


































If you’re on a data engineering team, this probably sounds familiar. You meticulously design ETL logic and tune transformation code, yet data pipelines still crawl, missing service-level agreements and delaying needed insights. You grapple with infrastructure that can’t scale to meet growing data volumes, performance that varies unpredictably from one job run to the next, and cloud bills that spiral out of control. These are not typically failures of application logic, they are symptoms of a fundamental misalignment between the demands of data-intensive workloads and the general-purpose infrastructure on which they are often run.
The performance, reliability, and scalability of your data pipelines are not just functions of the software stack—whether Apache Spark, dbt, or Kafka—but are directly constrained by the foundational infrastructure layer. The initial industry-wide migration to the cloud often involved a “lift-and-shift” of workloads onto generic, multi-tenant virtualized platforms. The persistent pain points you and other data teams experience today signal a market maturation toward a more sophisticated, “workload-first” infrastructure strategy.
This approach recognizes that data-intensive applications have unique requirements like massive I/O throughput, predictable low latency, and enormous network bandwidth that are best served by specialized infrastructure rather than a one-size-fits-all virtualized model. The problem is not the cloud itself, but the type of cloud.
This article presents a blueprint for a modern, high-performance ETL architecture designed to address these challenges. Grounded in a powerful open source stack of Ceph, Delta Lake, and Apache Spark, this system runs on OpenMetal’s bare metal private cloud infrastructure. By deconstructing the architecture, connecting its components to foundational data engineering principles, and exploring the practical advantages of the underlying platform, this article will show how you can reclaim control and achieve the performance necessary to build truly fast, scalable, and reliable data pipelines.
Deconstructing the High-Performance ETL Architecture
The example architecture, illustrated in the diagrams you’ll see in this article, is a cohesive system where each component plays an important role. From the bare metal servers providing the physical foundation to the analytics tools consuming the final product, the design is a deliberate strategy to maximize data throughput and reliability.
The Foundation: A Private Cloud Core on Bare Metal
The choice of infrastructure is the most consequential decision in a data system’s design. The foundation of this architecture is a hosted private cloud built on dedicated bare metal servers, a choice that helps counter the common performance issues that pop up in traditional cloud environments.
The Problem with Virtualization for ETL
Standard public clouds use a hypervisor to partition physical servers into smaller virtual machines (VMs) that are shared among multiple tenants. This model, while flexible for many use cases, introduces two major performance penalties for data-intensive workloads:
- The Hypervisor Tax: The hypervisor itself is a layer of software that consumes hardware resources. It can claim between 5-10% of a server’s CPU and RAM before any user applications even begin to run. For I/O-heavy and CPU-bound ETL jobs, this “tax” is a direct and unavoidable performance drag, increasing processing time and cost.
- The “Noisy Neighbor” Effect: In a multi-tenant environment, VMs share the physical server’s resources, including CPU cycles, memory bandwidth, storage I/O, and network interface cards. A resource-heavy application running in a neighboring VM can consume a disproportionate share of these resources, degrading the performance of other tenants’ applications. This leads to inconsistent and unpredictable ETL job runtimes, making it nearly impossible to guarantee performance or adhere to SLAs. An additional performance loss of 20-30% can be attributed to this effect.
The Bare Metal Solution
OpenMetal’s private cloud core is built on dedicated, single-tenant bare metal servers. This model gets rid of the aforementioned problems by giving applications direct, unmediated access to the physical hardware.
- Predictable Performance: By removing the hypervisor layer, the “hypervisor tax” is eliminated. As the sole tenant on the hardware, the “noisy neighbor” effect is gone. This provides the single most crucial attribute for high-speed, production-grade ETL: predictable, consistent performance.
- Unparalleled Control: Bare metal provides full root-level access to the server. This allows architects and engineers like you to fine-tune the operating system, kernel parameters, and resource allocation to the specific profile of their data workloads, a level of tuning that is unattainable in a managed VM environment.
- Better Security: The physical isolation of a single-tenant environment offers the highest degree of security, removing the risk of cross-tenant contamination and reducing the overall attack surface.
In this customer architecture diagram, the box labeled “Large v4 Hosted Private Cloud” represents this dedicated bare metal foundation. The servers and resources depicted within it are not shared, they are private, dedicated resources for a single organization. This particular cluster is hosted in our Ashburn, Virginia data center, which provides low-latency connectivity to places like Washington D.C., Philadelphia, Atlanta, Jacksonville, Houston, Chicago, New York, Boston, and many more locations around the world.
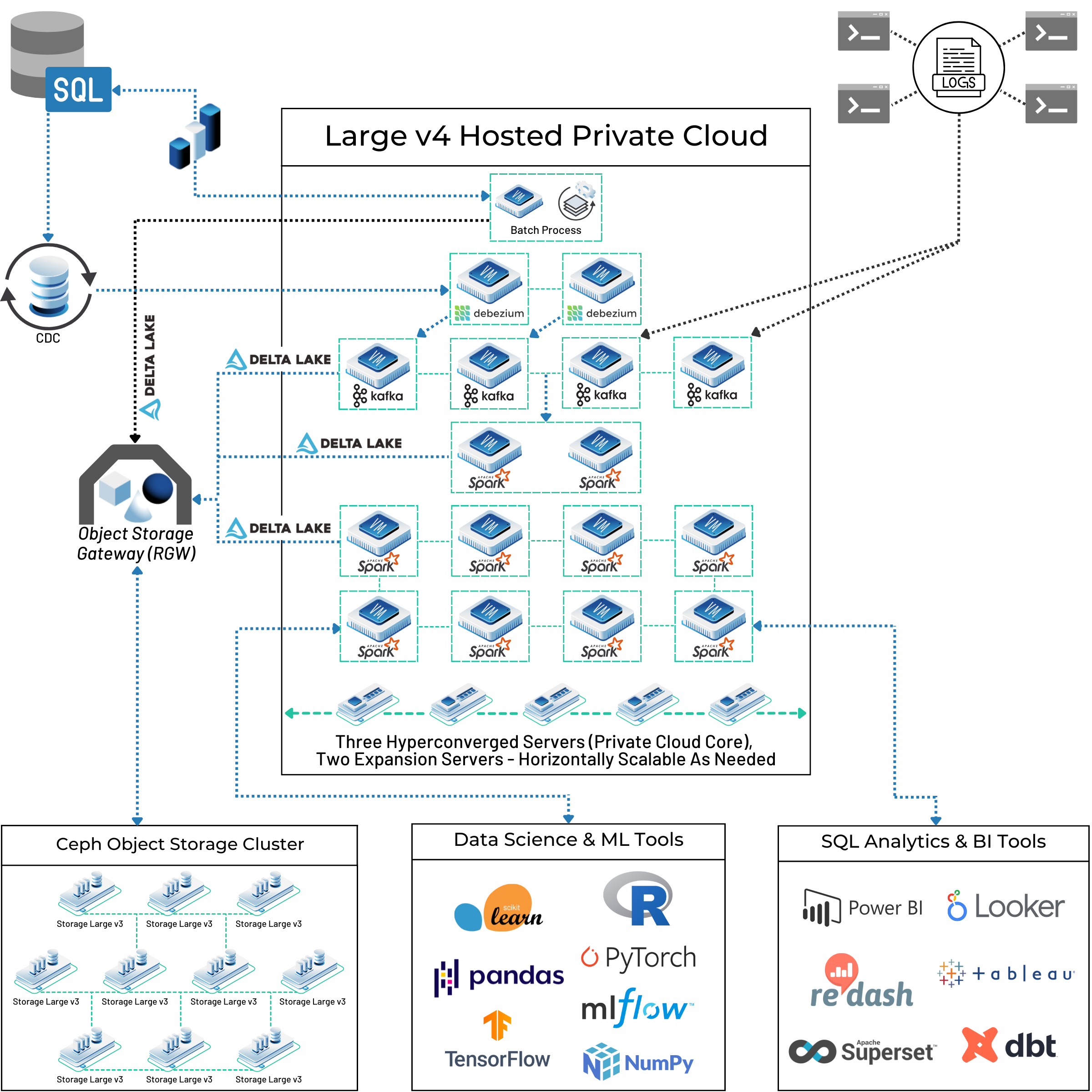
The level of control available with fully dedicated resources is a strategic performance lever. In a virtualized world, performance tuning is often a blunt instrument, limited to scaling up to a larger, more expensive, predefined instance type.
On bare metal, performance tuning becomes a multi-dimensional engineering discipline. You can diagnose a specific bottleneck—for instance, a Spark job that is CPU-bound but underutilizing its allocated memory—and provision a server that matches this need with a high core count and a moderate amount of RAM. This is impossible in a world of fixed instance ratios. This transforms performance tuning from a reactive, costly action into a proactive, architectural design choice, allowing your team to solve bottlenecks at their source far more efficiently.
| OpenMetal Bare Metal Private Cloud | Traditional Virtualized Public Cloud | |
|---|---|---|
Performance | Direct hardware access; no hypervisor overhead; predictable, consistent latency. | Virtualization layer introduces performance overhead and variability (“noisy neighbors”). |
| Control & Customization | Full root access; ability to tune hardware and OS for specific workloads (e.g., Spark’s CPU/RAM ratio). | Limited to predefined instance types; no control over underlying hardware. |
| Network | Dedicated, high-throughput (20Gbps standard) private networking between compute and storage nodes. | Shared network fabric; potential for contention; high costs for inter-AZ traffic. |
| Cost Model | Predictable, resource-based pricing; significantly lower data egress costs. | Complex, usage-based pricing; egress fees can lead to unpredictable and escalating costs. |
| Security | Single-tenant physical isolation provides the highest level of security and data privacy. | Multi-tenant environment; security relies on logical separation, increasing the potential attack surface. |
The Storage Bedrock: Ceph’s Resilient Object Storage
A modern data lake requires a storage foundation that is massively scalable, highly durable, and economically sustainable. This architecture employs Ceph, a powerful open-source, software-defined storage platform that provides object, block, and file storage within a single unified system. The architecture specifically uses Ceph’s object storage capabilities through the RADOS Gateway (RGW), which exposes an Amazon S3-compatible API. This compatibility is critical, as the entire big data ecosystem, including key tools like Delta Lake and Apache Spark, is designed to natively interact with this standard object storage interface.
In the architecture above, the “Ceph Object Storage Cluster” represents the physical deployment of distributed storage nodes. The “Object Storage Gateway (RGW)” is the logical endpoint that applications connect to, providing the S3 API.
Key Ceph features that are essential for this high-speed ETL pipeline include:
- Scalability and Resilience: Ceph is a distributed system designed from the ground up for massive scale, capable of managing petabytes to exabytes of data. It uses a unique algorithm called CRUSH (Controlled Replication Under Scalable Hashing) to intelligently calculate where data should be stored, eliminating the need for a centralized lookup table and thus avoiding single points of failure. It automatically replicates and rebalances data across the cluster in the event of drive or node failures, ensuring high availability and data durability.
- Cost Efficiency: The OpenMetal implementation of Ceph uses highly efficient erasure coding, which provides data redundancy with significantly less storage overhead than simple replication. This is coupled with on-the-fly compression, which can achieve ratios as high as 15:1 on text-based files, dramatically reducing the physical storage capacity required and lowering overall costs.
- Performance: A critical design choice in this architecture is the co-location of the Ceph storage cluster and the Spark compute cluster. They reside within the same data center and are connected via the same high-speed, private VLANs. Data is merely “a few switch hops away,” which minimizes network latency and maximizes throughput for data-intensive read and write operations from Spark.
The Reliability Layer: ACID Transactions with Delta Lake
A common failure mode for data lakes built on raw object storage is their tendency to devolve into “data swamps.” Without transactional guarantees, the system is fragile: concurrent write operations from multiple sources can lead to data corruption, failed ETL jobs can leave behind partially written, unusable files, and there is no built-in mechanism to enforce data quality or schema rules.
Delta Lake is an open source storage layer that sits on top of an object store like Ceph to solve these exact problems. It brings the reliability and data integrity guarantees of a traditional relational database to the vast scale of the data lake by providing ACID transactions (Atomicity, Consistency, Isolation, and Durability).
Delta Lake achieves this through a transaction log, stored as a series of JSON files in a _delta_log directory alongside the Parquet data files in object storage. Every operation that modifies a table whether an insert, update, delete, or merge is recorded as an atomic commit to this log. This log becomes the single source of truth for what data belongs to which version of the table.
- Atomicity ensures that a transaction (like an ETL job writing 1,000 files) either completes in its entirety or not at all. If the job fails midway, no changes are committed to the log, preventing data corruption.
- Isolation ensures that concurrent jobs do not interfere with one another and that a reader will always see a consistent, complete version of the data, never a partially written state.
This reliability makes the implementation of the Medallion Architecture, a best practice for structuring data lakes, much more dependable:
- Bronze Layer: This layer stores raw data ingested from source systems, such as Change Data Capture (CDC) streams from SQL databases or raw event logs from Kafka. The data is stored as-is, providing an immutable, auditable record that can be reprocessed if needed.
- Silver Layer: Data from the Bronze layer is processed through ETL pipelines. Here, it is cleaned, filtered, de-duplicated, and joined with other datasets to create a validated, structured, and queryable view. This is a key output of the transformation stage.
- Gold Layer: Data from the Silver layer is further aggregated and transformed into datasets tailored for specific business use cases. These tables are often denormalized and prepared for consumption by analytics platforms, BI dashboards, and machine learning models.
This layered approach, made possible by the transactional guarantees of Delta Lake, creates a clear data lineage, progressively improves data quality, and ensures that all downstream consumers are working from a reliable, governed dataset.
The Processing Engine: Massively Parallel Transformation with Apache Spark
Apache Spark is the de facto standard distributed engine for large-scale data processing. Its primary advantage lies in its ability to perform computations in memory across a cluster of machines, significantly speeding up iterative algorithms and large-scale transformations. Spark operates on a master-worker architecture where a central driver program analyzes the code, creates a plan of execution (a Directed Acyclic Graph, or DAG), and distributes discrete tasks to a fleet of executor nodes for parallel processing.
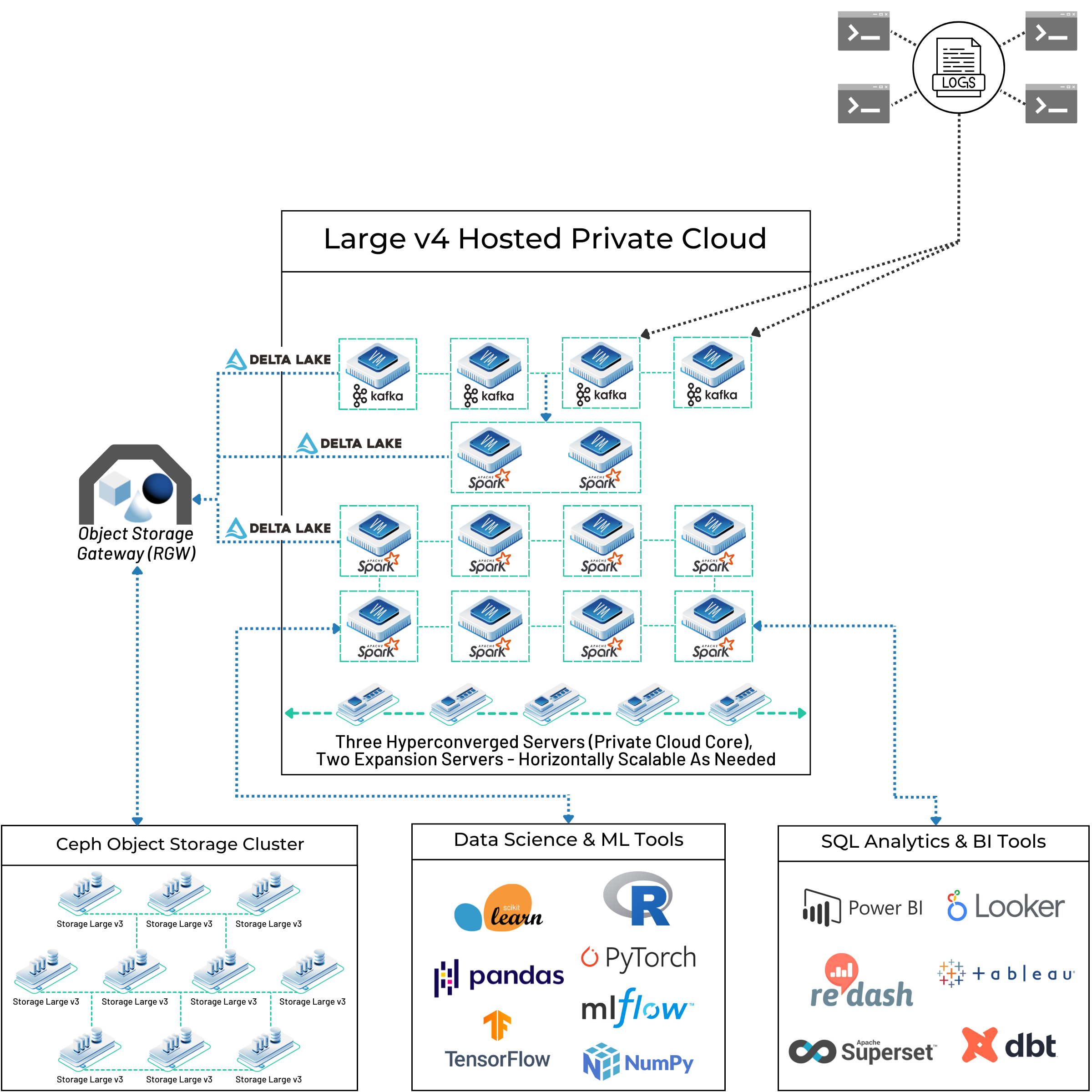
The Kafka to Spark ETL pipeline shown here is a perfect illustration of this process in action:
- Ingestion: Real-time events flow from Apache Kafka into the private cloud environment.
- Bronze Storage: These raw events are landed in a Bronze Delta Lake table, ensuring they are durably stored on the Ceph cluster before any transformation occurs.
- Parallel Processing: The cluster of Spark executors reads data from the Bronze table (or, for real-time use cases, directly from Kafka streams). Spark divides the source data into partitions, and each executor processes one or more partitions in parallel, maximizing the use of the cluster’s CPU and memory resources.
- Transformation and Output: The Spark jobs execute the required ETL logic—cleaning, filtering, enriching, aggregating—and write the transformed results back to Silver and Gold Delta Lake tables, which in turn reside on the Ceph storage cluster.
The Key Lies in the Hardware
The performance of this engine is critically dependent on the underlying hardware and its configuration. Check out this other OpenMetal article for practical guidance on tuning Spark in this bare metal environment:
- Purpose-Built Hardware: The architecture uses bare metal servers specifically chosen for Spark’s needs. OpenMetal offers configurations with high core counts (up to 64 cores/128 threads) and very large memory capacities (up to 2TB of RAM), allowing the cluster to handle extremely demanding jobs.
- High-Speed Network: The standard 20Gbps private networking is not a luxury but a necessity. It is essential for allowing Spark executors to quickly read massive amounts of data from the Ceph cluster (the “shuffle read” phase) and write the results back without creating a network bottleneck.
- Practical JVM Tuning: A key piece of operational wisdom is to avoid creating excessively large Java Virtual Machines (JVMs). For stability, it is preferable to run multiple smaller Spark executors (with JVMs under 200GB of RAM) on a single large bare metal server rather than attempting to run one monolithic executor. This is precisely the type of granular, workload-specific tuning that direct hardware access allows.
The Final Mile: Serving Curated Data for Analysis
The ultimate purpose of any ETL pipeline is to deliver clean, reliable, and timely data to end-users for analysis and decision-making. The architecture completes this loop by making the curated data accessible to a variety of downstream tools. As shown, this includes:
- SQL Analytics & BI Tools: Platforms like Power BI, Looker, Tableau, and dbt can connect to and query the processed data.
- Data Science & ML Tools: Libraries and platforms like scikit-learn, PyTorch, TensorFlow, and MLflow can use the curated datasets for model training and inference.
These tools typically connect to the Gold Delta tables. Because Delta Lake is fully compatible with the Spark SQL engine, these tables can be exposed and queried using standard SQL, providing a familiar and highly compatible interface for the entire analytics organization.
Architectural Insights from the Masters
This modern, open source architecture is not a radical invention but a powerful embodiment of decades of foundational data engineering principles, adapted for the scale and complexity of today’s data. It pulls together the philosophies of the industry’s most influential thinkers.
Bill Inmon’s Vision, Reimagined: The Lakehouse as the Corporate Information Factory
Bill Inmon, widely regarded as the “father of data warehousing,” proposed an architecture he called the Corporate Information Factory (CIF). The heart of the CIF was a centralized Enterprise Data Warehouse (EDW) that served as the organization’s “single source of truth.” In Inmon’s model, data from all operational systems would flow through ETL processes into this central repository. The data within the EDW was to be integrated, subject-oriented, and stored in a highly structured, normalized (typically 3rd Normal Form) format to ensure maximum data integrity and consistency across the enterprise.
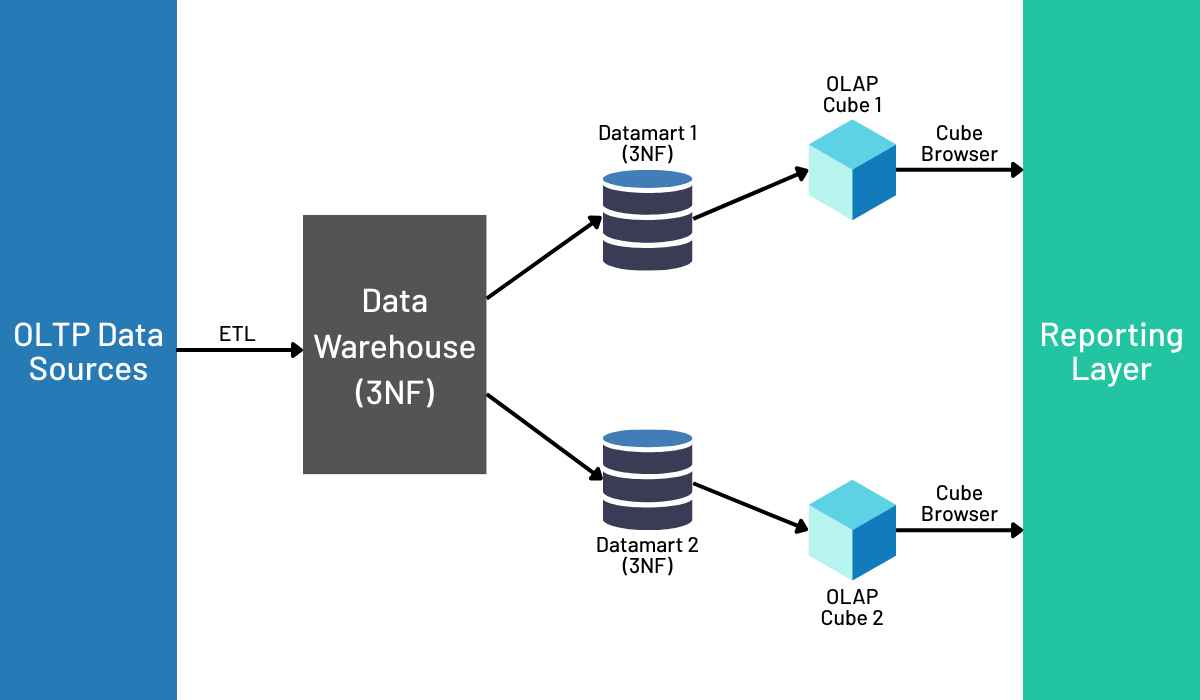
A simple data lake built on HDFS or a basic object store fails to meet Inmon’s rigorous standard because it lacks the structure, governance, and integrity guarantees. However, the architecture discussed in this article achieves Inmon’s vision in a modern context. The combination of Ceph’s massively scalable object storage with Delta Lake’s ACID transactions and schema enforcement creates a centralized data repository that is reliable, auditable, and governed. This “Lakehouse” serves the exact same purpose as Inmon’s EDW: it is the single, integrated source of truth for the enterprise. It delivers on the goals of stability and data consistency but does so on a more flexible, cost-effective, and immensely scalable open source foundation.
Achieving Kimball’s Performance Goals: Dimensional Concepts in the Gold Layer
While Inmon focused on centralized integrity, Ralph Kimball’s approach was relentlessly focused on the needs of the business user and analytical performance. Kimball championed the use of dimensional modeling to build data marts that were fast and intuitive to query. His methodology begins with identifying a business process and then designing a star schema, which consists of a central fact table containing quantitative measures and surrounding dimension tables that provide descriptive context. This denormalized structure is explicitly prepared for the “slice-and-dice” style of querying common in business intelligence, delivering superior performance for analytics tools.
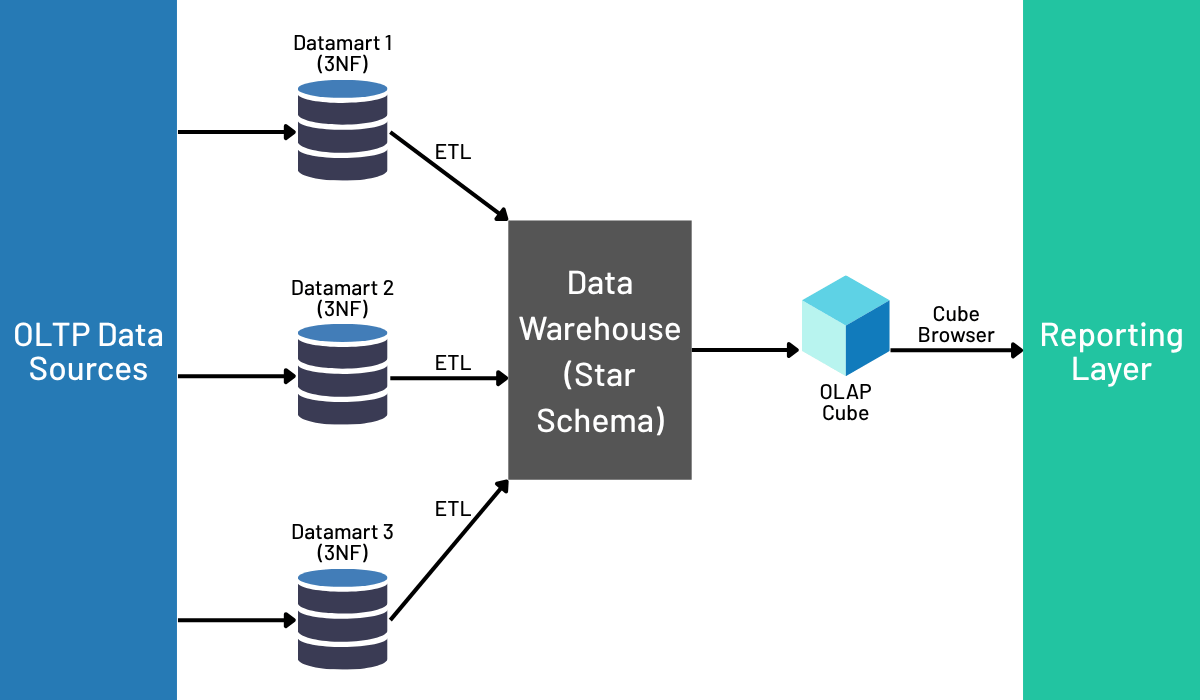
The classic debate in data warehousing was often framed as “Inmon vs. Kimball.” This modern architecture demonstrates that it is not an either/or choice. While the Silver layer of the Lakehouse might store data in a more normalized, integrated form (aligning with Inmon’s principles), the Gold layer is the perfect place to apply Kimball’s dimensional concepts. The final ETL jobs that create the Gold tables can aggregate numerical facts and denormalize data by joining dimensions, creating wide, BI-friendly tables. These tables are tuned for high-performance querying by SQL analytics and BI tools. This allows an organization to benefit from an Inmon-style governed core for integrity and Kimball-style performant data marts for analytics, achieving the best of both worlds.
Martin Kleppmann’s Principles in Practice: Building Reliable Systems from Unreliable Parts
In his seminal work, Designing Data-Intensive Applications, Martin Kleppmann articulates the fundamental principles of modern distributed systems. A core tenet is the concept of fault tolerance: engineering a reliable system from a collection of individually unreliable components. He argues that systems must be designed with the explicit assumption that things will go wrong—hardware will fail, networks will partition, software will have bugs—and must be able to continue operating correctly despite these faults.
The architecture we’ve been talking about is a textbook implementation of Kleppmann’s philosophy. Each of its core open source components is an independent, fault-tolerant distributed system:
- Ceph is designed to withstand drive and even entire node failures, automatically healing itself by re-replicating and rebalancing data to maintain its configured redundancy level.
- Apache Spark’s architecture is inherently fault-tolerant. If an executor node fails mid-computation, the driver program will reschedule the lost tasks on other available executors to ensure the overall job completes successfully.
- Apache Kafka is a partitioned, replicated log system designed for high availability and durability, capable of tolerating broker failures without data loss.
The success of this architecture shows a symbiotic relationship between these open source software systems and the open infrastructure they run on. Distributed systems like Ceph and Spark are designed with the assumption that they can reason about and control their underlying resources—nodes, disks, and network paths—to manage fault tolerance and tune performance.
A traditional, more opaque Platform-as-a-Service (PaaS) or a heavily abstracted virtualized Infrastructure-as-a-Service (IaaS) breaks this symbiosis. It inserts a layer that hides the very details these systems need to operate effectively. For example, Ceph cannot guarantee that data replicas are placed in different physical failure domains (like racks) if it has no visibility into the underlying hardware topology.
A bare metal cloud removes this opaque abstraction layer. It provides the transparent, controllable environment that these open source systems were designed to use. The open software becomes more effective on open infrastructure, and the value of that infrastructure is best realized by software that can take advantage of its transparency and control.
The OpenMetal Advantage in Practice
While it is theoretically possible to assemble this architecture on various platforms, OpenMetal’s offerings create an environment where it is simpler, more performant, and more cost-effective to build and operate.
- Validated, Purpose-Built Hardware: OpenMetal provides server configurations that have been specifically selected and validated for big data workloads. This includes offering the latest generation high-core-count CPUs, large RAM capacities, and high-performance NVMe drives as standard components, removing the guesswork and risk from hardware procurement.
- High-Performance Networking by Default: The inclusion of 20Gbps private networking as a standard feature is a critical differentiator. In many cloud environments, such high-speed, dedicated networking is a costly add-on. For this architecture, it is a fundamental requirement for the high-volume data movement between the Spark and Ceph clusters.
- A Pure Open-Source Stack: The platform itself is built on open source technologies like OpenStack and Ceph. This ensures there is no vendor lock-in and provides seamless integration with the broader open source data ecosystem, perfectly aligning with the philosophy of the proposed application stack.
- Predictable Cost Model: By offering transparent, resource-based pricing and generous bandwidth allotments, this model helps organizations avoid the “bill shock” that is common with large-scale data operations on public clouds, particularly around unpredictable and often exorbitant data egress fees.
- Expertise and Automation: We’ve built a roadmap for providing Ansible playbooks to automate the deployment of the entire Kafka, Delta Lake, MLflow, and Spark stack. Our commitment to automation dramatically lowers the barrier to entry, simplifying the process of spinning up these powerful but complex systems for rapid proofs-of-concept and production deployments.
Wrapping Up: Building Your ETL Pipeline With OpenMetal
The blueprint to overcoming chronic ETL performance issues and building scalable data platforms is clear. A foundation of bare metal for predictable, uncontended performance; a storage layer of Ceph for massive scalability and resilience; a reliability layer of Delta Lake for transactional integrity and data governance; and a processing engine of Apache Spark for high-speed, parallel transformation.
In the modern era of data-intensive applications, infrastructure can no longer be viewed as a commoditized utility. It is a core component of the data strategy. To build systems that are truly reliable, scalable, and maintainable, as defined by Kleppmann, your engineering teams must have transparency and control from the physical hardware all the way up the software stack.
Through a cohesive architecture of best-in-class open source technologies on a bare metal private cloud, data teams can move beyond fighting infrastructure constraints and begin building the high-value data products that drive their business forward.
Schedule a Consultation
Get a deeper assessment and discuss your unique requirements.
Read More on the OpenMetal Blog