


































In this article
- A Tale of Two Architectures: Monolithic vs. Distributed
- The Foundation: Azure Virtualization vs. OpenMetal Bare Metal
- The Role of Ephemeral NVMe Storage
- A Look Inside a Live TiDB Cluster on OpenMetal
- High Availability in Two Different Worlds
- Scaling Vertically vs. Horizontally
- HTAP vs. Traditional Workloads
- A Total Cost of Ownership (TCO) Breakdown
- Making the Right Choice for Your Workload
- Want to Explore Building Your Database Solutions on OpenMetal Cloud?
Businesses today are challenged with designing systems that can handle both rapid transactions and immediate analytical insights. Modern applications, from e-commerce platforms to IoT data collectors, can’t afford the old trade-offs between transactional processing (OLTP) and analytical processing (OLAP). This dual requirement strains traditional databases and the cloud models they run on, forcing teams to weigh performance, scalability, availability, and cost.
This article explores two different approaches to solving this modern database dilemma. On one side is the established incumbent: Microsoft SQL Server running on an Azure virtual machine. It is a powerful and trusted relational database management system (RDBMS) operating within the vast ecosystem of a major public cloud. This solution represents a “scale-up” philosophy, where power is added to a single, large instance.
On the other side is the open source challenger: TiDB by PingCAP, a distributed, MySQL-compatible SQL database, deployed on a self-managed bare metal cloud from OpenMetal. This combination represents a “scale-out” philosophy, prioritizing horizontal growth, open standards, and direct hardware control.
The critical variable in this comparison is the use of high-performance, ephemeral NVMe storage. This technology offers incredible speed, but its data is volatile. If a server instance stops or fails, the data on its local NVMe drives is lost. How each database architecture handles this volatility says a lot about its core design and its suitability for next-generation workloads.
This analysis provides a deep dive into architecture, deployment, availability, scalability, performance, and cost, all anchored by a real-world OpenMetal customer deployment.
A Tale of Two Architectures: Monolithic vs. Distributed
The biggest difference between SQL Server and TiDB is their core architecture. This dictates how each system scales, handles failure, and manages workloads. One is a monolithic system, perfected over decades for single-server power. The other is a distributed system, designed from the ground up for elasticity and resilience.
The Monolithic Titan – SQL Server on a VM
Microsoft SQL Server uses a traditional, monolithic RDBMS architecture. A single, powerful server process is responsible for all database operations: parsing queries, managing transactions, and handling data storage. This design is mature, well-understood, and highly optimized for performance on a single machine.
In an Azure deployment, this architecture primarily scales vertically (or “scales up”). When a workload outgrows its server, the solution is to get a larger, more powerful, and more expensive virtual machine. This often requires downtime as the VM is reconfigured and restarted.
While this model works well for many transactional workloads, it faces challenges at a massive scale. Running complex analytical queries on the same instance can take resources away from transactional operations, hurting performance. This often forces organizations to use a separate process to move data into a dedicated data warehouse for analytics, which adds complexity, cost, and data delay.
The Distributed Collective – TiDB’s Modular Design
TiDB was created to overcome the limits of monolithic databases. It is a distributed SQL database, fully compatible with MySQL, and designed for horizontal scalability and Hybrid Transactional/Analytical Processing (HTAP). Its architecture is modular, with distinct, independently scalable components:
- TiDB Server: This is the stateless SQL layer. It receives queries, builds an execution plan, and returns results. Because it’s stateless, you can add more TiDB servers behind a load balancer to scale out query processing power.
- TiKV Server: This is the distributed, transactional, key-value storage engine. Data is automatically broken into chunks (“Regions”) and spread across multiple TiKV nodes. To ensure data durability, TiKV uses the Raft consensus protocol to replicate each Region (usually 3 or 5 times) across different servers.
- TiFlash Server: This is a columnar storage engine for analytics. TiFlash nodes keep a real-time copy of the data from TiKV but store it in a columnar format optimized for analytical queries. This allows TiDB to run heavy analytical workloads without slowing down transactional performance.
- Placement Driver (PD): This is the “brain” of the cluster. It manages metadata, schedules data replication and rebalancing, and ensures transaction consistency.
This modular design allows for independent, horizontal scaling of compute (TiDB), row-based storage (TiKV), and column-based storage (TiFlash), offering flexibility that is impossible in a monolithic system.
The architecture also determines how the system handles failure:
- A monolithic SQL Server instance is a single point of failure; if the VM fails, the database is down until a failover to a standby replica is complete, a process managed by external systems.
- TiDB’s distributed design compartmentalizes failure. The loss of a single TiKV or TiFlash node is an expected event. The Raft protocol ensures that as long as a majority of replicas are available, the cluster continues to operate without interruption, automatically healing itself in the background.
| Azure SQL Server (IaaS) | TiDB on OpenMetal (Self-Managed) | |
|---|---|---|
| Core Architecture | Monolithic RDBMS | Distributed, modular (Compute/Storage separation) |
| Primary Scaling Method | Vertical (Scale-Up) | Horizontal (Scale-Out) |
| Storage Model | Tightly-coupled; data/logs on persistent disks | Decoupled; row (TiKV) & columnar (TiFlash) stores |
| High Availability | External dependency (WSFC, Always On AGs) | Intrinsic property (Raft consensus protocol) |
| Analytical Workload | Requires separate ETL/data warehouse | Native HTAP (Hybrid Transactional/Analytical) |
| SQL Compatibility | T-SQL | MySQL |
The Foundation: Azure Virtualization vs. OpenMetal Bare Metal
The underlying infrastructure—the “cloud” itself—plays a huge role in the performance, control, and cost of a database. The difference between a virtualized public cloud and a dedicated bare metal cloud highlights a trade-off between convenience and raw power.
The Azure Public Cloud: Convenience With a Catch
The Azure IaaS model provides virtual machines that run on a hypervisor, a software layer that abstracts the physical hardware and allows multiple VMs from multiple customers to share a single physical server’s resources. This multi-tenant model is what makes the public cloud work.
The advantages are quite clear and attractive in many situations: you can get a VM in minutes, you have a massive global footprint, and Microsoft manages the physical data centers.
However, this convenience comes with a price. A portion of the server’s resources is used by the hypervisor itself, so your VM never gets 100% of the hardware’s power. Our company president wrote a great article about public cloud versus private cloud resource management you may be interested in to learn more about the advantages of private cloud when it comes to this. When you lease a VM from a public cloud, you must pay for a VM for a workload that will use roughly 30% of the resources on average and will burst to use, when averaged out over time, no more than 30% more. When averaged, this leaves roughly 40% of the VM wasted. In public cloud, your wasted resources are often designed to then be reclaimed by the public cloud and resold to other users!
And also very importantly, your VM’s performance can be affected by other customers on the same physical host. This “noisy neighbor” problem can lead to unpredictable performance, which is bad for sensitive database workloads.
The OpenMetal Private Cloud: Control and Predictability
OpenMetal provides a different model: a private cloud built on dedicated, physical bare metal servers. This is a single-tenant environment. When you lease a server, you get the entire server. There is no performance loss from a hypervisor, your private cloud resources can be 100% used by you, and there is no noisy neighbor problem.
Private Cloud vs Public Cloud Resource Management From Within a VM
![]()
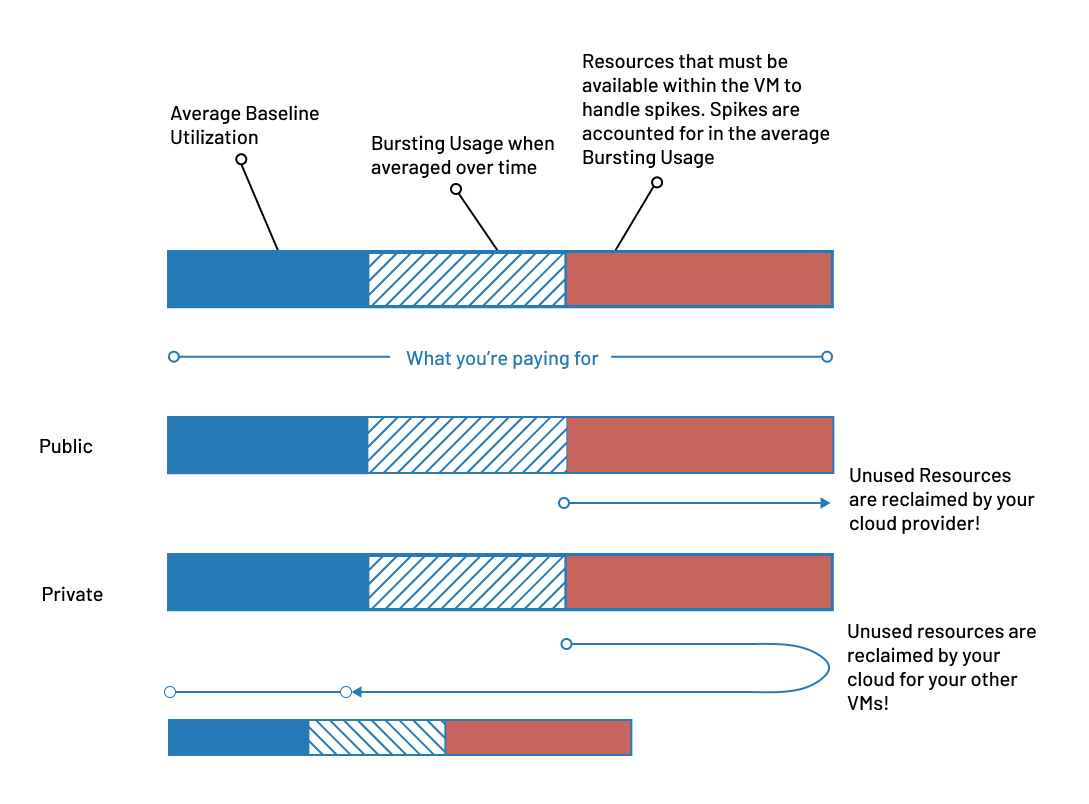
This approach delivers several advantages for demanding databases:
- Predictable Performance: Because all hardware resources are dedicated to your workload, performance is consistent and predictable. This is vital for meeting strict service-level agreements (SLAs).
- Complete Control: You get full root-level access to the hardware. This allows for deep customization of the operating system and applications. With out-of-band management (IPMI), you can perform low-level tasks just as if the machine were in your own data center.
- Enhanced Security: The single-tenant nature of bare metal provides the highest level of security and isolation. There is no shared hypervisor that could become a vector for attacks. This is high-priority for organizations with strict security needs.
OpenMetal adds a cloud-like management experience on top of this bare metal foundation using open source tools like OpenStack. This gives you the automation of a cloud platform with the performance of dedicated hardware.
The choice is between Azure’s vast service catalog with potential performance issues, versus OpenMetal’s consistent performance and security on a platform focused on cost-effective infrastructure.
The Role of Ephemeral NVMe Storage
Now we get to the core of our comparison: using ephemeral NVMe storage. This technology is a double-edged sword. It offers extremely low latency and high speed, but its data is volatile, meaning it disappears if the server stops or fails. How an architecture handles this volatility separates a system that can merely use fast storage from one that is truly built for it.

Is this meme too outdated to use at this point? Oh well, I’m using it!
SQL Server’s Cautious Approach: tempdb Acceleration
For SQL Server on Azure VMs, the best practice is to use the local ephemeral disk only for the tempdb system database. This is a safe strategy because tempdb is a scratch space; its contents are rebuilt every time the SQL Server service starts. Placing it on a fast local disk can significantly boost performance for queries that use temporary tables or sorting operations.
However, this approach is cautious. Microsoft’s documentation is clear that primary data and log files should never be placed on ephemeral storage, as a simple VM restart could cause irreversible data loss. The durability of a SQL Server database is tied to its data and log disks, which must be on durable storage like Azure Premium SSDs.
This strategy can also create operational problems. Because the ephemeral disk can be wiped, administrators often need startup scripts to create the tempdb folder before SQL Server starts. These scripts can sometimes fail, preventing the database from coming online.
TiDB’s Built-in Approach: Distributed Durability
TiDB’s architecture allows it to take a much bolder approach. It’s designed to use ephemeral NVMe as the primary storage for its data nodes (TiKV and TiFlash) without sacrificing durability. This is possible because TiDB’s durability is not tied to any single disk. Instead, it is guaranteed by distributed consensus.
The Raft consensus protocol is the key. Every piece of data in TiDB is replicated across multiple physical nodes. A write is only committed once it has been successfully written to a majority of the replicas.
Consider a setup with three replicas for each piece of data, each on a different bare metal server with an ephemeral NVMe drive.
- An application sends a write request to the TiDB cluster.
- The write is sent to the leader of the corresponding Raft group.
- The leader writes the data to its own local disk and forwards it to the two followers.
- The followers write the data to their local disks and acknowledge back to the leader.
- Once the leader receives an acknowledgment from at least one follower (creating a majority), it commits the transaction.
Now, imagine one of these servers fails and its ephemeral drive is wiped. The data is still safe on the other two replicas. The cluster automatically detects the failure, elects a new leader from the surviving nodes, and service continues without interruption. The Placement Driver then creates a new, third replica on another healthy node to restore full redundancy.
This design effectively turns ephemeral storage from a risk into a high-performance asset. TiDB is architected for it, fully exploiting the speed of local NVMe while ensuring durability through replication. This is something a monolithic database like SQL Server cannot do.
A Look Inside a Live TiDB Cluster on OpenMetal
To move from theory to practice, let’s look at a real-world customer deployment of a self-managed TiDB cluster running on an OpenMetal bare metal cloud. The following images provide a look at the architecture, resources, and performance of this system.
The Infrastructure View (OpenMetal Dashboard)
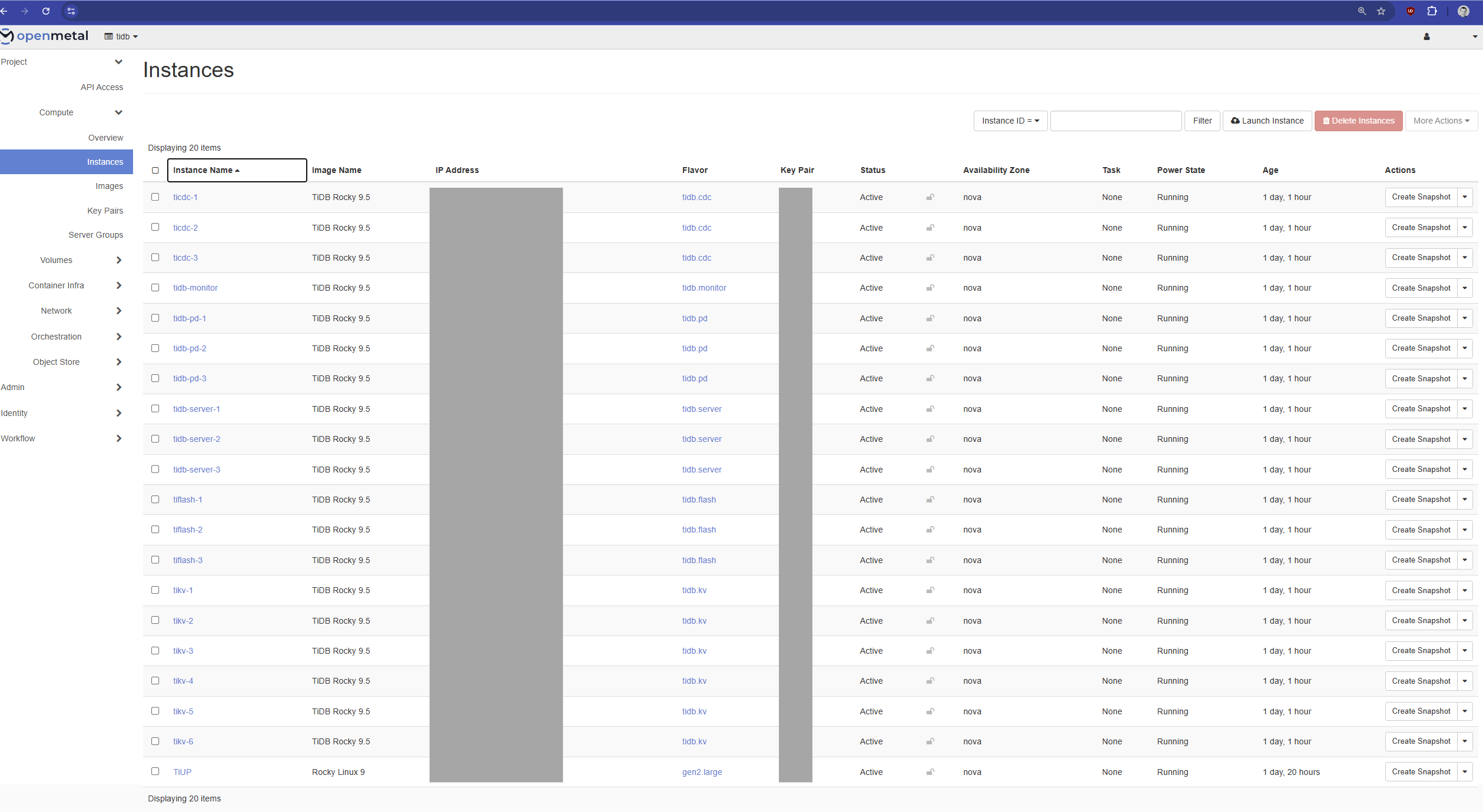
This view from the OpenMetal portal shows the building blocks of the cluster: individual bare metal servers provisioned as instances.
We can see the different roles designated by the instance names: PD for the control plane, TiDB for the SQL servers, TiKV for transactional storage, and TiFlash for analytical storage. This lets us see the distributed, modular architecture.
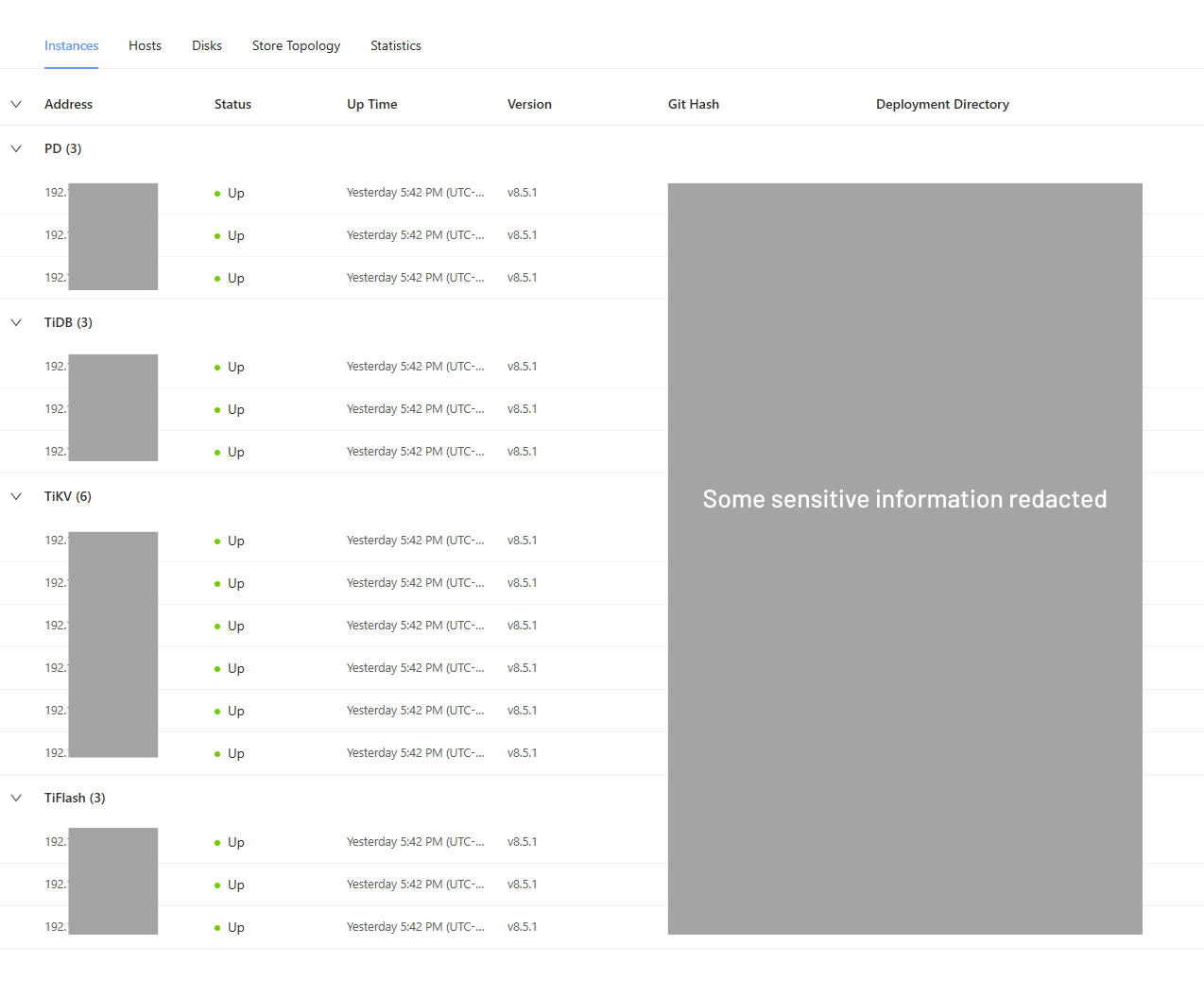
The Cluster Topology (TiDB Dashboard)
The TiDB Dashboard provides a deeper look inside the cluster itself. This first screen confirms the cluster’s composition and that all nodes are up and running. The redundancy is evident: 3 PD nodes, 3 TiDB nodes, 6 TiKV nodes, and 3 TiFlash nodes.
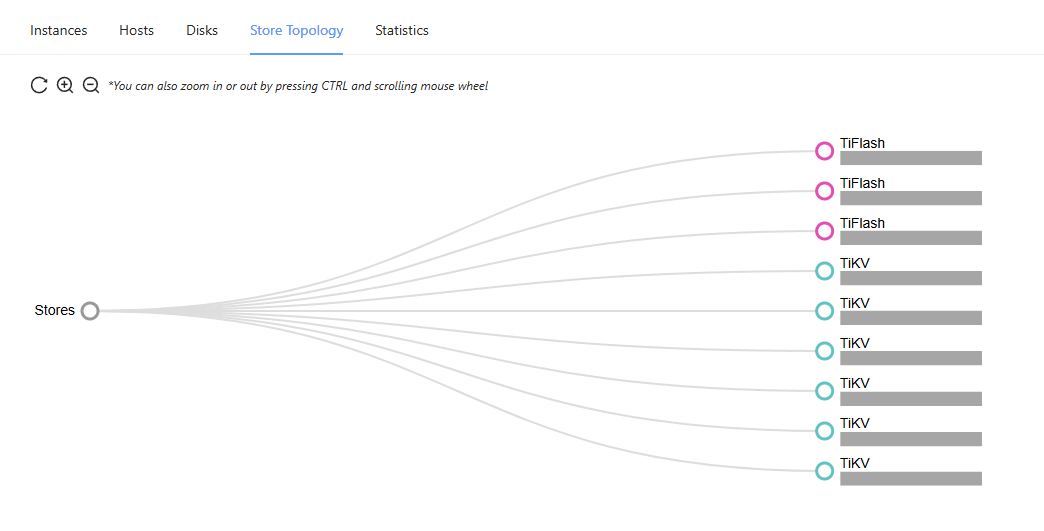
The store topology view here provides a clean visual representation of how the central “Stores” are distributed across the various TiKV and TiFlash nodes, which handle the row-based and column-based data storage, respectively.
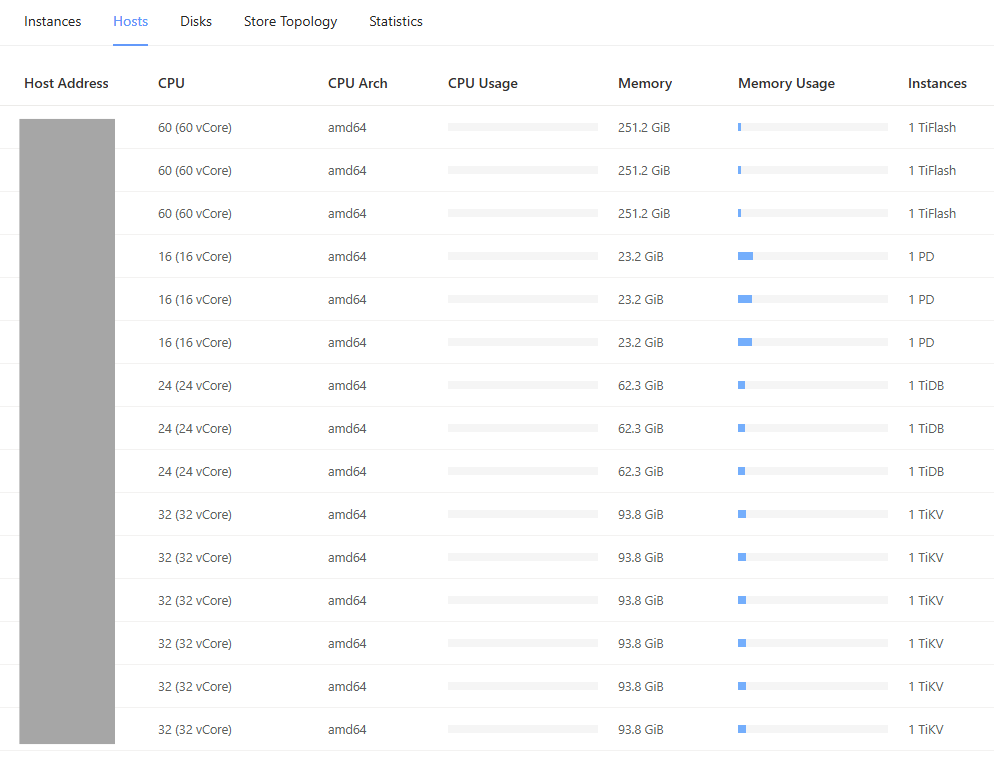
This next view is one of the most revealing. It shows a deliberately asymmetrical hardware allocation, where resources are precisely matched to the function of each component:
- TiFlash Nodes: These are the most powerful servers, with 60 vCores and ~251 GiB of RAM, because analytical queries are often CPU and memory-intensive.
- TiKV Nodes: These are robust servers with 32 vCores and ~94 GiB of RAM, built for the high I/O demands of transactions.
- TiDB Nodes: These have 24 vCores and ~62 GiB of RAM, enough for processing SQL logic.
- PD Nodes: These are the lightest, with 16 vCores and ~23 GiB of RAM, as their role is metadata management, not heavy data processing.
This level of granular, “right-sized” hardware mapping is a key advantage of building on a bare metal platform. Instead of being forced into predefined VM “T-shirt sizes”, the customer selected specific server configurations from OpenMetal’s catalog that perfectly matched the needs of each database component.
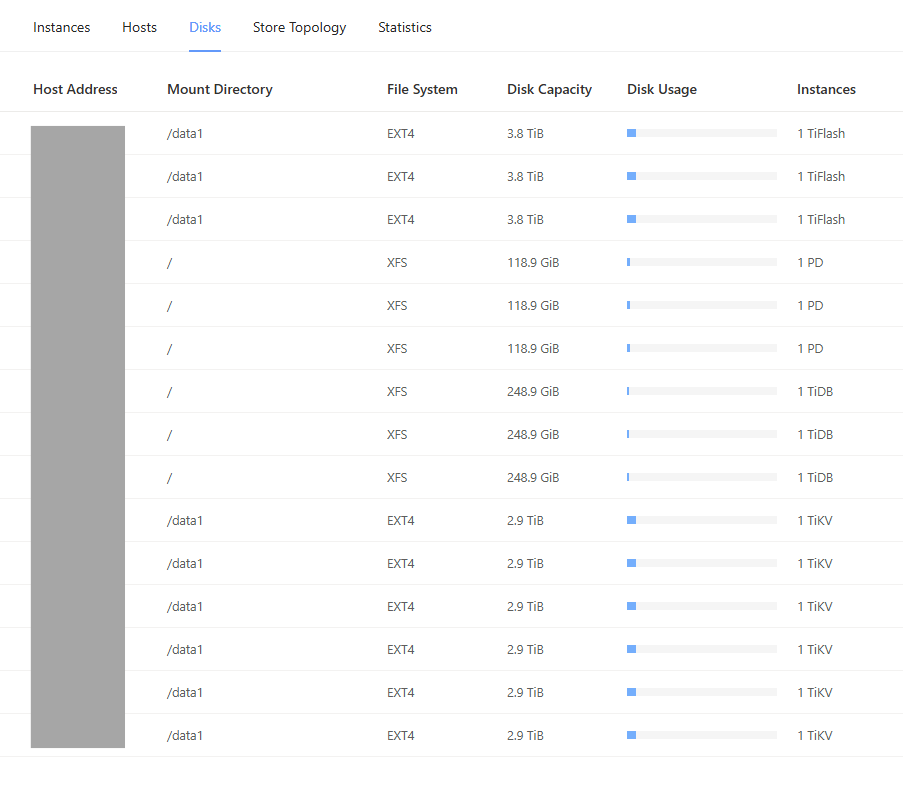
This disk view confirms the storage capacity, highlighting the multi-terabyte ephemeral NVMe drives that form the high-speed foundation of the TiKV and TiFlash layers.
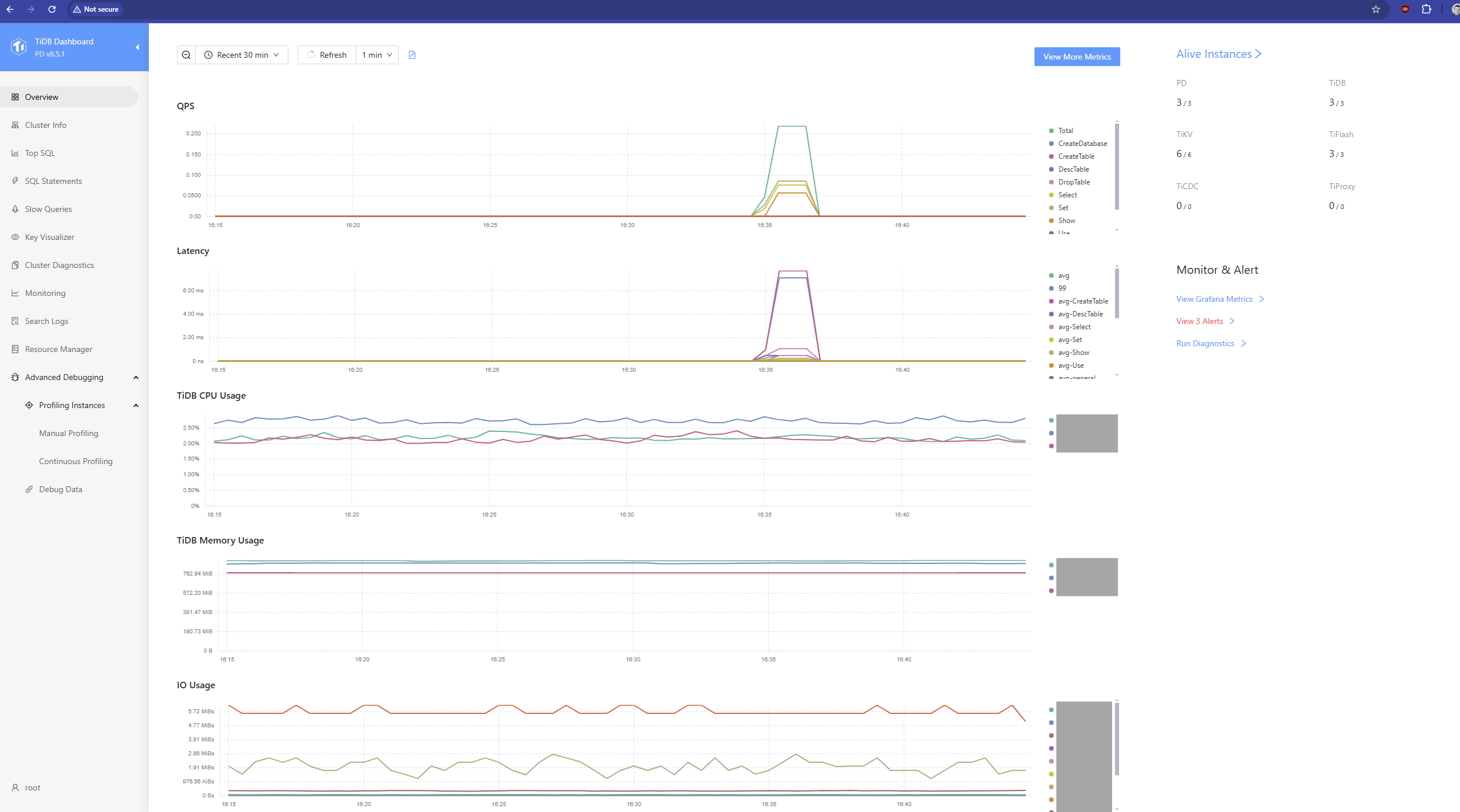
The Workload in Action (Performance Dashboards)
Finally, let’s look at the cluster under load. Revisiting this dashboard provides a high-level health check. The QPS graph shows dynamic query loads, while the Latency graph demonstrates response times consistently in the low single-digit milliseconds. The IO Usage graph is particularly interesting, as it shows I/O distributed across multiple TiKV nodes (the different colored lines), a visual confirmation of the scale-out storage at work.
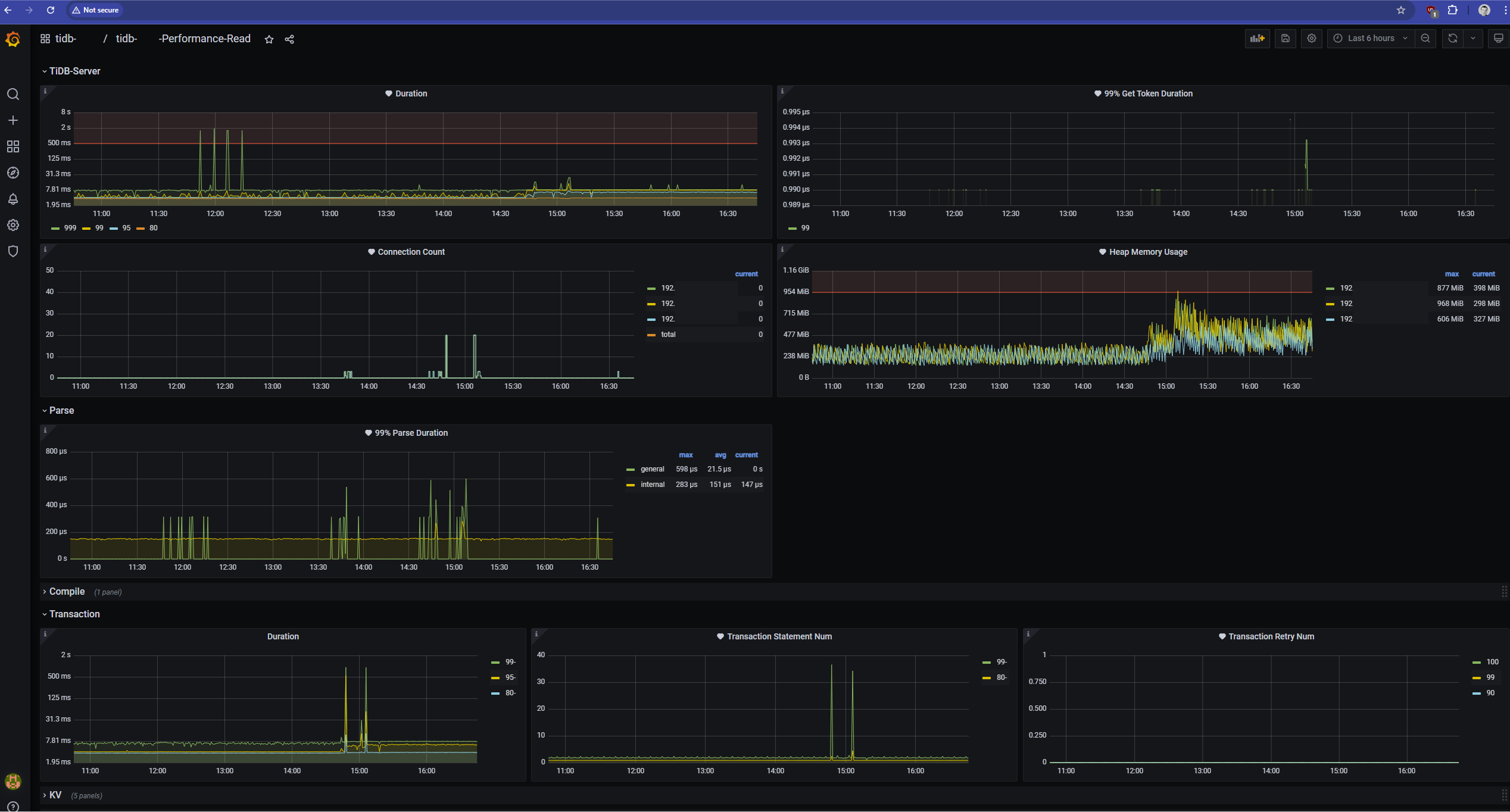
This more detailed Grafana view reinforces that we’re looking at a healthy, performant cluster. Key metrics like query duration (top left) are consistently low, with only occasional spikes. Connection counts and memory usage are stable. This is the picture of a production system handling its workload with ease.
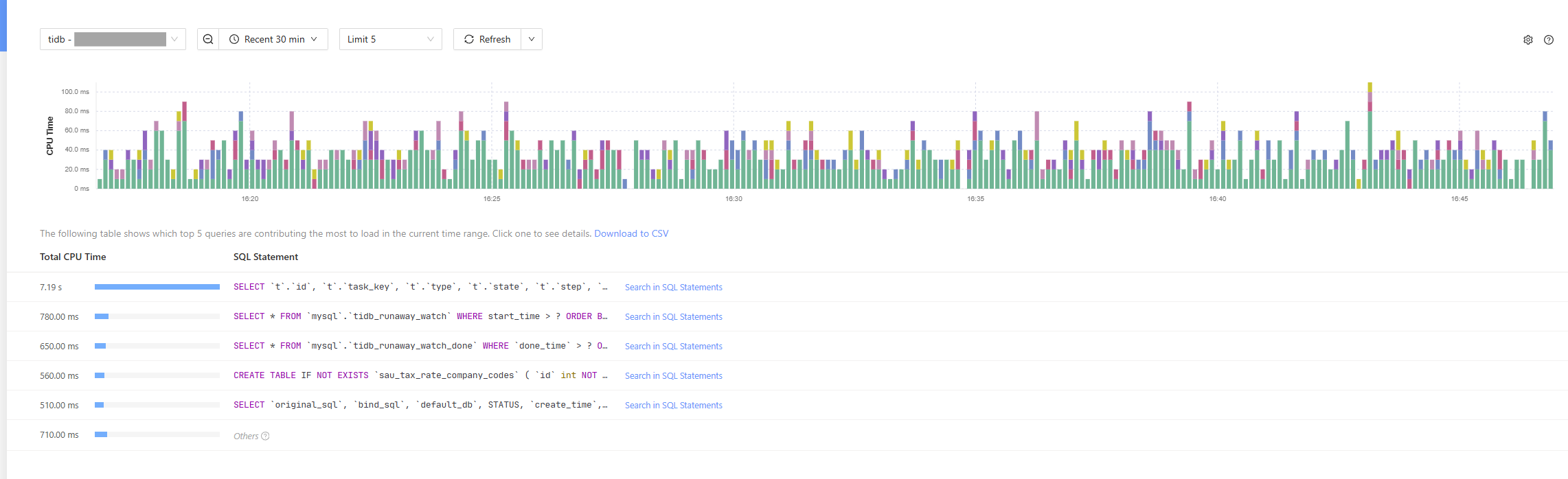
This “Top SQL” screen is a powerful tool for performance tuning. It shows that while the top query is a SELECT, the workload also includes CREATE TABLE and other statements, confirming that this is a true mixed, or HTAP, workload.
Taken together, these screenshots paint a clear picture of a sophisticated, well-architected HTAP system. It is a system where hardware is deliberately matched to software function, an optimization best achieved on a flexible bare metal platform.
High Availability in Two Different Worlds
High availability (HA) is non-negotiable for any critical database. Both SQL Server and TiDB can deliver excellent uptime, but they do so in very different ways. SQL Server relies on a complex setup of external components, while TiDB’s availability is an intrinsic, self-managing property of its design.
SQL Server’s HA: The Always On Availability Group
Achieving high availability for SQL Server in Azure requires configuring several components into what is known as an Always On Availability Group (AG). The key pieces are:
- Windows Server Failover Cluster (WSFC): This Microsoft technology manages the cluster state and health.
- Availability Group Replicas: An AG consists of a primary read-write replica and one or more secondary replicas. Data is streamed from the primary to the secondaries. With synchronous-commit mode, the primary waits for a secondary to confirm the write, guaranteeing zero data loss but adding latency. With asynchronous-commit mode, the primary commits immediately, offering lower latency but risking data loss if the primary fails before the data is sent.
- Listener and Azure Load Balancer: Applications connect to a virtual network name called a “listener.” In Azure, this listener’s IP address must be managed by an Azure Load Balancer, which detects the current primary node and routes traffic to it. This adds another layer of configuration and a potential point of failure.
Setting up an AG in Azure is a well-documented but complex process, involving domain controllers, availability sets, and careful network planning.
TiDB’s HA: Baked into the Architecture
TiDB’s approach to high availability is fundamentally different. It is not an add-on feature but a core part of its distributed design, managed automatically by the Raft consensus protocol.
Instead of a single primary and passive standbys, TiDB operates on active consensus. Each piece of data has a Raft group, typically with three or five replicas spread across different servers. A leader is elected within each group to coordinate writes, but all replicas are active participants.
The failover process is automatic and granular:
- If a server hosting a Raft leader becomes unresponsive, the remaining followers quickly detect its absence.
- The followers initiate an election, and a new leader is chosen from the healthy replicas, typically within seconds.
- The TiDB servers are notified of the new leader and seamlessly redirect new requests.
This process requires no manual intervention, no external cluster manager, and no special load balancer for the data layer’s failover. It is a self-healing, self-managing system. This built-in resilience is what makes TiDB so well-suited for running on ephemeral storage. The database is designed to expect that individual nodes can and will fail, and it handles it gracefully.
| Azure SQL Server (Always On AGs) | TiDB on OpenMetal (Raft) | |
|---|---|---|
| Core Mechanism | Windows Server Failover Cluster (WSFC) | Raft Consensus Protocol |
| Data Replication | AG Log Stream (Synchronous/Asynchronous) | Raft Log Replication (Always Synchronous) |
| Failover Trigger | Cluster Service detects node/service failure | Raft group detects leader failure, holds election |
| Client Endpoint | AG Listener (requires Load Balancer/DNN) | Standard connection to any stateless TiDB Server |
| Handling Ephemeral Node Failure | Full instance failover to a secondary replica. Potential for data loss if using async commit. | Transparent; Raft group elects a new leader from surviving replicas. No data loss. Cluster self-heals. |
| Operational Overhead | High; requires configuring WSFC, AGs, networking, listeners, and load balancers. | Low; HA is an intrinsic, self-managing property of the architecture. |
Scaling Vertically vs. Horizontally
As workloads grow, the ability to scale your database becomes more important. Here again, the design philosophies of SQL Server and TiDB lead to different paths, with major implications for cost, performance, and agility.
Scaling SQL Server – The Vertical Climb
As a monolithic system, SQL Server’s primary way to scale is vertically. In Azure, this means when you hit a performance limit, you provision a larger VM. For example, you might move from a 16-core VM to a 32-core VM.
This approach has several drawbacks:
- Downtime: The scaling process is disruptive, typically requiring a maintenance window to shut down, resize, and restart the VM.
- Cost Inefficiency: VM costs in Azure increase pretty dramatically with size. You are forced to scale all resources (CPU, RAM, etc.) together, even if you only need more of one.
- Hard Limits: There is an ultimate ceiling. While Azure offers massive VMs, there is a physical limit to how large a single server can be.
Scaling TiDB – The Horizontal Expansion
TiDB was built for horizontal scaling. When you need more capacity, you simply add more servers (nodes) to the cluster. This is done online, with zero downtime. You provision a new bare metal server from OpenMetal, install the TiDB component, and add it to the cluster. The Placement Driver automatically begins distributing load and data to the new node.
The most powerful aspect of this model is scaling components independently:
- More Users? Add more stateless TiDB server nodes.
- More Writes? Add more TiKV server nodes.
- More Analytics? Add more TiFlash server nodes.
This granular scalability is a more elastic and cost-efficient way to grow. It allows you to address the specific bottleneck in your system without paying for resources you don’t need—a stark contrast to the all-or-nothing upgrades of vertical scaling.
HTAP vs. Traditional Workloads
The architectural differences between the two databases determine how they handle mixed workloads. The ability to perform real-time analytics on live transactional data is a requirement for many modern businesses, and it’s an area where the contrast is sharpest.
The ETL Lag: Analytics on SQL Server
In a traditional system like SQL Server, running large analytical queries directly against the production database can be a problem. These queries can consume huge amounts of resources, slowing down the time-sensitive transactions that the application relies on.
The standard solution is to create a separate system for analytics. This involves a periodic ETL process that extracts, transforms, and loads data into a separate data warehouse. While this protects the performance of the main system, it has downsides:
- Data Latency: Analytics are always performed on stale data, which could be hours or even a day old.
- Complexity: You now have two separate database systems to manage, plus a complex ETL pipeline.
- Cost: You are paying for the infrastructure, licensing, and overhead of two complete database environments.
Real-Time Insights: TiDB’s Native HTAP
TiDB is designed to eliminate this separation. As an HTAP database, it can efficiently handle both transactional and analytical workloads in a single, unified system.
The magic is in its two storage engines:
- TiKV (the row store) handles the high-throughput, low-latency transactions.
- TiFlash (the columnar store) maintains a real-time copy of the data in a format optimized for large-scale analytical queries.
Because TiFlash is a consistent, real-time replica, the data is always fresh. The TiDB optimizer is smart enough to route queries to the right engine. A simple transactional query goes to TiKV for a fast lookup. A complex analytical query is automatically sent to TiFlash for efficient processing.
This provides true workload isolation. Heavy analytical queries run on the TiFlash nodes, leaving the TiKV nodes free to handle transactions without interference. The business benefit is transformative: you can run up-to-the-second analytics on live data, enabling immediate insights without the cost, complexity, and latency of a separate data warehouse.
A Total Cost of Ownership (TCO) Breakdown
While technical capabilities are of course important, the final decision often comes down to cost. A TCO analysis reveals that the choice between Azure SQL and TiDB on OpenMetal is a choice between two different economic models.
The Azure Cost Model: A Labyrinth of Variables
Running SQL Server on an Azure VM involves a complex pricing structure where costs can be hard to predict. The primary components are:
- Compute Costs: You are billed per second for the VM instance, with prices varying based on size and series.
- Storage Costs: You pay separately for the persistent managed disks for the OS, data, and log files. Premium SSDs are priced based on their size and performance. The ephemeral NVMe disk for
tempdbis included in the VM price, but this is only a small part of the storage picture. - Software Licensing: This is often the largest part of the bill. You must pay for both Windows Server and SQL Server licenses. SQL Server Enterprise licensing is extremely expensive, often billed per CPU core, and can dwarf the hardware cost.
- Data Egress Fees: Public clouds like Azure charge a fee for every gigabyte of data that leaves their network. For data-intensive applications, these egress fees can become a massive and unpredictable expense.
The OpenMetal Cost Model: Predictable and Transparent
The OpenMetal model is designed for simplicity and predictability.
- Infrastructure Costs: You pay a fixed, predictable monthly price for the dedicated bare metal servers you lease, based on the hardware you choose.
- Software Licensing: This cost is $0. TiDB is open source, and it typically runs on a free Linux distribution. This eliminates the high and frequently-climbing software licensing costs of the Microsoft stack.
- Data Egress Fees: OpenMetal includes a very large bandwidth allotment with each server at no extra cost. Overages are billed using a fair 95th percentile bandwidth model, which ignores the top 5% of usage spikes. This is far more predictable and cost-effective than the per-gigabyte billing of public clouds.
Total Cost of Ownership (TCO) Estimate
To make this more concrete, let’s create a TCO estimate based on the customer’s cluster specifications. We’ll compare the cost of running the cluster we talked about on OpenMetal with a similarly-resourced cluster of SQL Server Enterprise on Azure VMs.
Cluster Specifications:
- TiDB/SQL Compute Nodes: 3 servers (24 vCore, ~64 GiB RAM)
- TiKV/SQL Data Nodes: 6 servers (32 vCore, ~96 GiB RAM)
- TiFlash/SQL Analytics Nodes: 3 servers (60 vCore, ~256 GiB RAM)
| Cost Component | Azure SQL Server (Estimated Monthly) | TiDB on OpenMetal (Estimated Monthly) |
|---|---|---|
| Compute/Hardware (12 servers total) | ~$18,500 | ~$12,500 |
| OS & DB Licensing (Windows Server + SQL Enterprise) | ~$225,000+ | $0 |
| Persistent Storage (Premium SSDs for Data/Logs) | ~$1,500 | $0 (Included) |
| Data Egress (Assuming 20TB/month) | ~$1,600 | $0 (Included in allowance) |
| Total Estimated Monthly Cost | ~$246,600 | ~$12,500 |
Note: Azure pricing is estimated using the Azure Pricing Calculator for pay-as-you-go rates in a US region, selecting comparable Edsv5-series VMs. SQL Server Enterprise licensing is estimated at ~$146/core/month. OpenMetal pricing is based on public catalog rates for comparable bare metal servers. These are estimates and actual costs will vary.
As you can see, the difference is quite significant! The TCO for the OpenMetal/TiDB solution is an order of magnitude lower. The primary drivers are the elimination of proprietary software licensing fees and punitive data egress charges. The Azure solution’s cost is dominated by Microsoft’s software licenses. While there will always be other potential costs to take into account, such as staffing, training, setup, support, etc., this should be a compelling argument for considering an open source, bare metal approach.
Making the Right Choice for Your Workload
Choosing a database platform is one of the most important decisions a team can make. The comparison between Azure SQL Server and a self-managed TiDB cluster on OpenMetal shows a clear trade-off between the familiarity of an established ecosystem and the power of a modern, open source, scale-out architecture.
When to Choose Azure SQL Server
A traditional SQL Server deployment on an Azure VM remains a valid choice in specific scenarios:
- Your applications and teams are already heavily invested in the Microsoft ecosystem.
- Your team has deep expertise in SQL Server administration but limited experience with Linux or distributed systems.
- Your workload is a classic OLTP system with moderate, predictable scale that fits comfortably on a single large VM.
- You value the convenience of a single vendor and Azure’s broad service catalog more than granular control, raw performance, and cost predictability.
When to Choose TiDB on OpenMetal
The combination of TiDB on OpenMetal’s bare metal cloud is built for the challenges of modern data workloads. This solution shines when:
- You’re building applications that must handle massive data volumes or high-throughput transactions that need seamless, horizontal scaling.
- You need to perform real-time analytics directly on your live operational data, combining OLTP and OLAP into a single HTAP platform.
- Your application stack is, or can be, MySQL-compatible.
- Cost predictability and avoiding vendor lock-in are primary business objectives. Escaping the high cost of proprietary software licensing and unpredictable data egress fees is a strategic priority.
- Your team values ultimate control over their infrastructure and is ready to manage a powerful, open source distributed database.
For businesses designing the next generation of scalable, data-intensive applications, it only makes sense to look towards architectures built for the modern era. The combination of a distributed SQL database like TiDB with the predictable performance and transparent economics of a bare metal cloud provider like OpenMetal offers you a blueprint for success. To see if this approach is the right fit for your business, get in touch with our team!
Interested in OpenMetal Cloud?
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog