































Introduction
Private Cloud Core clouds come with three nodes comprising the core of the cloud. These nodes are considered control plane nodes, because they run all required OpenStack cloud services.
In the event a control plane node fails, how do you fix it? What preparations can you make prior to a failure event?
This guide explains what you can do to get your cloud back up and running. In addition, preparations can be made to soften the impact a failure like this could have.
How do you know a Control Plane node has failed?
First, you should be sure you have a failed control plane situation. The node or instances hosted on it may be inaccessible due to a variety of reasons. Perhaps Nova’s compute service failed or something similar is going on. If you’re using an OpenMetal Cloud, contact our support via OpenMetal Central to determine if the node actually needs to be replaced.
How do you replace a Control Plane node?
There is no current self-service method for replacing a control plane node. Our OpenMetal support staff will have to assist you with both determining what the failure is and in recovering cloud functionality by replacing the failed node with a new one. Submit a ticket through OpenMetal Central to have our agents look into the issue.
Ceph Storage and Instance Recovery
Regardless of if you’re reading this and you have a failure on your hands or not, it is best to be prepared when it comes to how important data is stored.
Understand that with the way we deployed Ceph to Private Cloud Core clouds, each control plane node is running a Ceph OSD daemon and each Ceph pool is replicated three times, across each OSD. This means you could lose one OSD, and still have your data replicated across the other two.
If your persistent instance data is stored in Ceph, then that data is replicated across each control plane node. Losing a control plane node means any instances on that node will cease to function. However, if those instances have their data stored within Ceph, then the data is not lost because Ceph’s pools are replicated across each control plane node via Ceph OSDs. There is a single Ceph OSD running per drive per control plane node. In this scenario, to recover instances, you can attempt to evacuate them to another node, should that node have enough resources.
Evacuate Instances
If you are in a situation where you must get instances back online as soon as possible, you can try evacuating them to another control plane node. This section explains how to evacuate instances using Horizon.
Prerequisites
- A Horizon account with the admin role
To begin evacuating instances, log in to Horizon with a user that has the admin role. Typically you can use the “admin” account to accomplish this.
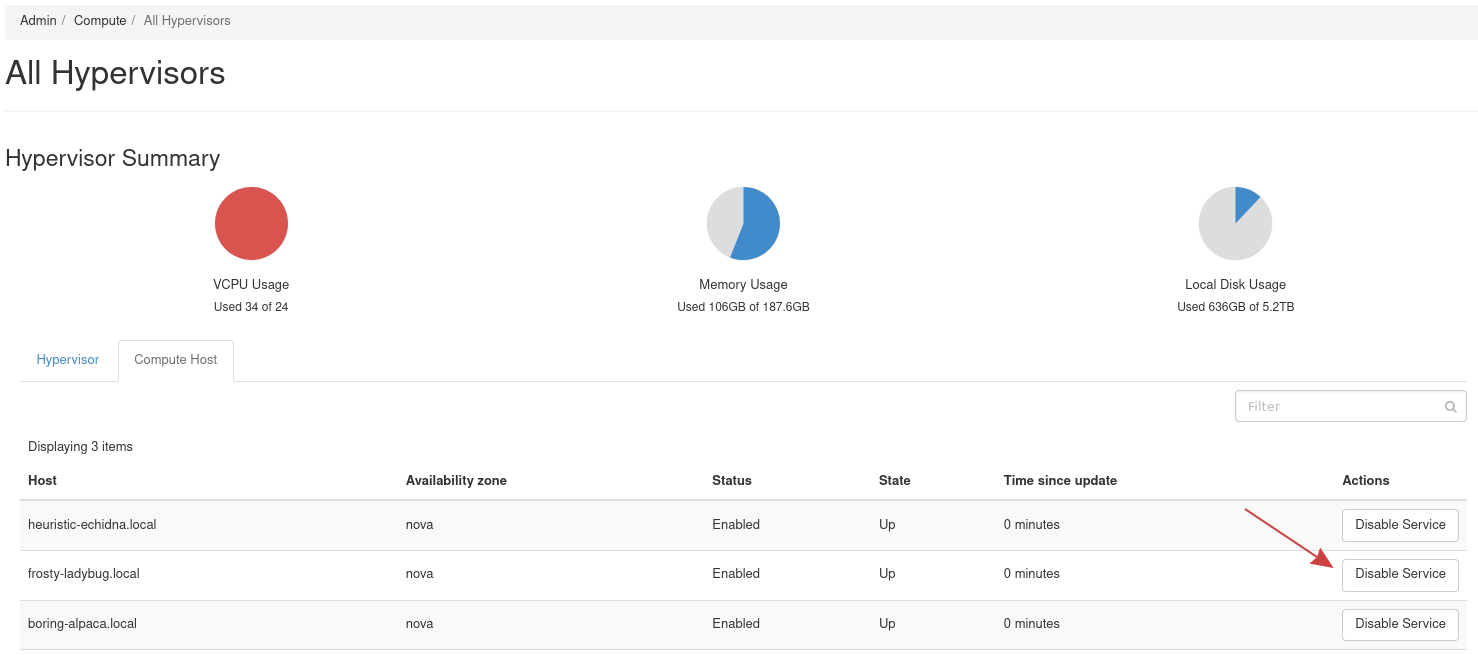
Next, navigate to Admin -> Compute -> All Hypervisors to list hypervisors. From here, click the Compute Host tab to list this cloud’s compute hosts.
To evacuate instances, you must first disable the compute services for the affected host. To do so, find the Actions column to the right and click Disable Service. Upon doing this, a pop up appears allowing to enter a reason for disabling the service. Following that a new drop down will appear allowing you to migrate the instances to a new host called Migrate Host.
Alternatively, if the compute service for the affected host is already down, you will see a button to Evacuate Host under the Actions column on the right.
Conclusion
Should you think you have a failed control plane node, contact our OpenMetal support who will be able to determine if that is the case and also help in restoring cloud functionality.