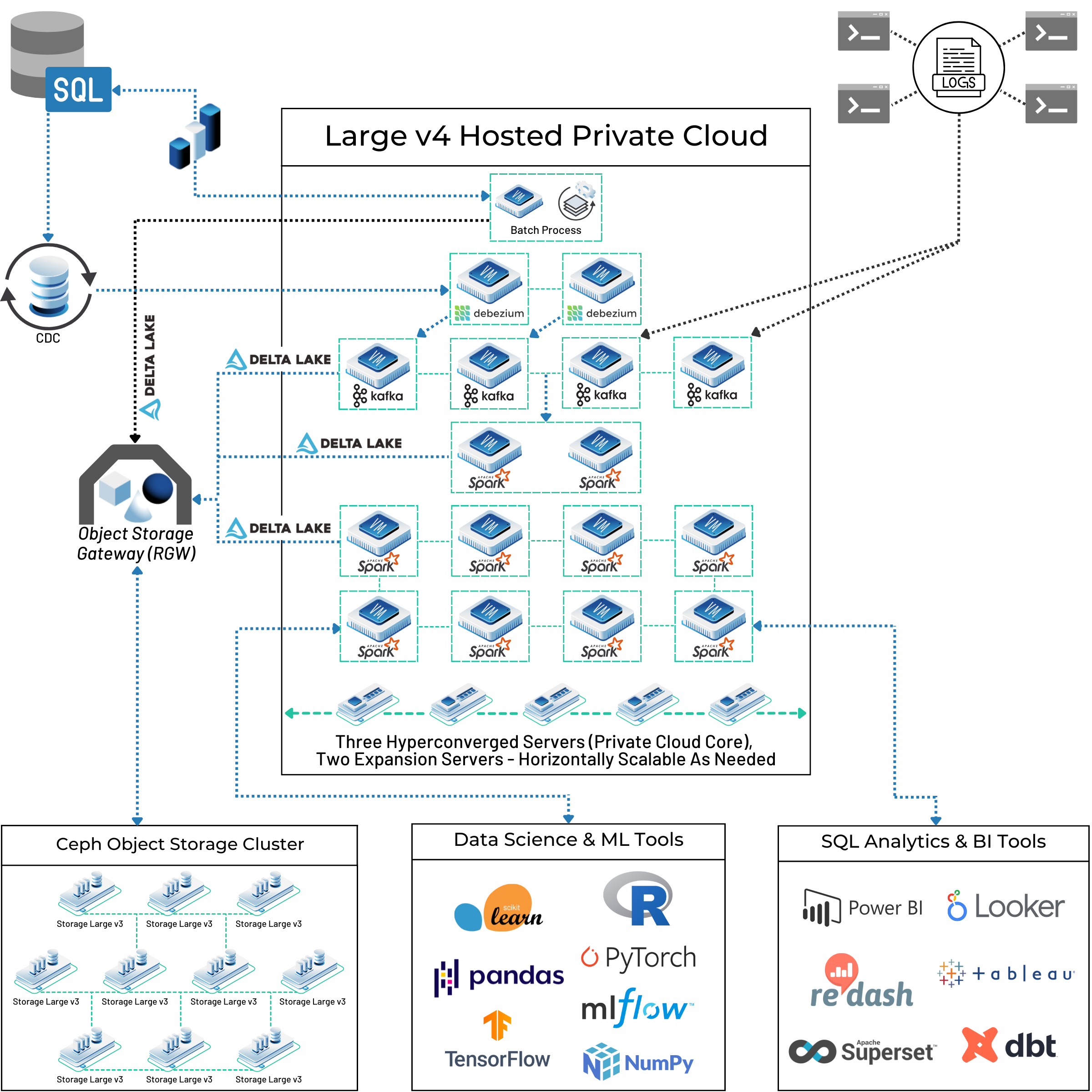
Navigating the Open Source Path and Dealing with Challenges
While open source data lakes offer great benefits, it’s not always a smooth ride. Success means recognizing potential bumps in the road related to complexity, data quality, needed skills, and support, and having plans to handle them.
Handling Complexity and Making Tools Work Together
Putting together a working data lake from different open source pieces can get complicated. Unlike ready-made proprietary systems where parts are built to connect, getting tools from different projects to talk to each other smoothly can be tricky:
- Integration Work: Making tools like Kafka, Spark, HDFS/MinIO/Ceph, Trino, Ranger, and Atlas communicate reliably requires careful setup. You might need custom code or rely on community-made connectors (which might not always be perfect or up-to-date).
- Version Headaches: Keeping track of which versions of different tools work together can be complex. Upgrading one tool might force you to upgrade or adjust others.
- Design Effort: Planning, setting up, and managing how multiple separate systems interact takes significant design work and ongoing effort.
How to Handle It:
- Solid Design: Spend time upfront designing a clear, modular system with well-defined connections between parts.
- Standardize: Stick to specific versions of tools and common ways of connecting (e.g., S3 API for storage, standard SQL for queries) when possible.
- Use Frameworks: Employ orchestration tools (Airflow, Prefect, Dagster) to manage dependencies and automate workflows. Use frameworks like Kafka Connect for standard integrations.
- Infrastructure Platforms: Use solutions like OpenMetal’s hosted private cloud built on OpenStack to simplify setting up and managing the base platform, reducing the integration work needed at the infrastructure level.
- Test Thoroughly: Make integration testing a regular part of how you develop and release changes.
- Find a Quality Partner: We’ve designed these pipelines with customers before and can significantly streamline the process for you to cut down on implementation time and ensure you get everything up and running the right way.
Data Quality: Avoiding the “Data Swamp”
The flexibility of “schema-on-read” is great, but it also means your data lake could turn into a “data swamp” – a messy pile of low-quality, inconsistent, and poorly documented data that’s hard to use. Problems include:
- Weak Governance: Without clear rules, data quality can drop quickly.
- Missing Details: Not enough metadata makes data hard to find, understand, and trust.
- Changing Structures (Schema Drift): If the source data structure changes unexpectedly, it can break data pipelines later on.
- Inconsistency: Keeping data consistent when it comes in raw from many different places is tough.
How to Handle It:
- Govern from the Start: Set up data governance rules and quality checks right away.
- Use Data Catalogs: Deploy and actively use a data catalog (Atlas, Amundsen, DataHub) to manage metadata, track lineage, define business terms, and make data easier to find.
- Manage Schemas: Use file and table formats that handle schema changes well (Avro, Parquet, Delta, Iceberg, Hudi) and check schemas when data comes in and gets processed.
- Validate Data: Build data quality checks into your pipelines using processing engines (Spark, Flink) or orchestrators (Dagster).
- Use Zones: Strictly enforce moving data through defined zones (Raw, Processed, Curated) to ensure quality improves at each step.
Finding the Right Skills: The Open Source Talent Gap
Maybe the biggest challenge is finding people with the right skills. Building and managing a complex system of open source big data tools requires deep knowledge of distributed systems, specific tools (Spark, Flink, Kafka, Hadoop), data modeling, security setup, and performance tuning.
- Talent Shortage: There’s often more demand for experienced data engineers and platform engineers than people available.
- Steep Learning Curve: Mastering multiple complex open source tools takes time and effort.
- Confidence Issues: Not having enough in-house experts can make teams unsure about managing the platform well, leading to poor setups, security risks, or wasted money.
This skills gap can make other problems worse. Less experienced teams might struggle with integrations, fail to set up good governance, or have trouble fixing performance issues, increasing the risk of project delays or failure.
How to Handle It:
- Invest in Training: Train your current team through dedicated programs and certifications.
- Engage with Communities: Encourage teams to participate in open source communities to learn and get help.
- Hire Strategically: Focus on hiring engineers with proven experience in the tools you need and a strong resume.
- Get Outside Help: Bring in specialized consultants for initial design, setup, or tricky problems.
- Use Managed Services: Consider using managed services for specific parts (like managed Kafka or Kubernetes) or the underlying infrastructure (like OpenMetal’s OpenStack-powered private cloud) to reduce the operational workload and the need for deep expertise in those areas.
Support and Upkeep: Community Help vs. Paid Support
Unlike proprietary software that usually comes with a support contract, open source has different ways to get help, each with pros and cons.
Community Support
- Pros: Free access to forums, mailing lists, guides; potentially many knowledgeable users; common problems often identified quickly.
- Cons: No guarantee of quick answers (SLAs); help quality varies; requires you to do a lot of troubleshooting yourself; information can sometimes be scattered or old.
Enterprise Support
- Pros: Offered by the original vendor (e.g., Confluent for Kafka) or third-party experts (e.g., OpenLogic); provides guaranteed response times (SLAs), dedicated help channels, expert assistance, proactive fixes, and sometimes legal protection.
- Cons: Costs extra money; might still involve some vendor influence, though usually less than fully proprietary software.
Choosing What’s Right: The best choice depends on how critical the tool is, how much risk your company can handle, your team’s expertise, and your budget. Many companies use a mix: rely on community help for less critical parts or things they understand well, and pay for enterprise support for essential components or areas where they lack skills.
Building a successful open source data lake means facing these challenges head-on with good planning, smart design, a focus on governance and quality, strategic talent management, and smart choices about support.
Looking Ahead and What’s Next for Open Source Data Lakes
The world of open source data lakes is always changing and moving fast. Driven by the needs of AI, real-time analysis, and increasingly complex data systems, several important trends are shaping the future of these powerful platforms.
The Rise of the Open Data Lakehouse
The data lakehouse idea – mixing the flexibility of data lakes with the reliability of data warehouses – is becoming the main way to build. Open table formats like Delta Lake, Apache Iceberg, and Apache Hudi are making this happen by adding features like reliable transactions (ACID), time travel, and better metadata management right on top of cheap object storage. The future looks like:
- Better Teamwork: More focus on making different table formats work together smoothly, like Delta Lake’s UniForm feature that lets Iceberg and Hudi read Delta tables.
- More Warehouse Features: Adding more traditional data warehouse speed tricks (like better indexing, pre-calculated results, smart caching, query tuning) into open source lakehouse tools.
- Easier Management: More automation of tasks like cleaning up and organizing tables built right into the table formats, reducing the manual work needed.
AI and ML Living Naturally in the Data Lake
The connection between data lakes/lakehouses and AI/ML will only get stronger. The open source lakehouse is becoming the standard place to bring together massive data storage with the entire AI/ML process – from preparing data and creating features to training models and putting them to work. Future trends include:
- Tighter Connections: Making it even easier for data lake tools (Spark, Flink, table formats) to work with popular AI/ML frameworks (TensorFlow, PyTorch, scikit-learn).
- AI Helping Manage Data: Using AI inside the data lake platform itself for tasks like automatically figuring out metadata, monitoring data quality smartly, spotting problems in data pipelines, and tuning performance automatically.
- AI-Ready Data Products: A move towards creating well-organized, reliable, easy-to-use “data products” within the lakehouse, specifically designed to feed AI/ML projects and let people do their own analysis.
Super-Personalization with Real-Time Processing
Businesses increasingly want instant answers and actions based on the very latest data. Things like real-time personalized offers, spotting fraud instantly, changing prices dynamically, and analyzing sensor data require processing data the moment it arrives. This trend will lead to:
- Faster Stream Processing: Open source stream processing engines like Apache Flink and Spark Structured Streaming will keep getting better, aiming for even lower delays, handling more data, improving how they track information over time, and making it easier to work with lakehouse table formats for real-time updates and deletes.
- Real-Time Ingestion: Improvements in tools like Apache Kafka to handle even more data reliably, along with connectors built for real-time sources.
Data Mesh Ideas and Shared Governance
While the lakehouse provides the technical base, organizational ideas like Data Mesh are changing how data is managed. Data Mesh suggests that different business teams should own their data (“data as a product”), have access to self-service tools, and follow shared rules (federated governance). The open source world is adapting to support this:
- Federated Systems: More use of tools that support this distributed approach, like query engines (Trino) that can query data across different teams without moving it all to one place , and metadata platforms (DataHub) that support separate metadata services for different teams.
- Data Product Tools: New open source tools and features designed to help teams build, document, find, and share reliable data products within a managed system.
- Rule Enforcement: Better governance tools (like Ranger) to set and enforce company-wide standards even when data ownership is spread out.
The future likely involves sophisticated systems where central lakehouse platforms provide reliable storage and processing, while Data Mesh ideas guide how data is owned, shared, and managed across the company – all powered by increasingly connected and capable open source tools.
Wrapping Up: Building Your Data Future on Open Foundations
Looking at the journey of modern data lakes, it’s clear to see that open source is the smart foundation for building data systems ready for the future. In 2025 and beyond, being able to gather, store, process, manage, and analyze data effectively, quickly, and without breaking the bank is crucial. The open source world offers the tools and flexibility needed to do just that.
Why Open Source is a Strategic Win
Building your data lake with open source parts gives you a winning combination.
Financially, it saves you from hefty proprietary license fees and, more importantly, frees you from being locked into one vendor’s system.
Technically, it offers unmatched flexibility and control, letting you pick the best tool for each job and customize things to fit your exact needs.
The active communities around major open source projects drive innovation quickly, often faster than single companies can. Plus, the openness of the code builds trust and gives you better understanding and control over your whole data system.
From powerful data intake with Kafka or NiFi, scalable storage on Ceph or MinIO using efficient formats like Parquet or ORC, strong processing with Spark or Flink, to the game-changing features of lakehouse formats like Delta Lake, Iceberg, and Hudi – the open source toolkit is complete and ready.
Choose Openness for a Competitive Edge
For data engineers, data scientists, and cloud managers planning their company’s data future, seriously consider and adopt open source solutions to gain a competitive advantage. The open source data lake, especially as it evolves into the lakehouse, provides the foundation needed for:
- Making Data Available: Letting everyone in the organization access and use diverse data.
- Powering Advanced Analytics and AI: Fueling cutting-edge machine learning models and data-driven discoveries.
- Innovating Faster: Quickly adapting to new data sources, analysis methods, and business needs.
Yes, there are challenges with complexity, skills, and support, but they can be overcome. Smart planning, building in strong governance and quality checks from the start, investing in training your people, and using community resources are key.
Additionally, working with infrastructure providers like us here at OpenMetal, whose services match the open source values of control, performance, and predictable costs, can make operations easier and provide a solid base for success.
Choosing to build on open foundations is ultimately a strategic investment in flexibility, control, and future innovation. By tapping into the power of the open source ecosystem, organizations can build data lakes and lakehouses that are powerful and cost-effective today, and also ready to adapt to the data challenges and opportunities of tomorrow.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog